OPPO AI实验室推出一种新的范式——Chain-of-Agents(CoA),用于在单个模型中实现多智能体系统(Multi-Agent Systems, MAS)的复杂问题解决能力。传统的多智能体系统通常依赖于手动的提示/工作流工程,计算效率低下,且难以从数据驱动的学习中受益。而CoA范式通过动态激活不同的工具智能体(Tool Agents)和角色扮演智能体(Role-playing Agents),在单个模型中模拟多智能体协作,从而实现端到端的复杂问题解决。
- 项目主页:https://chain-of-agents-afm.github.io
- GitHub:https://github.com/OPPO-PersonalAI/Agent_Foundation_Models
- 模型:https://huggingface.co/collections/PersonalAILab/afm-models-689200e11d0b21a67c015ba8
例如,有一个任务是“分析全球人口在过去一年的变化,并生成一份报告”。在传统的多智能体系统中,可能需要多个智能体分别负责搜索、数据提取、代码生成和报告撰写,且需要复杂的提示和工作流设计。而CoA范式下,模型可以动态激活搜索智能体获取数据,代码生成智能体处理数据,最后由报告撰写智能体生成报告,所有步骤在单个模型中完成,无需复杂的工程设计。
主要功能
- 复杂问题解决:CoA能够处理多步推理任务,涉及多个工具和多个智能体的协作。
- 动态智能体激活:根据任务需求动态激活不同的智能体,例如搜索智能体、代码生成智能体等。
- 多智能体蒸馏:通过将现有的多智能体系统的执行轨迹蒸馏为CoA轨迹,用于监督式微调(Supervised Fine-Tuning, SFT)。
- 智能体强化学习:使用强化学习进一步优化模型在可验证任务上的性能。
主要特点
- 端到端训练:CoA支持从输入到输出的端到端训练,无需复杂的提示工程或工作流设计。
- 计算效率高:通过减少智能体间通信的冗余,降低了计算开销。
- 数据驱动学习:能够从数据中学习,支持模型性能的持续提升。
- 泛化能力强:在未见过的任务上表现出色,具有良好的泛化能力。
工作原理
- 多智能体蒸馏:
- 从现有的多智能体系统(如OAgents)中提取执行轨迹。
- 将这些轨迹转换为CoA兼容的格式,用于监督式微调。
- 通过多阶段过滤机制,确保高质量的训练数据。
- 智能体强化学习:
- 在验证过的任务上进行强化学习,优化模型的策略。
- 使用LLM-as-Judge评估答案的正确性,设计奖励函数以激励模型生成正确的答案。
测试结果
- Web Agent实验:
- 在GAIA、BrowseComp、HLE等基准测试中,AFM取得了新的最佳性能。
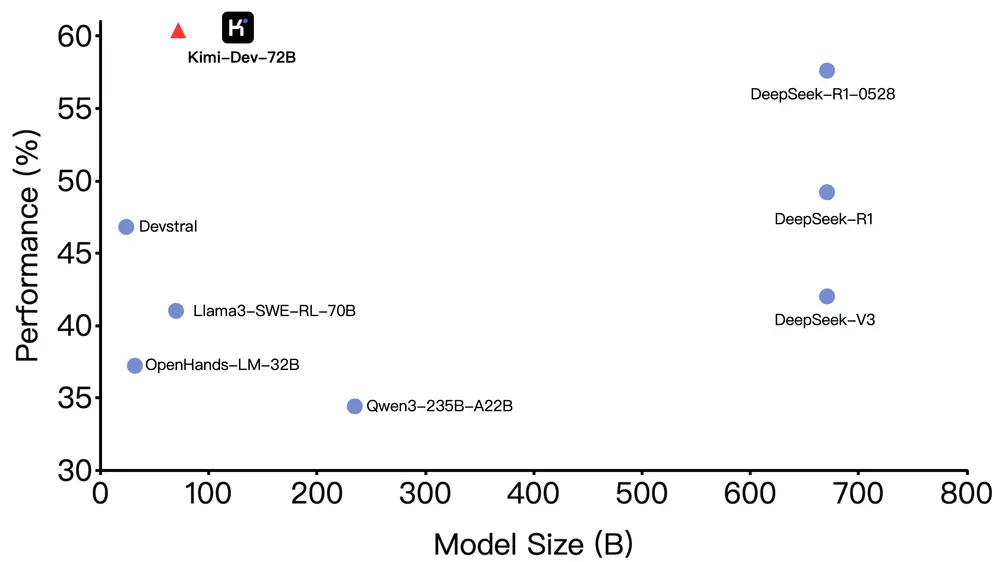
- 例如,在GAIA上,AFM达到了55.3%的Pass@1成功率,比之前的最佳模型高出2.1%。
- Code Agent实验:
- 在LiveCodeBench v5和CodeContests等基准测试中,AFM显著优于现有的工具集成推理(TIR)方法。
- 例如,在AIME2025基准测试中,AFM达到了59.8%的解题率,比之前的最佳模型高出10.5%。
- 计算效率:
- AFM在推理成本(以token消耗计)上比传统多智能体系统降低了84.6%,同时保持了竞争力。

应用场景
- 复杂信息检索:在GAIA、BrowseComp等基准测试中,AFM能够高效地解决多步推理和工具协作任务。
- 代码生成与数学推理:在LiveCodeBench、AIME等基准测试中,AFM能够生成高质量的代码并解决复杂的数学问题。
- 学术研究与知识密集型任务:在HLE等基准测试中,AFM能够处理前沿学术问题,展现出强大的推理能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











