
Prime Intellect发布 INTELLECT-2,这是首个通过全球分布式强化学习训练的 32B 参数模型。与传统的集中式训练不同,INTELLECT-2 使用完全异步的强化学习(RL),在一个动态、异构的无许可计算贡献者群体中训练推理语言模型。
- 模型:https://huggingface.co/collections/PrimeIntellect/intellect-2-68205b03343a82eabc802dc2
- PRIME-RL:https://github.com/PrimeIntellect-ai/prime-rl
为了实现这一独特基础设施的训练,Prime Intellect从头构建了多个组件:引入了 PRIME-RL,这是一个专为分布式异步强化学习设计的训练框架,基于新型组件,如 TOPLOC(验证不受信任推理工作者的输出)和 SHARDCAST(高效地将策略权重从训练节点广播到推理工作者)。

除了基础设施组件外,Prime Intellect对标准的 GRPO 训练配方和数据过滤技术进行了修改,这些修改对于实现训练稳定性并确保模型成功学习其训练目标至关重要,从而改进了 QwQ-32B。
去中心化训练的范式转变
通过强化学习实现测试时计算扩展已成为大型语言模型(LLM)的新扩展轴,通过允许模型花费更多时间推理来实现性能提升。
然而,强化学习训练通常是集中式的,需要大量协同定位的 GPU 和高速互联网络。借助 INTELLECT-2,我们展示了范式转变:强化学习本质上更异步,非常适合去中心化、全球分布式的计算。
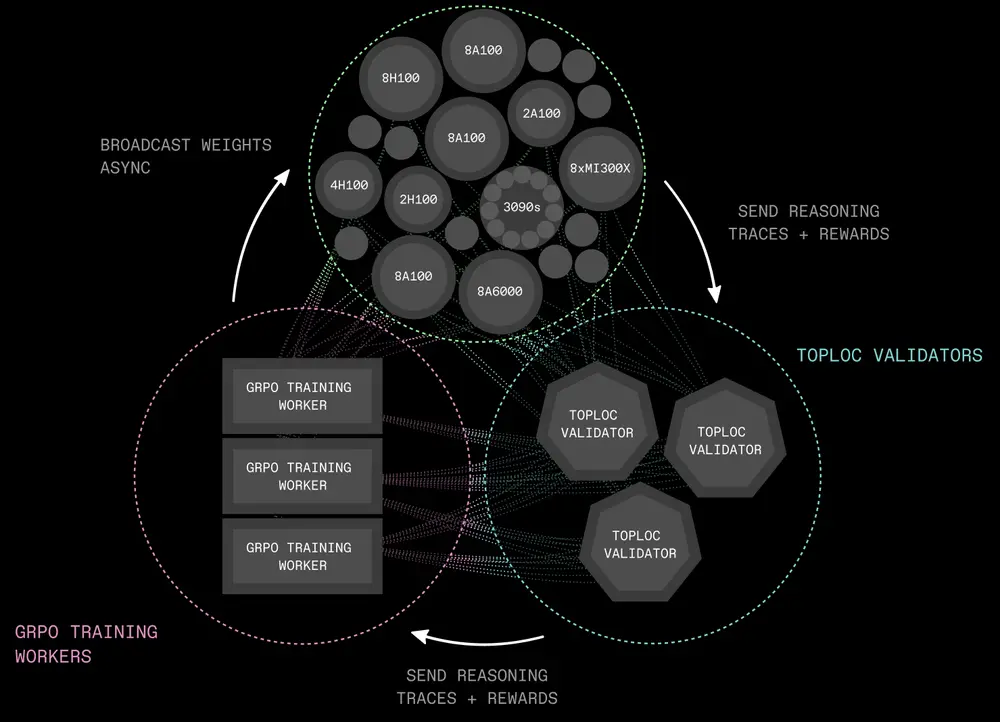
训练基础设施
我们为训练 INTELLECT-2 引入了以下关键开源基础设施组件:
- PRIME-RL:
- 专为去中心化训练设计的完全异步强化学习框架。解耦了输出生成、模型训练和权重广播。支持在异构、不可靠网络上进行训练。
- 训练器实现使用 PyTorch FSDP2,推理使用 vLLM,验证器使用 SYNTHETIC-1 中引入的 GENESYS 架构。
- SHARDCAST:
- 一个基于 HTTP 的树形拓扑网络库,用于高效地将更新的模型权重传播到去中心化的推理工作者。
- TOPLOC:
- 一种局部敏感哈希方案,用于高效的可验证推理。能够检测模型推理中的篡改或精度变化,在非确定性 GPU 硬件上可靠运行。
- 推理工作者生成输出文件,通过签名 URL 上传,链上事件触发 TOPLOC 验证器检查;接受的文件用于训练器,而无效文件将提交节点从池中移除并惩罚。
- 协议测试网:
- 提供基础设施以聚合和协调全球计算资源。
- 基于 Rust 的编排器和发现服务协调无许可工作者——节点通过硬件检查、心跳检测和拉取 Docker 容器任务自动注册,编排器调度工作负载、跟踪健康状态并记录池所有权和贡献。
训练配方
- 训练数据与奖励:
- 来自 NuminaMath-1.5、Deepscaler 和 SYNTHETIC-1 的 285k 个可验证任务(数学和编码)。
- 二元任务奖励 + 长度奖励,允许用户在推理时预算思考令牌。
- 两步异步 RL:
- 新策略权重的广播与持续进行的推理和训练完全重叠,消除了通信瓶颈。
- 双侧 GRPO 剪切:
- 通过双侧令牌概率比率剪切缓解梯度尖峰,稳定训练。
- 激进的梯度剪切:
- 解决大规模训练中梯度范数的激增问题,提供更好的训练稳定性。
实验
我们报告了两个主要实验的结果:TARGET-SHORT,一个以短目标长度为目标的实验运行,训练高效推理模型;以及 TARGET-LONG,我们的主要运行,目标长度更长。
- 计算利用率:
- 在两个主要实验中,我们通过两步异步强化学习成功实现了通信与计算的重叠。
- 奖励轨迹:
- 在训练过程中,我们的任务奖励显著提高,表明模型在数学和编码问题上的性能有所提升。我们还观察到长度惩罚的减少,但比消融实验中慢得多。
- 基准性能:
- 我们提高了 QwQ-32B 在数学和编码基准测试中的性能。
- 总体而言,由于 QwQ-32B 已通过 RL 进行了广泛训练,很难在训练数据集之外的基准测试上获得大幅的泛化改进。要实现更显著的改进,可能需要更好的基础模型(如现已可用的 Qwen3)或更高质量的数据集和 RL 环境。
未来工作
INTELLECT-2 是朝去中心化训练开放前沿推理模型迈出的第一步。在未来几个月,我们将致力于:
- 增加推理与训练计算的比例:推理具有极高的并行性和无通信特性,因此更复杂的 RL 环境,分配更多 FLOPs 给推理,是去中心化训练的天然选择。
- 工具调用与多轮 RL:为充分利用推理时计算推动科学和研究进步,我们需要为模型的推理链内置工具——网络搜索、Python 解释器等。
- 众包 RL 任务与环境:我们相信开源在这里具有独特优势。分布式 RL 仍处于早期阶段,通过合适的社区和贡献,开源 AI 有望超越封闭实验室。
- 模型合并与 DiLoCo:通过 DiLoCo 或在训练结束时融合独立训练的 RL 模型,创建单一统一模型,将去中心化 RL 扩展到更多计算。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











