
OpenAI 今日正式发布两款开放权重语言模型:gpt-oss-120b 和 gpt-oss-20b。
这是自 GPT-2 以来,OpenAI 首次向公众开放其语言模型权重,标志着公司在开放性与透明度上的重大转变。
- GitHub:https://github.com/openai/gpt-oss
- 模型:https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4
- 试用:https://www.gpt-oss.com
- 官方介绍:https://openai.com/open-models
这两款模型并非实验性项目,而是基于 OpenAI 当前最先进的训练技术构建,性能媲美甚至超越同级别闭源模型,在推理、工具使用与现实部署效率方面表现突出。
更重要的是,它们采用 Apache 2.0 许可证,允许自由使用、修改与商业部署。
为什么现在发布开源模型?
过去几年,尽管 OpenAI 以闭源方式推动了大模型能力的边界,但社区始终期待其在开放生态中扮演更积极角色。
此次发布的 gpt-oss 系列,正是对这一需求的回应:
- 为研究者提供可审计的模型,推动对齐、安全与推理机制的研究;
- 让开发者在本地运行高性能模型,保障数据隐私与控制权;
- 降低全球创新门槛,使资源受限的团队也能获得顶级模型能力。
正如 OpenAI 所强调:
“健康的开放模型生态系统,是实现广泛可及、普惠 AI 的关键一环。”
模型能力:小尺寸,大能量
🔹 gpt-oss-120b:接近 o4-mini 的推理强者
- 总参数:117B(激活 5.1B/token,MoE 架构)
- 推理性能:在多项任务上与 o4-mini 持平甚至超越
- 部署要求:可在单块 80GB GPU 上高效运行
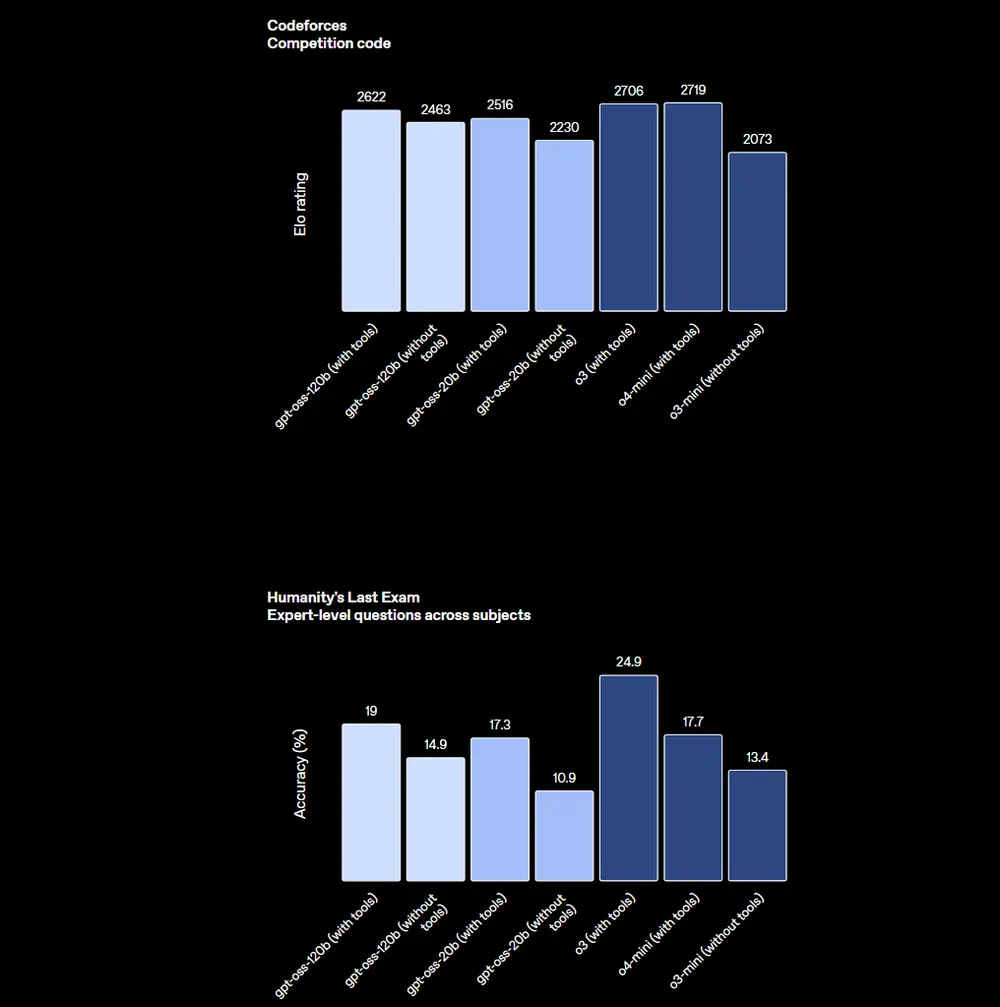
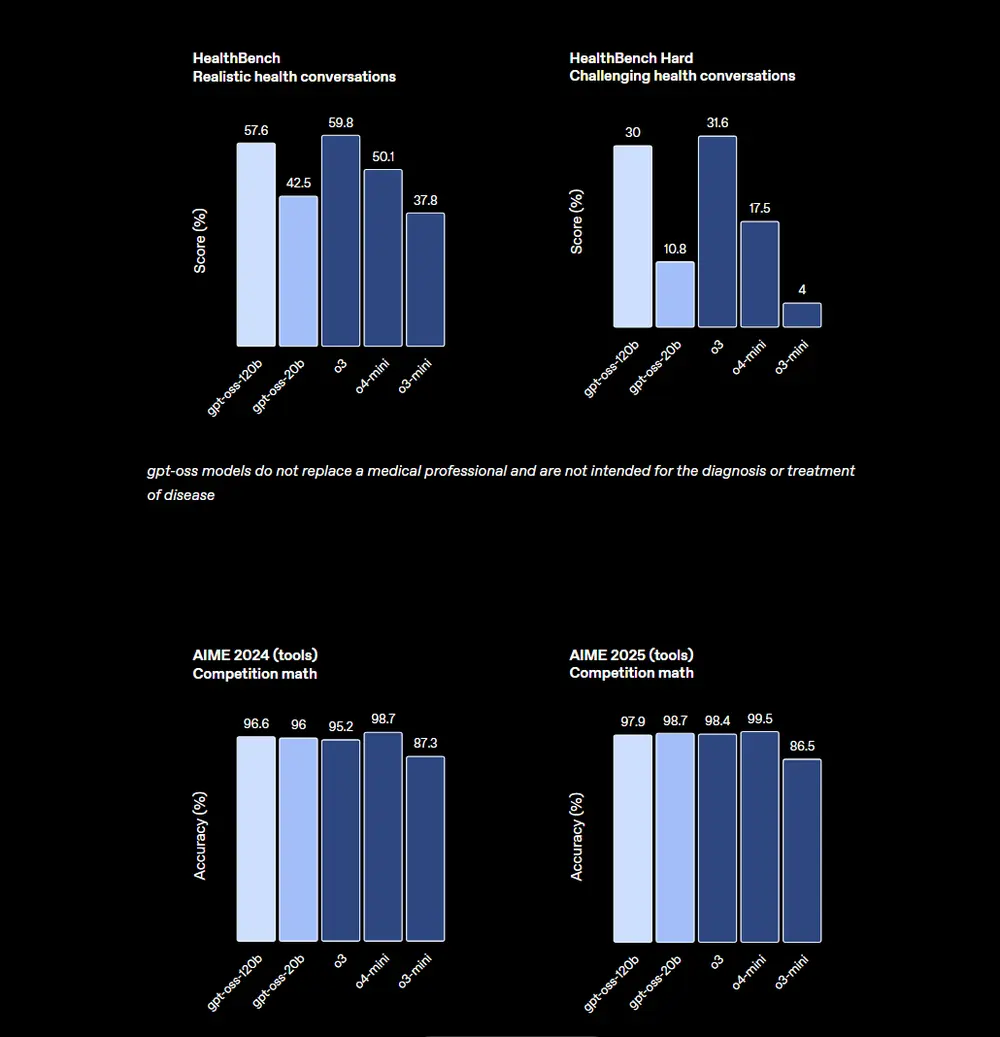
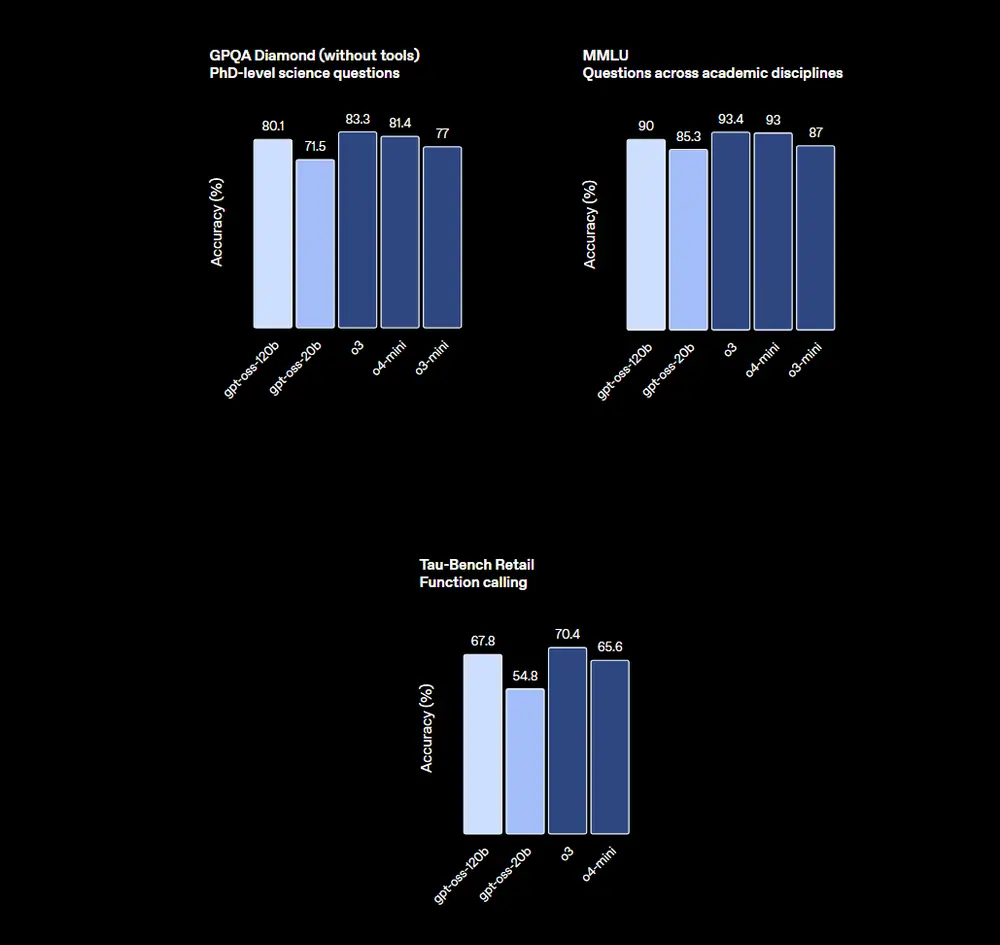
在核心评估中:
- HealthBench:优于 o1 和 GPT-4o
- AIME 2024/2025 数学竞赛:超越 o4-mini
- TauBench 代理评估:工具调用与 CoT 推理表现优异
- Codeforces 编码竞赛:显著优于 o3-mini
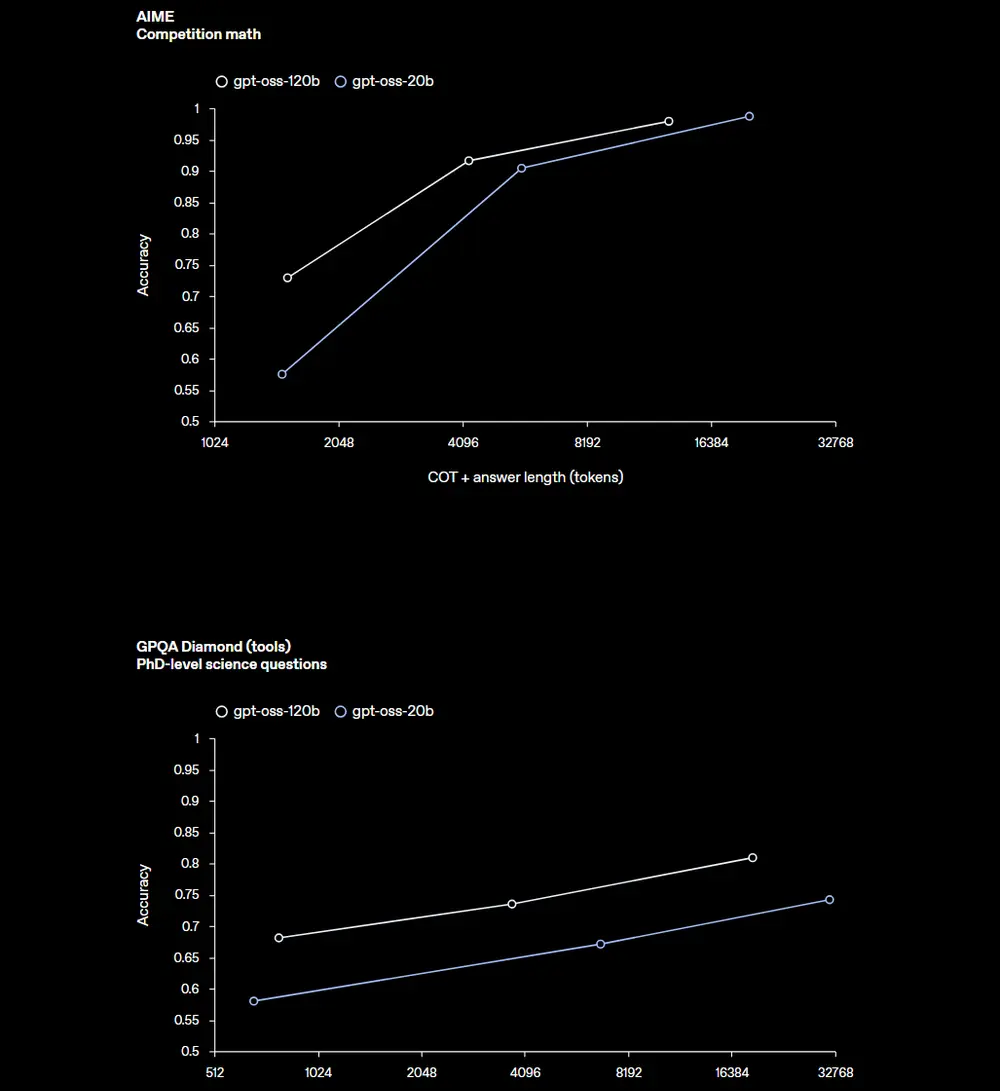
🔹 gpt-oss-20b:边缘设备上的全能选手
- 总参数:21B(激活 3.6B/token)
- 推理性能:与 o3-mini 相当
- 部署要求:仅需 16GB 内存,可在消费级设备运行
适用于:
- 本地开发环境
- 移动端或嵌入式设备推理
- 快速迭代与私有化部署场景
尽管规模较小,它在竞赛数学、健康问答等任务上仍展现出惊人潜力,甚至在某些指标上反超 o3-mini。

技术架构:为效率与现实部署而生
gpt-oss 系列采用先进架构设计,兼顾性能与实用性:
- 混合专家(MoE)架构:大幅减少每 token 的激活参数,提升推理效率
- 交替密集与局部带状稀疏注意力:类似 GPT-3 的高效注意力模式
- 分组多查询注意力(GQA):分组大小为 8,优化内存占用
- 旋转位置编码(RoPE):原生支持高达 128k 上下文长度
- 分词器开源:使用
o200k_harmony分词器(GPT-4o 与 o4-mini 的超集),现已在 Hugging Face 开源
训练数据聚焦于:
- STEM 领域
- 编程与算法
- 通用知识
- 以英语为主,未包含多模态内容
后训练:与闭源模型共享技术栈
gpt-oss 模型的后训练流程与 o4-mini 高度一致,包含:
- 监督微调(SFT)
- 高强度强化学习(RL)
目标是让模型:
- 在生成答案前进行 链式推理(Chain-of-Thought, CoT)
- 主动调用工具(如代码执行、网页搜索)
- 与 OpenAI Model Spec 对齐
此外,模型支持三种推理力度(低、中、高),开发者可通过系统消息灵活控制延迟与性能的权衡。
关键设计原则:不监督 CoT,以便监控
一个值得关注的技术决策是:
gpt-oss 系列未对链式推理(CoT)进行直接监督对齐。
这一做法延续自 o1-preview 的设计理念。OpenAI 认为:
- 如果 CoT 被直接监督,攻击者可能绕过安全机制,生成“看似合理”的有害推理;
- 保留原始、未对齐的 CoT 输出,有助于开发者构建自己的监控系统,检测幻觉、欺骗或滥用行为。
⚠️ 但 OpenAI 明确提醒:
开发者不应将 CoT 内容直接展示给用户。
它可能包含幻觉、不安全语言或模型被禁止输出的信息。
安全是底线:从训练到对抗性评估
OpenAI 将安全视为开源模型发布的首要原则。
训练阶段的安全措施:
- 预训练时过滤 CBRN(化学、生物、放射性、核)相关有害数据
- 后训练中采用 审议对齐(Deliberation Alignment) 与 指令层次(Instruction Hierarchy),强化模型拒绝不安全请求的能力
发布前的对抗性评估:
为评估模型被恶意微调的风险,OpenAI 主动进行了“最坏情况”测试:
- 在生物学与网络安全领域对模型进行对抗性微调
- 模拟攻击者行为,尝试去除模型的拒绝能力
- 使用 Preparedness Framework 评估其能力上限
结果表明:即使使用 OpenAI 最先进的训练栈,这些微调后的模型也无法达到高风险能力水平。
该方法已由三个独立专家小组审查,并推动了训练与评估流程的改进。详细内容见《安全论文》与模型卡。
红队挑战:邀请全球共同提升安全性
为促进更安全的开源生态,OpenAI 同时启动 红队挑战(Red Teaming Challenge):
- 奖金池:50 万美元
- 参与者:全球研究人员、开发者、安全专家
- 目标:发现 gpt-oss 模型的新安全问题
- 评审:由 OpenAI 及其他领先实验室专家组成
挑战结束后,OpenAI 将:
- 发布综合报告
- 开源基于发现构建的评估数据集
此举旨在让整个社区能立即受益于最新安全研究成果。
如何使用?全面兼容主流生态
gpt-oss 模型已全面接入主流部署平台,确保广泛可访问性。
✅ 模型获取
- 权重已发布于 Hugging Face
- 支持 MXFP4 原生量化
- 免费下载,Apache 2.0 许可
✅ 部署支持
合作平台包括:
- 云服务:Azure、AWS、Databricks、Baseten、Fireworks、Together AI
- 推理引擎:vLLM、llama.cpp、Ollama、LM Studio
- CDN 与边缘:Cloudflare、Vercel
- 硬件厂商:NVIDIA、AMD、Cerebras、Groq
✅ 本地运行
- 提供 PyTorch 与 Apple Metal 的参考实现
- 支持 macOS、Linux、Windows
- 微软已将 gpt-oss-20b 优化版本引入 Windows 设备,通过 ONNX Runtime 支持本地推理,可在 VS Code AI Toolkit 中使用
✅ 开发工具
- 开源 harmony 提示格式渲染器(Python & Rust)
- 提供示例工具集(代码执行、搜索等)
- 支持 Structured Outputs 与 Responses API(适用于代理工作流)
为何开放模型至关重要?
OpenAI 表示,发布 gpt-oss 系列不仅是为了技术展示,更是为了推动更广泛的社会价值:
- 降低创新门槛:使初创公司、学术机构、发展中国家团队也能获得顶级模型能力
- 增强透明度与信任:允许外部审查模型行为与训练方法
- 促进安全研究:为对齐、监控、防御机制提供真实研究对象
- 构建民主化 AI 基础设施:让 AI 发展不被少数闭源系统垄断
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











