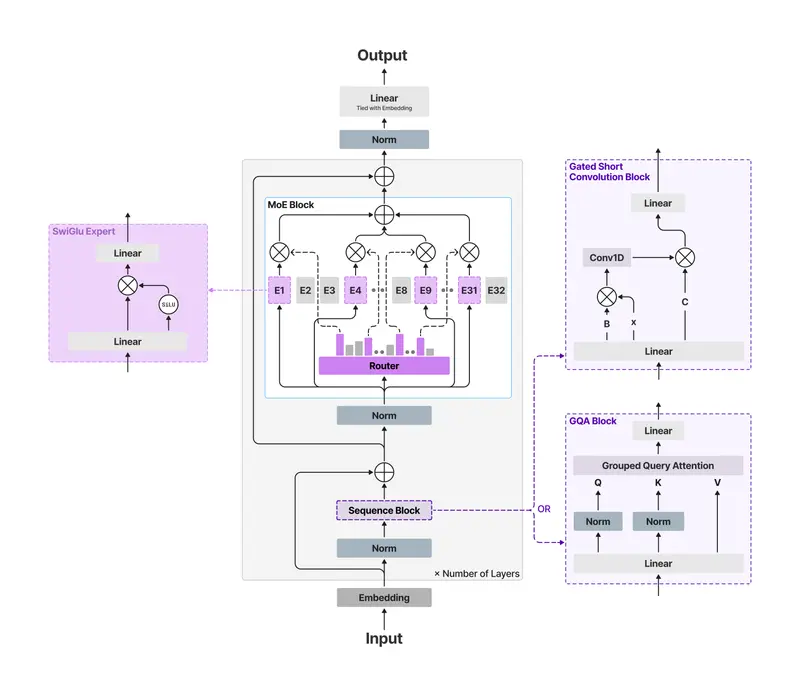
Intelligent Internet(II)正式推出两款专注于信息检索与复杂推理的开源语言模型:
- II-Search-4B:面向多跳检索与事实验证的高效4B级模型
- II-Search-CIR 4B:引入代码集成推理(Code-Integrated Reasoning, CIR)的新范式,提升外部工具调用的灵活性与控制力
这两款模型均基于 Qwen3-4B 微调,在多个信息检索基准测试中超越同规模甚至更大模型,展现出卓越的事实准确性与任务完成能力。
- II-Search-4B:https://huggingface.co/Intelligent-Internet/II-Search-4B
- II-Search-CIR 4B:https://huggingface.co/Intelligent-Internet/II-Search-CIR-4B
一、II-Search-4B:专为信息检索优化的4B模型
模型概述
II-Search-4B 是一款参数量为 40亿 的语言模型,基于 Qwen3-4B 架构,针对信息检索、多跳推理和网页集成搜索任务进行了深度微调。
它在以下任务中表现尤为突出:
- 多跳问答(Multi-hop QA)
- 事实验证(Fact Verification)
- 研究辅助与综合报告生成
- 基于证据的推理(Evidence-based Reasoning)
目标是让小模型也能完成复杂、需多步外部查询的任务。
核心能力
| 能力 | 说明 |
|---|---|
| 🔍 增强的网页搜索 | 高效调用搜索API,精准提取关键信息 |
| 🧠 多跳推理 | 支持跨多个来源的逻辑推导,解决复杂问题 |
| ✅ 交叉验证机制 | 对比多个结果源,提升答案可靠性 |
| 📄 报告生成 | 受 STORM 启发,可输出结构化研究摘要 |
| ⚙️ 工具使用优化 | 在合理成本下实现高效工具调用 |
训练流程:四阶段渐进式优化
阶段 1:工具调用能力激发(Distillation)
使用更大模型(如 Qwen3-235B)在多跳数据集上生成带有函数调用的推理路径,通过知识蒸馏为小模型注入基础工具使用能力。
阶段 2:推理能力增强
针对初始模型推理路径短、跳跃性强的问题,引入:
- 受随机游走启发的合成问题:构造需要更多推理轮次的长链任务
- 改进的思维链模式:引导模型生成更清晰、更结构化的推理过程
阶段 3:拒绝采样与报告生成优化
- 过滤低质量轨迹,仅保留“正确答案 + 合理推理”的样本
- 引入类似 STORM 的技术,训练模型生成连贯、全面的研究报告
阶段 4:强化学习精调
- 使用 dgslibisey/MuSiQue 数据集进行 RL 训练
- 结合内部搜索数据库(维基数据、Fineweb、ArXiv)增强现实场景覆盖
- 通过奖励机制优化检索效率与答案准确性
性能表现:全面领先同级模型
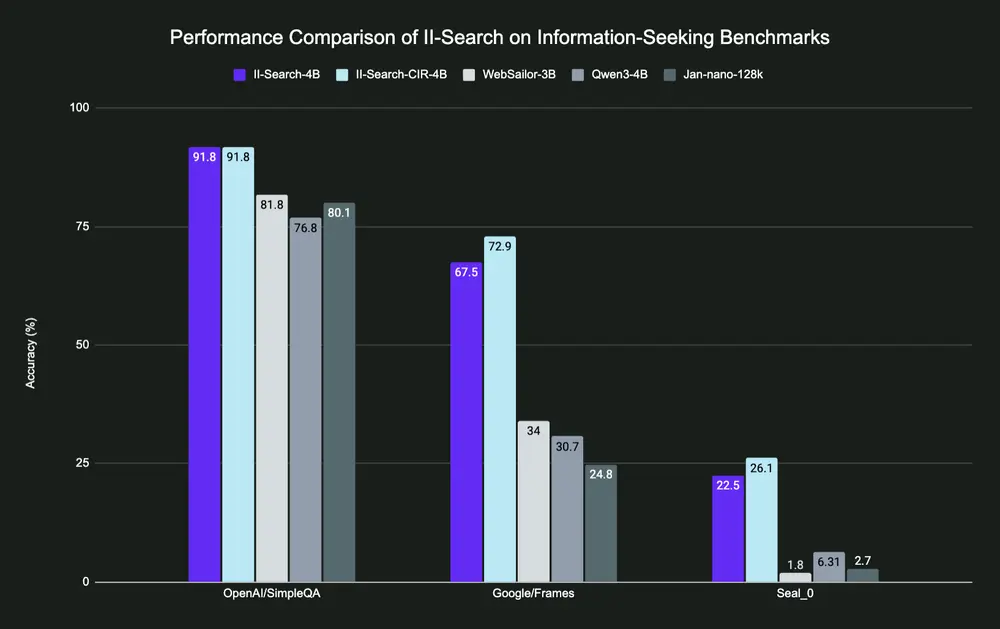
在多个权威基准测试中,II-Search-4B 显著优于同类模型:
| 基准测试 | Qwen3-4B | Jan-4B | WebSailor-3B | II-Search-4B |
|---|---|---|---|---|
| OpenAI/SimpleQA | 76.8 | 80.1 | 81.8 | 91.8 ✅ |
| Google/Frames | 30.7 | 24.8 | 34.0 | 67.5 ✅ |
| Seal_0 | 6.31 | 2.7 | 1.8 | 22.5 ✅ |
✅ 在 Google/Frames 上提升超过 33 个百分点,体现其强大的多跳推理能力
工具使用效率对比(SerpDev)
| 指标 | Qwen3-4B | Jan-4B | WebSailor-3B | II-Search-4B |
|---|---|---|---|---|
| # 搜索次数 | 1.0 | 0.9 | 2.1 | 2.2 |
| # 页面访问次数 | 0.1 | 1.9 | 6.4 | 3.5 |
| # 总工具调用 | 1.1 | 2.8 | 8.5 | 5.7 |
II-Search-4B 在保持较高工具调用频率的同时,避免了过度访问(如 WebSailor 的 6.4 次访问),实现了效率与准确性的平衡。
适用场景
II-Search-4B 特别适用于:
- 教育与科研中的事实核查
- 新闻内容的真实性验证
- 自动化市场调研与竞品分析
- 需要高准确率的问答系统
二、II-Search-CIR 4B:引入代码集成推理(CIR)
模型背景
受 II-Researcher 方法启发(在 DeepSeek-R1 上增强推理能力),我们提出 代码集成推理(Code-Integrated Reasoning, CIR)——一种将代码执行与外部工具调用深度融合的新型推理范式。
与传统“工具调用”不同,CIR 允许模型在代码块中编程式地组织搜索、过滤和逻辑判断,从而实现更精细的控制与更复杂的操作。
什么是代码集成推理?
支持的预定义函数:
web_search(query: str, num_result: int):执行网络搜索web_visit(url: str):访问指定网页并提取内容
这些函数作为外部资源接口,但由模型在代码中主动调用、组合与处理。
为什么需要 CIR?
传统工具调用存在局限:
- 模型难以控制调用顺序与条件逻辑
- 缺乏中间数据处理能力(如过滤、排序)
- 容易陷入“盲目调用”或“依赖内部知识”
CIR 的优势在于:
✅ 结构化控制流:支持 if/for/while 等逻辑
✅ 中间状态管理:可在代码中保存、处理检索结果
✅ 可调试性更强:代码块便于审查与验证
✅ 更接近人类研究员的工作方式
训练方法
1. SFT 微调阶段
为解决大模型也难以稳定生成代码格式的问题,我们首先构建高质量 SFT 数据集,并在 Qwen3-4B 上进行监督微调:
- 最大长度:26,000 tokens
- 批次大小:128
- 学习率:1e-5
- 训练轮数:4
2. 强化学习阶段(DAPO)
在硬推理数据集上进一步优化,提升复杂任务表现:
- 最大提示长度:3,000
- 最大响应长度:16,384
- 总上下文长度:32,768(支持超长推理链)
- 每个提示生成 16 个响应,vLLM 批量展开
- 学习率:1e-6,预热 20 步
- 梯度裁剪:1.0,损失按 token 均值聚合
该设置确保模型能在长上下文中稳定生成有效代码并完成任务。
性能对比:CIR 再进一步
| 基准测试 | Qwen3-4B | Jan-4B | WebSailor-3B | II-Search-4B | II-Search-CIR-4B |
|---|---|---|---|---|---|
| OpenAI/SimpleQA | 76.8 | 80.1 | 81.8 | 91.8 | 91.8 |
| Google/Frames | 30.7 | 24.8 | 34.0 | 67.5 | 72.2 ✅ |
| Seal_0 | 6.31 | 2.7 | 1.8 | 22.5 | 26.4 ✅ |
🔺 在 Google/Frames 上提升 4.7 分,Seal_0 提升 3.9 分,体现 CIR 在复杂推理中的优势
📌 注:评估过程中,MCP 机制确保 II-Search-CIR-4B 不访问 Hugging Face 的任何 URL,避免信息泄露。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











