字节跳动近日发布了全新的开源代码大语言模型(LLM)系列——Seed-Coder,标志着其在开源大语言模型生态系统中的首次重要贡献。这一系列模型以轻量化和高性能为核心特点,包括基础模型、指令模型和推理模型,规模为8B参数。Seed-Coder不仅展示了通过最少人工干预实现高效代码数据筛选的能力,还以其卓越的性能和透明的设计理念,成为开源社区的一大亮点。
- 项目主页:https://bytedance-seed-coder.github.io
- GitHub:https://github.com/ByteDance-Seed/Seed-Coder
- 模型:https://huggingface.co/collections/ByteDance-Seed/seed-coder-680de32c15ead6555c75b0e4
亮点功能与独特优势
Seed-Coder凭借以下核心特点脱颖而出:
- 以模型为中心的数据筛选
Seed-Coder颠覆了传统依赖手工规则进行数据过滤的方式,转而采用大语言模型自身的评分机制来筛选高质量代码数据。这种自动化方法最大程度减少了人工干预,提高了数据筛选效率,同时也确保了训练数据的质量。 - 透明性与可复现性
字节跳动公开了完整的数据流水线细节,包括GitHub数据、提交记录和代码相关网络数据的筛选流程。这种开放的态度让研究者和开发者能够深入了解模型的构建过程,并在此基础上进行改进或扩展。 - 强大的多任务性能
在多种编码任务中,Seed-Coder展现出超越其他同等规模开源模型的表现,甚至在部分基准测试中优于更大规模的模型。无论是代码生成、补全、编辑还是复杂的代码推理任务,Seed-Coder都表现出色。

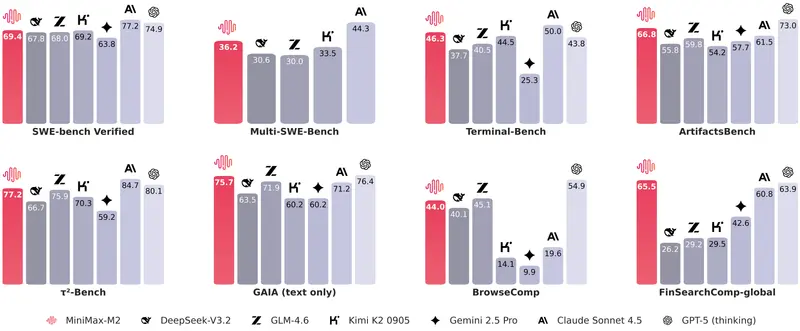
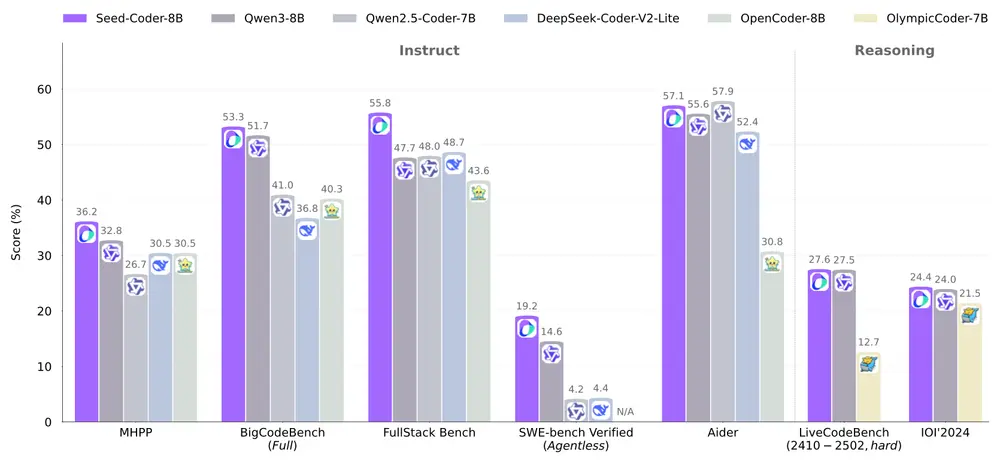
性能表现:多项基准测试中的佼佼者
Seed-Coder在多个权威编码基准测试中取得了优异成绩,具体表现如下:
- 代码生成
在HumanEval和MBPP等代码生成基准测试中,Seed-Coder-8B-Base的表现超越了其他类似规模的开源模型,甚至接近一些更大规模的闭源模型。 - 代码补全
在CrossCodeEval和RepoEval等代码补全基准测试中,Seed-Coder-8B-Base显著优于竞争对手,能够根据上下文精准预测并补全代码片段。 - 代码推理
在CRUXEval和MHPP等复杂代码推理任务中,Seed-Coder-8B-Instruct展现了强大的逻辑理解能力,尤其擅长解决高难度编程问题。 - 软件工程任务
在SWE-bench和Multi-SWE-bench等实际开发场景中,Seed-Coder-8B-Instruct表现出卓越的实用性,能够帮助开发者完成代码调试、优化等任务。
值得一提的是,尽管Seed-Coder的规模仅为8B参数,但其性能却足以媲美甚至超越一些更大规模的模型,这体现了其高效的模型设计和数据筛选策略。
主要功能与应用场景
Seed-Coder具备以下主要功能,适用于多种开发场景:
- 代码生成:能够根据自然语言描述生成高质量的代码片段,支持从简单脚本到复杂算法的多样化需求。
- 代码补全:根据上下文自动补全代码,提高开发效率,减少手动输入错误。
- 代码编辑:根据用户指令对现有代码进行修改,如重构、优化或添加新功能。
- 代码推理:理解代码逻辑并解决复杂问题,如修复漏洞、优化性能或分析潜在风险。
- 软件工程任务:帮助开发者完成实际开发中的各种任务,例如代码调试、性能优化和文档生成。
主要特点:灵活、高效、可扩展
除了卓越的性能,Seed-Coder还具备以下突出特点:
- 自动化数据筛选:通过模型自身的评分机制,自动筛选高质量代码数据,减少人工干预,提升数据质量。
- 多语言支持:支持多种编程语言,包括Python、Java、C++等,能够满足不同开发者的多样化需求。
- 长文本处理能力:支持长达32K标记的长文本训练,能够处理复杂的代码结构和大型项目。
- 可扩展性:设计了灵活的数据管道,支持增量数据扩展和动态调整,方便未来模型的升级和优化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











