在大模型领域,“黑盒”一直是悬在开发者头顶的达摩克利斯之剑。我们深知模型强大,却往往不知其为何强大,更难以精准控制其行为。
今天,Guide Labs 正式发布了 Steerling-8B——全球首个具有内在可解释性(Intrinsic Interpretability)的大语言模型。这不仅仅是一个新模型的发布,更是 AI 架构设计的一次范式转移:从“事后猜测”转向“事前设计”,让模型生成的每一个 Token 都清晰可追溯。
- GitHub:https://github.com/guidelabs/steerling
- 模型:https://huggingface.co/guidelabs/steerling-8b
核心突破:三维追溯,彻底打开黑盒
Steerling-8B 是一个 80 亿参数的模型,在 1.35 万亿 Token 上训练而成。其革命性在于,对于它生成的任意一个 Token,我们都能从三个维度精确追溯其来源:
- [输入上下文] (Input Context):
- 是提示词(Prompt)中的哪个具体词汇触发了这段生成?
- 应用:精准定位用户意图,优化提示词工程。
- [人类可理解的概念] (Concepts):
- 模型内部激活了哪些具体概念?是“分析性语气”、“临床风格”,还是“基因改造方法学”?
- 应用:理解模型的思维路径,识别潜在的偏见或错误逻辑。
- [训练数据来源] (Training Data):
- 这段知识究竟来自 ArXiv 论文、维基百科,还是 FLAN 数据集?
- 应用:版权合规审查、数据估值、事实核查。
这意味着什么?
以前,要理解模型为何说某句话,我们需要复杂的逆向工程,且结果往往不可靠。现在,你可以直接点击输出中的任意片段,瞬间看到它的“前世今生”。
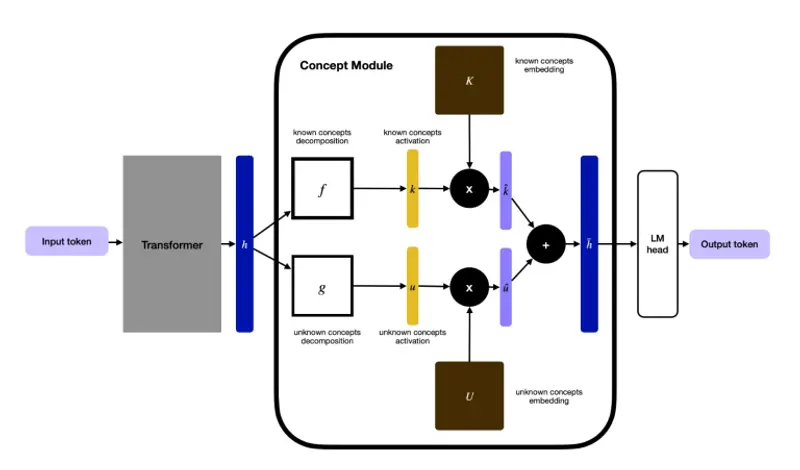
架构揭秘:因果离散扩散与概念路由
Steerling-8B 之所以能做到这一点,源于其独特的底层架构设计:
- 因果离散扩散骨干 (Causal Discrete Diffusion Backbone):
不同于传统的自回归模型,这种架构允许跨多个 Token 进行生成引导,提供了更全局的控制能力。 - 三路嵌入分解 (Three-Path Embedding Decomposition):
模型将信息流明确分解为三条路径:- 已知概念路径:约 33,000 个经人工监督定义的“已知”概念。
- 发现概念路径:约 100,000 个模型自行学习并聚类的“发现”概念。
- 残差路径:捕获剩余无法归类的信息。
- 概念路由约束 (Concept Routing Constraints):
通过特殊的训练损失函数,Guide Labs 强制模型将绝大部分预测信号(验证集显示超过 84%)流经“概念模块”,而非隐藏的残差通道。- 关键验证:当移除残差路径时,模型性能几乎不受影响,证明其核心智能确实存储在可解释的概念中。
- 高准确率:模型在检测已知概念方面的 AUC 高达 96.2%。
解锁的全新能力
这种架构带来的不仅仅是透明度,更是前所未有的控制力:
1. 推理时精准控制 (Inference-Time Control)
无需重新训练或微调,只需在推理阶段干预特定的概念节点,即可抑制或放大模型的某种行为。
- 示例:想让模型回答得更“临床”一点?直接调高“临床语气”概念的权重。想去除性别偏见?直接关闭相关概念通路。
2. 无需微调的对齐 (Alignment without Fine-tuning)
传统的安全对齐需要数千个 RLHF 样本和漫长的微调过程。Steerling-8B 可以通过少量概念级引导,直接替代复杂的安全训练。
- 优势:大幅降低对齐成本,提高响应速度,且规则透明可查。
3. 训练数据估值与记忆化
任何生成内容都可追溯至具体的训练数据源。这不仅有助于解决版权争议,还能为高质量数据源定价,构建更健康的数据生态。
4. 概念发现 (Concept Discovery)
模型自行学习的 10 万个“发现概念”中,隐藏着许多人类未明确定义的知识结构。Guide Labs 计划开放这部分空间,让我们看看 AI 到底“发现”了什么令人惊讶的模式。
性能表现:少即是多
很多人担心可解释性会牺牲性能。但数据显示:
- 数据效率:Steerling-8B 仅使用了同类模型 1/2 到 1/7 的训练数据量。
- 基准测试:在 7 个主流基准测试中,其平均性能与使用更多数据训练的模型相当,甚至在某些任务上更具竞争力。
这证明:可解释性与高性能并非零和博弈,优秀的架构设计可以兼得二者。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...