
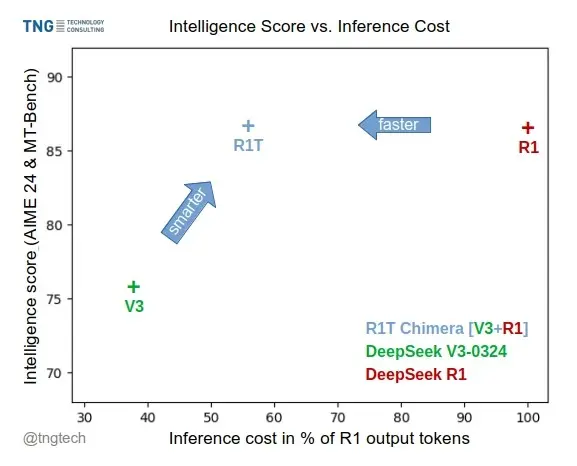
TNG科技发布了 DeepSeek-R1T-Chimera,这是一个通过创新方法构建的开放权重模型。它将 DeepSeek-R1 的强大推理能力与 DeepSeek-V3 (0324) 的高效 token 输出特性相结合,在基准测试中表现出与 R1 相当的智能水平,同时显著提升了速度和效率——使用的输出 token 减少了 40%。
Chimera 并非通过传统的微调或蒸馏技术生成,而是通过一种全新的子模型构建方法,利用了 V3 的共享专家模块,并结合了 R1 和 V3 路由专家的自定义合并。这种设计不仅保留了父模型的优势,还带来了更紧凑、更有序的推理过程,甚至在某些场景下超越了 R1 的表现。
什么是 DeepSeek-R1T-Chimera?
DeepSeek-R1T-Chimera 是一个开放权重的混合模型,旨在结合 DeepSeek-R1 的推理能力和 DeepSeek-V3 的高效输出特性。它是通过对两个父级 MoE(Mixture of Experts)模型的神经网络部分进行合并而构建的,而不是简单的微调或蒸馏。
尽管 Chimera 是从两个复杂模型中提取并重新组合而成,但它并未表现出明显的缺陷。相反,它的推理过程更加精炼和有序,避免了 R1 模型中有时过于冗长和漫无边际的思考路径。
模型亮点
1. 更高效的 token 使用
在基准测试中,Chimera 展现出了比 R1 快得多的速度,同时使用的输出 token 减少了 40%。这使得它在生成文本时更加高效,特别适合需要快速响应的应用场景。
2. 更紧凑的推理过程
Chimera 的推理逻辑比 R1 更加紧凑和清晰。相比于 R1 偶尔出现的冗长思维链条,Chimera 的思考过程显得更有条理,能够更快地得出结论。
3. 开放权重,灵活使用
作为一款开放权重模型,Chimera 提供了极大的灵活性。研究人员和开发者可以自由探索其架构和性能,为各种应用场景量身定制解决方案。
4. 创新的模型合并方法
Chimera 的构建方式是一种突破性的尝试。它通过合并 DeepSeek-R1 和 DeepSeek-V3 的共享专家模块以及路由专家,创造了一个兼具两者优势的子模型。这种方法为未来的模型优化提供了新的思路。
模型详情
架构:基于 DeepSeek-MoE Transformer 的语言模型 组合方法:合并 DeepSeek-R1 和 DeepSeek-V3 (0324) 的模型权重 发布日期:2025 年 4 月 27 日
为什么选择 Chimera?
智能与效率的完美平衡:Chimera 继承了 R1 的推理能力,同时融合了 V3 的高效输出特性,使其在保持高水平智能的同时,大幅降低了资源消耗。 适用于多种场景:无论是复杂的推理任务还是需要快速生成的场景,Chimera 都能提供出色的表现。它尤其适合对速度和效率有较高要求的应用,如实时对话系统或自动化内容生成。 开放性带来的无限可能:作为一款开放权重模型,Chimera 为研究者和开发者提供了广泛的研究和应用空间。你可以根据具体需求对其进行调整和优化,探索更多潜在用途。 创新的模型构建方法:Chimera 的成功证明了通过合并不同模型的神经网络部分来创建子模型的可行性。这一方法不仅为模型优化开辟了新方向,也为未来的研究提供了宝贵的参考。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











