
微软近期推出的rStar2-Agent,以14亿参数的轻量化规模,在数学推理领域实现了突破性进展——它未依赖更长的推理时间,而是通过更智能的思考逻辑,达到了与671亿参数的DeepSeek-R1相当的性能,且这一成果完全基于代理强化学习技术实现。
不同于传统模型单纯靠参数规模“堆性能”的路径,rStar2-Agent具备更接近人类的问题解决逻辑:能够自主规划推理步骤、调用编码工具,还能根据工具反馈验证思路、反思优化,最终高效解决复杂数学问题。而支撑这些核心能力的,是微软团队打造的三大关键创新技术。
三大核心创新:撑起轻量化模型的“强推理”能力
rStar2-Agent的突破并非偶然,而是建立在算法、基础设施、训练方法三大维度的协同创新之上,三者共同解决了“轻量化模型如何高效实现复杂推理”的核心问题。
1. GRPO-RoC算法:让推理更“精准”,减少无效探索
作为高效的代理强化学习算法,GRPO-RoC的核心亮点是“正确时重采样”(Resample-on-Correct)策略。在模型调用编码工具解决问题时,它会选择性保留高质量的正向推理轨迹(即能正确推进问题解决的思路和操作),同时完整保留所有失败案例——前者帮助模型强化有效推理路径,后者则让模型避开常见错误,最终实现“更短、更智能”的推理过程,避免传统模型反复试错的低效问题。
2. 高吞吐量RL基础设施:降低训练成本,适配有限资源
代理强化学习的一大痛点是“rollout(轨迹采样)成本高”,尤其是需要频繁调用编码工具时,算力消耗会大幅增加。微软为此搭建了可扩展的强化学习基础设施,能支持高吞吐量的工具调用执行,直接减轻了训练过程中的算力负担。最终,rStar2-Agent仅用64个MI300X GPU,就完成了从预训练模型到顶尖性能的迭代,大幅降低了大模型推理任务的资源门槛。
3. 多阶段代理训练方法:循序渐进,高效提升能力
不同于“一步到位”的训练模式,rStar2-Agent采用了“从易到难”的多阶段训练路径:
- 第一步:从非推理监督微调(SFT) 起步,让模型先掌握基础的问题理解和工具使用能力;
- 第二步:进入多阶段强化学习,每阶段逐步提升数据集难度,同时严格限制最大响应长度——这一设计既避免了模型“冗长无效的推理”,又能让模型在每阶段专注突破对应难度的问题,最终实现能力的高效跃迁。
核心功能:不止于“算题”,更具备“自主解决问题”的能力
rStar2-Agent的价值不仅在于“数学推理准确率高”,更在于它展现出的“类人类认知”功能,让模型从“被动计算”转向“主动解决问题”。
1. 高精度数学问题解决
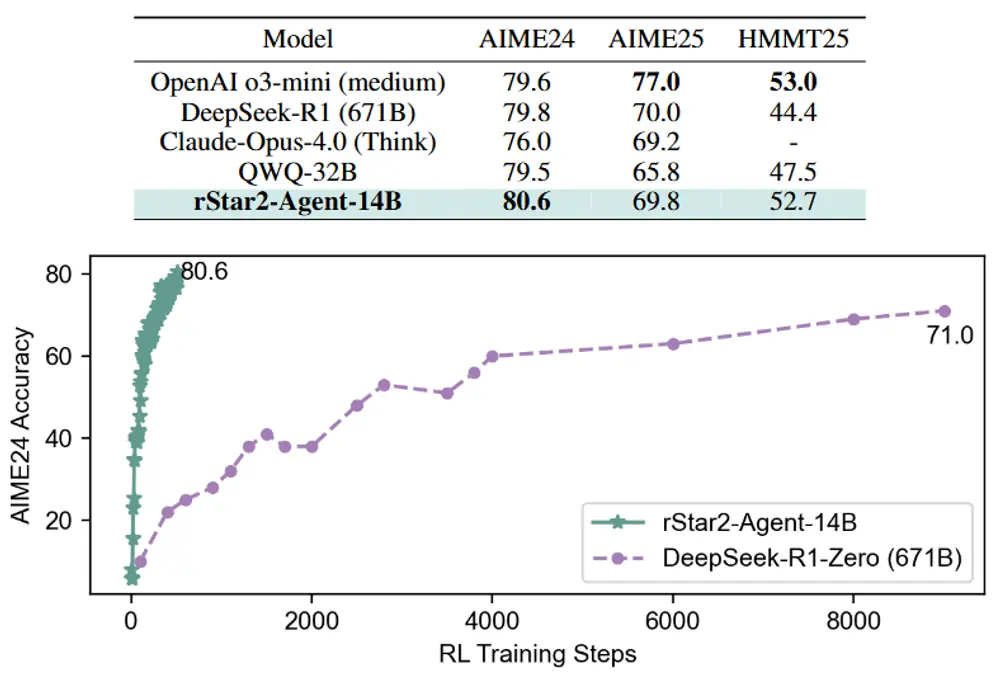
在数学竞赛级别的基准测试(AIME24、AIME25)中,rStar2-Agent展现了顶尖实力:AIME24平均pass@1得分达80.6%,AIME25达69.8%,直接超越了参数规模是其4.8倍的DeepSeek-R1(671亿参数),且推理过程的响应长度更短,效率优势显著。
2. 自主编码工具调用与验证
面对复杂数学问题时,模型会先梳理思路,再主动生成并执行Python代码——例如通过代码计算复杂积分、验证方程解的正确性,而非依赖“纯文本推理”。更关键的是,它能根据代码执行结果调整思路:若结果不符合预期,会反思代码逻辑或推理步骤,直至找到正确方向。
3. 跨领域泛化能力
尽管rStar2-Agent的训练以数学数据为主,但在对齐任务、科学推理(如物理公式推导、化学反应分析)及其他代理工具使用场景中,它仍展现出强大的适配能力,证明其核心推理框架具备“跨任务迁移”的价值。
工作原理:拆解“智能推理”的完整流程
rStar2-Agent的推理过程并非“黑箱”,而是一套可拆解的、交互式的解决流程,具体可分为四步:
- 环境搭建:模型运行在支持Python代码执行的环境中,确保能随时调用编码工具辅助计算;
- 多轮交互式推理:针对问题,模型先输出初步推理思路,再根据需要调用代码工具,将代码执行结果融入下一轮推理——例如先通过代码验证“中间变量计算是否正确”,再基于正确结果推进后续步骤;
- GRPO-RoC算法筛选优化:在训练阶段,算法会从大量推理轨迹中筛选出“正确且高效”的正向样本,同时保留失败样本作为“避坑指南”,让模型不断优化推理策略;
- 阶梯式训练迭代:从基础SFT训练开始,每阶段训练的数据集难度逐步提升(如从基础代数题到复杂数论题),同时限制最大响应长度,倒逼模型“用更简洁的思路解决更难的问题”。
关键优势:重新定义“高效推理模型”的标准
rStar2-Agent的突破,不仅是“参数与性能的倒挂”,更在于它为大模型推理任务提供了“轻量、高效、可复用”的新范式,其核心优势可总结为三点:
- 参数轻量化,性能顶尖:14亿参数实现671亿参数模型的性能,大幅降低了模型部署和应用的资源成本;
- 训练高效可控:仅需510个强化学习步骤、64个MI300X GPU,一周内即可完成训练,对比传统大模型“数月、数百GPU”的训练成本,效率提升显著;
- 推理逻辑可解释:模型的“思路梳理-工具调用-结果反思”流程更接近人类解决问题的方式,且能输出中间步骤(如代码、推理笔记),便于追溯和验证。
对于需要高精度推理的场景(如教育领域的个性化解题指导、科研领域的复杂公式推导、工程领域的数学建模),rStar2-Agent的“轻量高效+可解释”特性,或许能为这些场景的大模型落地提供新的思路——未来,“小参数、强推理”或成为大模型发展的重要方向之一。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











