
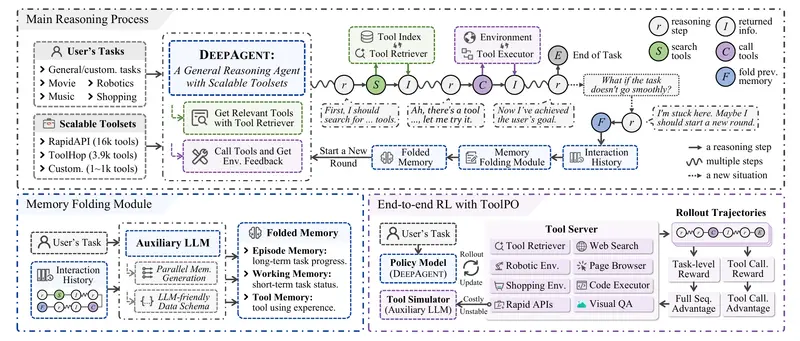
中国人民大学与小红书联合推出 DeepAgent——一种端到端的深度推理代理框架。它能够在单一、连贯的推理过程中,自主完成思考、工具发现与行动执行,摆脱了传统代理(如 ReAct 框架)中“Reason-Act-Observe”循环的预设限制。
这一设计使 DeepAgent 能始终保持对任务全局的理解,并根据实际需求动态选择和调用工具,显著提升了在复杂、开放环境中的适应能力。
为什么要重新设计代理框架?
传统代理通常依赖固定工作流:先推理,再调用预定义工具,然后观察结果,循环往复。这种方式在工具集有限、任务结构清晰的场景中表现良好,但在现实任务中常常捉襟见肘——工具可能未知、任务路径可能多变、交互可能持续数十步。
DeepAgent 的目标是应对这类真实挑战:支持大规模工具集、处理长时程交互、避免陷入无效探索。
三大核心技术
1. 统一代理推理:思考、发现、执行一体化
DeepAgent 在一个连贯的推理流中完成全部决策,无需切换模块或遵循固定模板。当任务需要外部能力(如搜索、代码执行、文件处理)时,它能自主生成工具查询,从超过 16,000 个 RapidAPI 工具中检索并调用合适的接口。
2. 自主记忆折叠:受大脑启发的结构化记忆机制
为应对长期交互中的信息过载,DeepAgent 引入“自主记忆折叠”机制。在适当节点,它会将历史交互压缩为三类结构化记忆:
- 情节记忆:记录关键事件与子任务完成状态;
- 工作记忆:保存当前子目标与近期计划;
- 工具记忆:归纳过往工具使用经验,用于策略优化。
这一机制让代理能“停下来喘口气”,在浓缩信息的基础上重新规划,避免在错误路径上越陷越深。
3. ToolPO:面向通用工具调用的端到端强化学习方法
为高效训练 DeepAgent,研究团队提出 ToolPO(Tool-aware Policy Optimization),其包含两个关键设计:
- 基于 LLM 的工具模拟器:在训练中用语言模型模拟真实 API 响应,避免依赖不稳定或不可用的外部服务;
- 工具调用优势归因:为每一次工具调用分配细粒度奖励信号,精准引导模型学习“何时调、调什么、怎么调”。
实验表明,ToolPO 显著提升了训练稳定性与任务成功率。
实验验证:覆盖通用工具与下游应用
研究团队在两类场景中全面评估 DeepAgent:
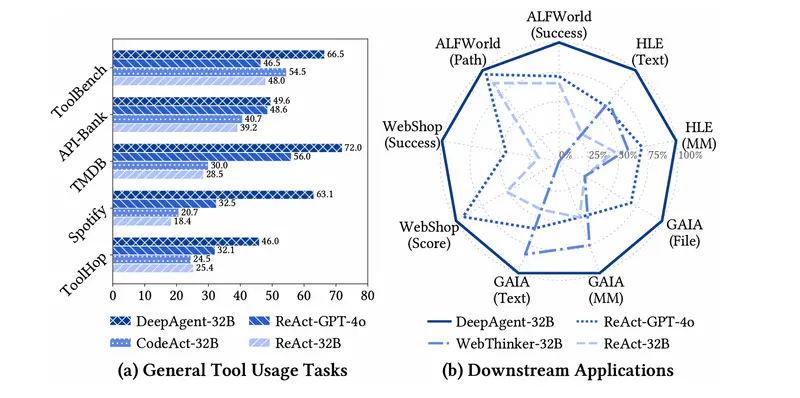
(1)通用工具使用任务
在 ToolBench、API-Bank、TMDB、Spotify 和 ToolHop 等基准上,DeepAgent 支持从几十到上万工具的动态检索与调用。即使部分 API 不可用(实验中由 LLM 模拟响应),系统仍能正常运行并完成任务。
(2)下游复杂应用
- ALFWorld:基于文本的具身交互环境(如“去厨房拿苹果”);
- WebShop:模拟真实电商购物任务;
- GAIA:需结合网页浏览、代码执行、文件解析的多模态推理;
- Humanity's Last Exam (HLE):涵盖科学、工程、数学的高难度综合问题。
在所有基准中,DeepAgent 均取得当前最优或接近最优的性能,尤其在需长期规划与工具组合的任务中优势明显。
模型部署与服务依赖
DeepAgent 依赖高性能推理后端提供主模型与辅助模型服务。官方推荐使用 vLLM进行部署,以支持高吞吐、低延迟的推理需求。
主推理模型(具备“思考”能力)推荐:
| 模型 | 参数量 | 类型 | 来源 |
|---|---|---|---|
| Qwen3-4B-Thinking | 4B | Thinking | Hugging Face |
| Qwen3-8B | 8B | Hybrid | Hugging Face |
| Qwen3-30B-A3B-Thinking | 30B | Thinking | Hugging Face |
| QwQ-32B | 32B | Thinking | Hugging Face |
| Qwen3-235B-A22B-Thinking | 235B | Thinking | Hugging Face |
辅助模型(用于记忆生成、工具选择等轻量任务):
推荐使用 Qwen2.5-Instruct 或 Qwen3-Instruct 系列,无需“思考”能力,推理速度更快。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











