DFloat11 是一个无损压缩框架,可将大语言模型(LLM)的规模缩小约 30%,同时保持与原始模型完全一致的逐位相同输出。它支持在资源受限的硬件上进行高效的 GPU 推理,且不牺牲准确性。
主要功能
- 无损压缩:DFloat11能够将LLMs的大小减少约30%,同时保持与原始模型完全一致的输出。
- 高效推理:通过定制的GPU内核,DFloat11支持在GPU上快速解压缩,从而实现高效的推理。
- 内存优化:在固定的GPU内存预算下,DFloat11能够支持更长的上下文长度,提升模型的推理能力。
更新
- [2025年5月6日] DFloat11 现已支持 FLUX.1-dev
- 🖼️ 在 VRAM 小于 24GB 的 GPU 上生成惊艳的文本到图像结果 —— 品质无损!
- [2025年5月5日]
dfloat11pip 包已升级至 v0.2.0!运行pip install -U dfloat11[cuda12]升级至最新版本。我们进行了以下重要更新:- 新增对 Qwen 3、Gemma 3 和 Phi 4 的支持!
- GPU 解压缩内核速度提升 20-40%!通过优化线程占用和大量性能改进实现。
- DFloat11 模型现采用 safetensors 格式存储,提升安全性和加载性能。
- 使用 DFloat11 模型时,仅下载压缩模型,不下载原始模型。
工作原理
DFloat11 使用 BFloat16 指数位的霍夫曼编码压缩模型权重,结合硬件优化的算法设计,支持直接在 GPU 上进行高效的即时解压缩。在推理过程中,权重在 GPU 内存中保持压缩状态,仅在矩阵乘法前解压缩,使用后立即丢弃,以最小化内存占用。
- 熵编码:DFloat11分析BFloat16格式的权重分布,发现其指数部分的信息熵远低于其分配的8位。通过霍夫曼编码,DFloat11为权重分配动态长度编码,实现无损压缩。
- GPU内核设计:
- 分解查找表:将单个大型查找表分解为多个紧凑的查找表,存储在GPU的共享内存(SRAM)中,以加快解压缩速度。
- 两阶段内核:第一阶段确定每个线程的读取和写入位置,第二阶段进行实际的解压缩操作,避免了冗余的内存访问。
- 批量解压缩:在Transformer块级别进行解压缩,提高GPU资源利用率,降低推理延迟。
- 解压缩流程:在推理过程中,DFloat11格式的权重矩阵在需要时被即时解压缩为原始的BFloat16格式,用于矩阵乘法运算,之后立即丢弃以节省内存。
主要优势
- 无需 CPU 解压缩或主机到设备的数据传输:所有操作完全在 GPU 上处理。
- 解压缩开销在每次前向传播中恒定,且与批次大小无关,使得 DFloat11 在较大批次时效率更高。
- 比 CPU 卸载方法快得多,适用于内存受限环境的实际部署。
- 在批次大小为 1 时,推理速度约为原始 BF16 模型的 2 倍慢,但随着批次增大,性能差距显著缩小。
- 压缩完全无损,保证模型输出与原始模型逐位相同。
测试结果
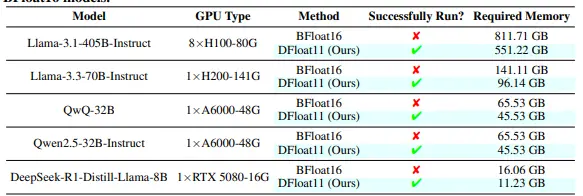
- 压缩效果:DFloat11在多个LLMs上实现了约30%的压缩率,例如Llama-3.1-405B从811.71GB压缩到551.22GB。
- 推理效率:与将部分未压缩模型卸载到CPU相比,DFloat11在单个GPU上的推理吞吐量提高了1.9–38.8倍。
- 内存优化:在固定的GPU内存预算下,DFloat11能够支持比未压缩模型长5.3–13.17倍的上下文长度。
- 无损性验证:DFloat11压缩后的模型在多个标准基准测试中表现出与原始BFloat16模型完全相同的准确性和困惑度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











