在AI内容安全领域,传统分类器“依赖标注样本、策略更新繁琐”的痛点长期困扰开发者。OpenAI 正式发布 gpt-oss-safeguard 研究预览版——一款开源权重的安全推理模型,以“自定义策略+可解释推理”为核心,彻底颠覆传统内容分类模式。该模型提供 120B 和 20B 两种规格,基于 Apache 2.0 许可开源,即日起可在 Hugging Face 下载,将 OpenAI 内部核心安全工具“Safety Reasoner”的能力开放给全球开发者。
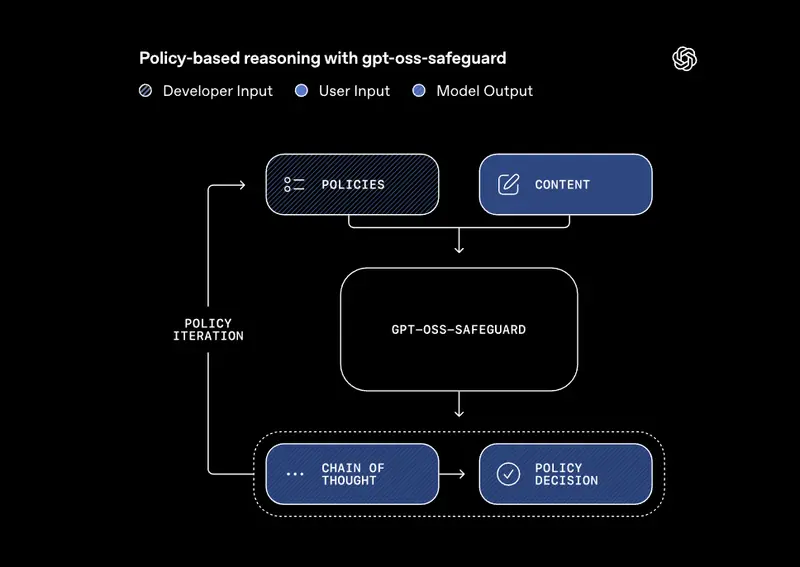
与传统分类器不同,gpt-oss-safeguard 无需依赖海量标注样本,而是直接解析开发者自定义的安全策略,对用户消息、模型回复、完整对话进行分类,并输出可审查的推理过程,在多策略场景下准确率甚至超越 GPT-5-thinking 和 gpt-oss 开源模型。
核心突破:自定义策略+可解释推理,告别传统分类器的僵化
gpt-oss-safeguard 的革命性在于其“以策略为核心”的推理架构,彻底解决了传统内容分类器的三大痛点:
1. 策略自定义,适配任意场景
开发者可直接输入自定义策略(如“识别游戏论坛的作弊讨论”“筛查商品评论的虚假评价”),模型无需重新训练,即可根据策略对内容进行分类。策略在推理阶段动态加载,而非训练时硬编码,支持快速迭代修改,尤其适合:
- 潜在危害快速演变(如新型网络诈骗话术);
- 垂直领域细微规则(如专业平台的内容规范);
- 缺乏足够标注样本的场景。
2. 可解释推理,过程透明可审查
模型输出不仅包含“是否违规”的结论,还附带完整的思维链(chain-of-thought)推理过程,开发者可清晰了解模型如何依据策略判断内容,解决了传统分类器“黑盒决策”的信任问题。这种透明性让安全流程更易审计,也便于开发者优化策略。
3. 多场景兼容,不止于安全分类
除了AI内容安全,gpt-oss-safeguard 还可用于各类场景的内容标注,例如:
- 平台社区的违规内容筛查;
- 产品评论的质量分级;
- 专业领域的内容合规审核。
其输入逻辑简单直接:同时接收“策略文本”和“待分类内容”,输出“分类结论+推理过程”,开发者可灵活集成到自身安全流程中。
与传统分类器的本质区别:从“学习样本”到“理解策略”
传统内容分类器(如 OpenAI Moderation API)的工作逻辑是“通过海量标注样本间接学习策略”——人工整理安全/不安全样本,训练模型识别样本共性,从而推断背后的策略。这种方式虽能实现低延迟、低成本,但存在明显局限:
- 策略更新需重新训练模型,耗时耗力;
- 难以应对未见过的新型风险;
- 缺乏对策略的直接理解,泛化能力弱。
而 gpt-oss-safeguard 采用“直接理解策略+推理判断”的模式,核心优势在于:
- 无需标注样本,策略迭代零成本;
- 可快速适配全新场景,泛化能力强;
- 推理过程可解释,便于调试优化。
简单来说,传统分类器是“记住规则的执行者”,而 gpt-oss-safeguard 是“理解规则的思考者”。
性能表现:多策略准确率超越 GPT-5-thinking,小模型也有大能力
OpenAI 在内部评测与公开基准中对 gpt-oss-safeguard 进行了全面验证,表现亮眼:
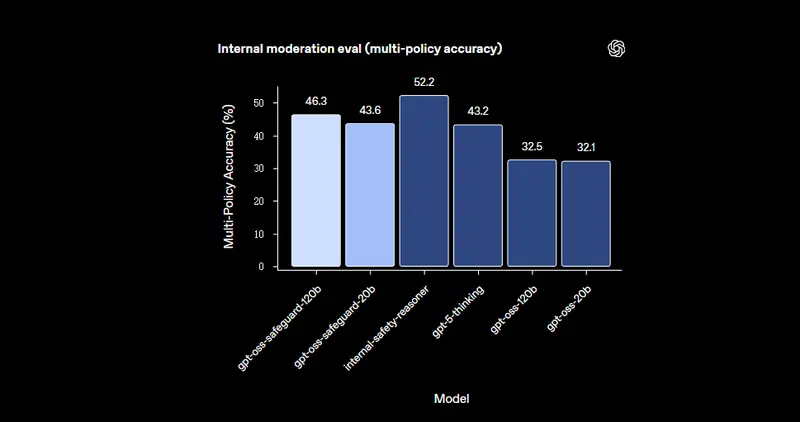
- 内部多策略评测:在“需同时满足多条策略且完全匹配黄金标签”的高难度任务中,gpt-oss-safeguard(含内部 Safety Reasoner)的准确率超越 GPT-5-thinking 和 gpt-oss 开源模型,且 120B/20B 版本以更小体量实现了更优性能,超出预期;
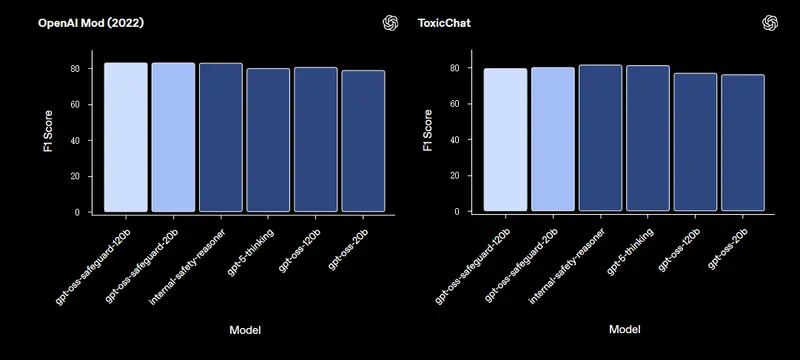
- 2022 Moderation 数据集:使用调整后的内部安全策略测试,gpt-oss-safeguard 略微优于所有被测模型(包括内部 Safety Reasoner 和 GPT-5-thinking),差距无统计显著性;
- ToxicChat 公开基准:采用手写简短策略测试,内部 Safety Reasoner 与 GPT-5-thinking 略优于 gpt-oss-safeguard,但后者凭借更小体量的优势,在部署成本上更具竞争力。
OpenAI 内部实践:Safety Reasoner 成为核心安全组件
gpt-oss-safeguard 并非全新研发,而是 OpenAI 内部安全工具“Safety Reasoner”的开源权重实现。这款工具已深度融入 OpenAI 的安全技术栈,应用场景包括:
- 动态更新安全策略:生产环境中策略迭代时间远短于重新训练分类器,支持“迭代部署”(新模型上线先采用严格策略,后续逐步优化);
- 多产品安全防护:在图像生成、Sora 2 中实时评估输出,阻止不安全内容;在生物、自残等高危领域,与快速分类器配合形成“双层防护”;
- 高算力投入:最近几次发布中,安全推理的总算力占比最高达 16%,足见其在 OpenAI 安全体系中的核心地位。
限制与使用建议
gpt-oss-safeguard 虽表现出色,但仍有两个主要限制,需开发者合理规划使用场景:
- 专用分类器仍有优势:对于可收集数万条高质量标注样本的场景,专用分类器在准确率上可能更优,复杂风险场景建议针对性训练;
- 计算与延迟成本较高:模型推理耗时较长,难以覆盖平台全部内容。建议采用“分层筛选”策略:先用小型快速分类器筛选高风险内容,再用 gpt-oss-safeguard 深度审查;或异步使用,平衡延迟与安全。
社区协作:共建开源安全生态
为推动模型迭代,OpenAI 联合 ROOST 成立 ROOST Model Community(RMC),汇聚安全从业者与研究者,分享模型应用最佳实践、评估结果与反馈。开发者可通过 RMC GitHub 仓库参与协作,共同探索开源 AI 模型在内容安全领域的应用边界。
此次开源,是 OpenAI 首次向社区开放核心安全工具,不仅为开发者提供了灵活高效的内容分类解决方案,更推动了 AI 安全技术的透明化与民主化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...