
在强化学习(RL)领域,大型基础模型一直是研究的主流方向。目前,许多成功的强化学习项目,尤其是那些专注于代码推理能力的项目,都依赖于庞大的模型,例如拥有 320 亿参数的模型。然而,要在小型模型中同时实现数学和代码推理能力的提升,一直被视为一个巨大的挑战。
小米团队的最新研究打破了这一传统认知。他们认为,强化学习训练出的推理模型的有效性,实际上依赖于基础模型本身所固有的推理潜力。因此,要充分释放语言模型的推理能力,不仅需要在后训练阶段下功夫,还需要在预训练阶段进行针对性的优化。
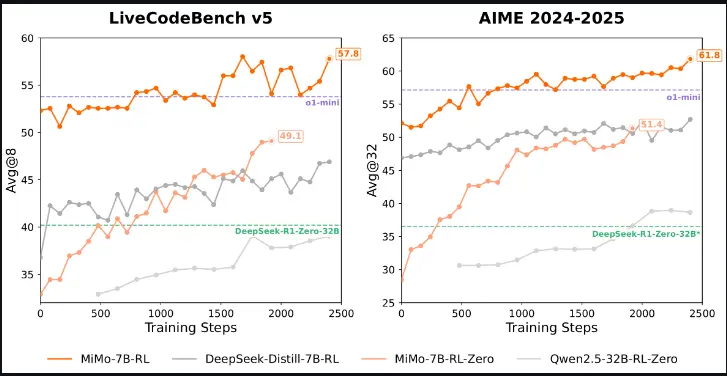
基于这一理念,小米团队推出了 MiMo-7B,这是一系列专为推理任务从头开始训练的模型。实验结果表明,MiMo-7B 模型展现出了非凡的推理潜力,甚至在某些方面超越了更大的 320 亿参数模型。此外,团队还对一个冷启动的监督微调(SFT)模型进行了强化学习训练,最终得到了 MiMo-7B-RL。这一模型在数学和代码推理任务上表现卓越,与 OpenAI 的 o1-mini 模型不相上下(PS:如此小地参数量,这个与 o1-mini 模型不相上下不可信)。
| 模型 | 描述 | 下载 |
|---|---|---|
| MiMo-7B-Base | 具有非凡推理潜力的基础模型 | XiaomiMiMo/MiMo-7B-Base |
| MiMo-7B-RL-Zero | 基于基础模型训练的RL模型 | XiaomiMiMo/MiMo-7B-RL-Zero |
| MiMo-7B-SFT | 基于基础模型训练的 SFT 模型 | XiaomiMiMo/MiMo-7B-SFT |
| MiMo-7B-RL | 使用 SFT 模型训练的 RL 模型,表现优于 OpenAI o1-mini | XiaomiMiMo/MiMo-7B-RL |
为了推动研究的进一步发展,小米团队开源了 MiMo-7B 系列,包括基础模型、监督微调模型、基于基础模型训练的强化学习模型,以及基于监督微调模型训练的强化学习模型的检查点。
预训练:为推理而生的基础模型
在预训练阶段,小米团队优化了数据处理流程,增强了文本提取工具包,并应用多维度数据过滤,以提高预训练数据中推理模式的密度。此外,团队采用了三阶段数据混合策略,利用 25 万亿个 token 强化基础模型的推理潜力,并引入多令牌预测目标以提高性能和推理速度。
- 优化数据处理流程:通过增强文本提取工具包和应用多维度数据过滤,团队提高了预训练数据中推理模式的密度。
- 三阶段数据混合策略:MiMo-7B-Base 在大约 25 万亿个 tokens 上进行了预训练,这一策略有效提升了模型的推理能力。
- 多令牌预测目标:作为额外的训练目标,多令牌预测不仅增强了模型性能,还加速了推理速度。
后训练方案:开创性的推理模型
在后训练阶段,团队精心挑选了 13 万个数学和代码问题作为强化学习的训练数据,并采用测试难度驱动的代码奖励机制和数据重采样策略来稳定训练。
- 训练数据选择:13 万个数学和代码问题经过仔细清理和难度评估,确保了训练数据的高质量。
- 测试难度驱动的代码奖励机制:通过为不同难度级别的测试用例分配细粒度的分数,团队解决了代码问题的稀疏奖励问题,优化了训练策略。
- 数据重采样策略:对简单问题实施数据重采样,提高了 rollout 采样的效率并稳定了策略更新,尤其是在强化学习训练的后期阶段。
强化学习基础设施
为了加速强化学习的训练和验证,小米团队开发了一个无缝 Rollout 引擎。这一设计集成了连续 rollout、异步奖励计算和提前终止,最大限度地减少了 GPU 的空闲时间,实现了 2.29 倍的训练速度提升和 1.96 倍的验证速度提升。此外,团队还在 vLLM 中支持多令牌预测,并增强了强化学习系统中推理引擎的鲁棒性。
亮点总结
- 预训练优化:改进数据处理流程,采用三阶段数据混合策略,引入多令牌预测目标,提升模型推理潜力。
- 后训练创新:精心挑选训练数据,采用测试难度驱动的代码奖励机制和数据重采样策略,优化模型性能。
- 基础设施升级:开发无缝 Rollout 引擎,提升训练和验证效率,增强推理引擎的鲁棒性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











