
Meta、华盛顿大学、新加坡国立大学、艾伦人工智能研究所、斯坦福大学、麻省理工学院和加州大学伯克利分校的研究人员推出一种名为 ReasonIR-8B 的新型检索器,专门针对需要推理的复杂任务进行优化。与传统的检索器不同,ReasonIR-8B 通过合成数据训练,能够更好地处理复杂的、需要推理的查询任务,而不仅仅是简单的事实性问题。
例如,在传统的检索任务中,用户可能会问:“黄石国家公园的名字是怎么来的?” 这个问题可以通过简单的关键词匹配直接从文档中找到答案。然而,在需要推理的任务中,问题可能会是:“如果一个公司以‘重组’为由解雇员工,但员工认为这是对举报不当行为的报复,法律上是否可以认定这是非法解雇?” 这种问题需要检索器不仅找到与“重组”相关的文档,还要理解文档中的法律背景、案例和推理逻辑,才能提供有用的信息。
主要功能
ReasonIR-8B 的主要功能是为复杂的推理任务提供高质量的文档检索支持。它能够:
- 处理复杂的查询:通过合成数据训练,ReasonIR-8B 能够理解并处理长的、复杂的查询,而不仅仅是简单的事实性问题。
- 提供推理支持:检索与问题相关的背景知识、推理模式和示例问题,帮助用户更好地理解和解决复杂的推理任务。
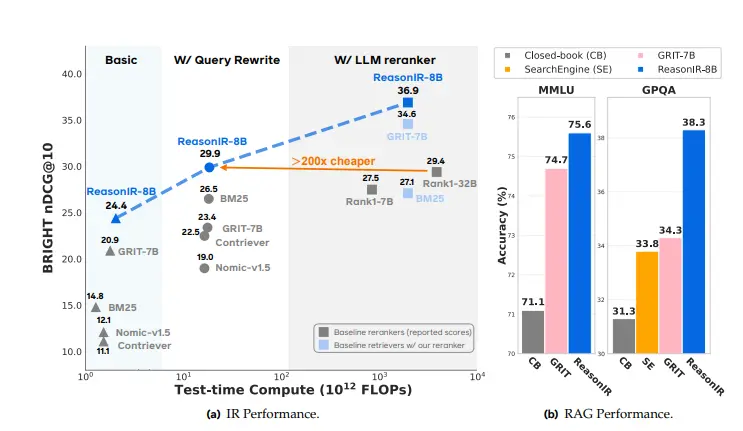
- 提高检索效率:在推理密集型任务中,ReasonIR-8B 的性能优于现有的检索器和搜索引擎,同时计算成本更低。
主要特点
- 专门针对推理任务优化:ReasonIR-8B 是第一个专门为推理任务训练的检索器,能够处理复杂的、需要推理的查询。
- 合成数据训练:通过 ReasonIR-SYNTHESIZER 合成数据,生成具有挑战性和相关性的查询和文档对,以及看似相关但实际上无帮助的“难负样本”。
- 高效利用测试时计算资源:ReasonIR-8B 在测试时能够通过查询重写(Query Rewriting)和语言模型重排器(LLM Reranker)进一步提升性能,同时计算成本远低于现有的重排器。
- 开源和可扩展性:论文开源了代码、数据和模型,方便未来研究者将其应用于新的语言模型或任务。
工作原理
ReasonIR-8B 的工作原理基于以下几个关键步骤:
- 合成数据生成:
- Varied-Length Data (VL):生成不同长度的查询及其对应的合成文档,扩展检索器的有效上下文长度。
- Hard Query Data (HQ):基于高质量的文档生成推理密集型查询,并通过多轮方法生成“难负样本”。
- Public Data:结合现有的公共数据集,如 MS MARCO 和 Natural Questions,提供多样化的训练数据。
- 对比学习:
- 使用对比学习目标,优化检索器将查询嵌入到与相关文档更接近的向量空间中,同时远离不相关的文档。
- 通过合成数据和公共数据的混合训练,提升检索器在推理密集型任务中的性能。
- 测试时优化:
- 查询重写:通过语言模型将原始查询重写为更长、更详细的信息性查询,提升检索质量。
- LLM 重排器:结合语言模型对检索结果进行重排,进一步提升检索的准确性和相关性。
应用场景
- 复杂问答系统:在需要推理的问答系统中,如法律咨询、医学研究或学术问题解答,ReasonIR-8B 能够提供更准确和相关的文档支持。
- 教育和学习工具:在教育领域,ReasonIR-8B 可以帮助学生和教师找到与复杂问题相关的背景知识和推理模式,辅助学习和教学。
- 企业知识管理:在企业环境中,ReasonIR-8B 可以用于内部知识库的检索,帮助员工快速找到与复杂问题相关的解决方案和背景信息。
- 研究和开发:在科研和开发中,ReasonIR-8B 可以帮助研究人员快速找到相关的文献、实验结果和研究方法,加速研究进程。
通过这些功能和应用场景,ReasonIR-8B 为复杂推理任务提供了强大的检索支持,显著提升了检索质量和效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











