经过两个多月测试,DeepSeek 正式推出 V3.2 系列模型,包括平衡型主力版本 DeepSeek V3.2 与极致推理增强版 DeepSeek V3.2 Speciale。前者以“推理能力不逊 GPT-5”的表现刷新开源模型上限,后者则斩获 IMO、ICPC 等 4 大国际顶级赛事金牌,达到人类顶尖选手水平。更值得关注的是,DeepSeek V3.2 成为首个实现“思考模式与工具调用融合”的开源模型,彻底打破过往版本“思考与工具二选一”的局限,为通用代理、复杂任务处理提供了全新解决方案。
DeepSeek-V3.2
- HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-V3.2
- ModelScope:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2
DeepSeek-V3.2-Speciale
- HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale
- ModelScope:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Speciale

核心定位:双版本策略,覆盖“日常实用”与“极限探索”
DeepSeek V3.2 系列采用差异化定位,精准适配不同用户需求:
- DeepSeek V3.2(主力版):核心目标是“平衡推理能力与输出效率”,聚焦问答、通用 Agent 等日常使用场景。在保证推理性能追平 GPT-5 的同时,大幅缩短输出长度,降低计算开销与用户等待时间,兼顾“强能力”与“高实用”。
- DeepSeek V3.2 Speciale(增强版):核心目标是“将开源模型推理能力推向极致”,定位为研究与极限任务场景。整合 DeepSeek Math V2 定理证明能力,专注处理高复杂度数学推理、程序设计等任务,探索开源模型的能力边界。
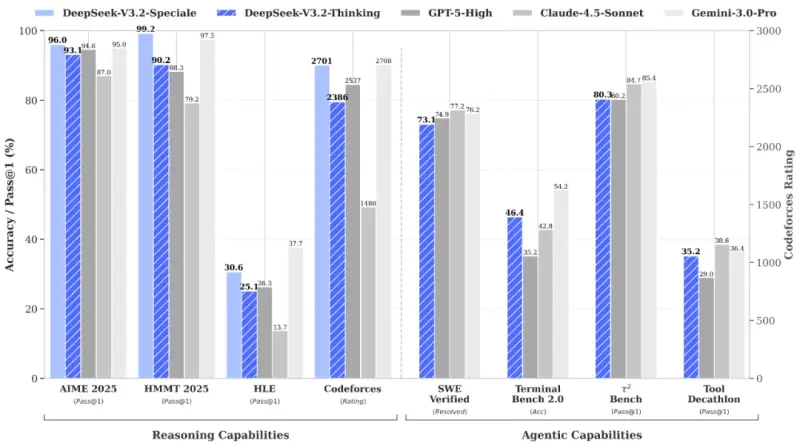
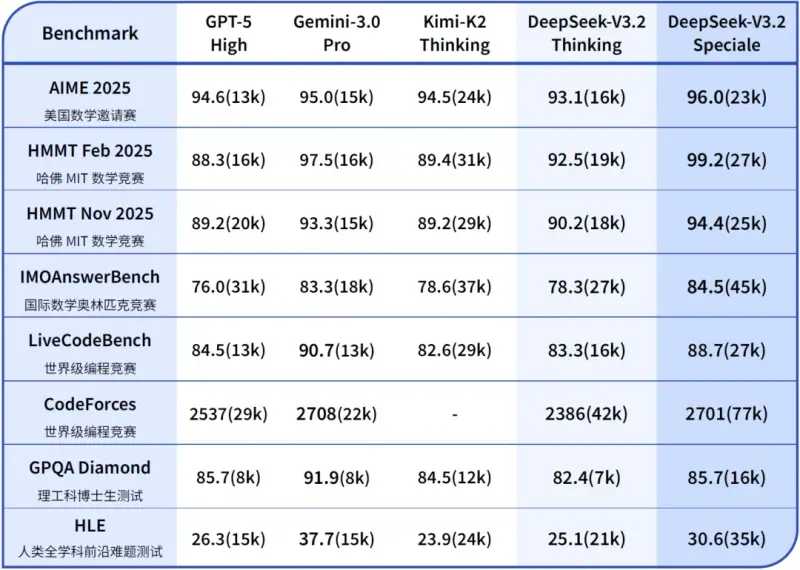
核心技术突破:三大亮点重构开源模型能力
1. 推理性能跃居全球前列,对标顶级闭源模型
- 主力版(V3.2):在公开推理类 Benchmark 测试中达到 GPT-5 水准,仅略低于 Gemini 3.0 Pro,大幅领先同类开源模型;相比 Kimi-K2-Thinking,输出长度显著缩短,计算效率提升明显,避免“冗长思考”导致的资源浪费。
- 增强版(Speciale):推理能力实现质变,不仅在主流基准测试中媲美 Gemini 3.0 Pro,更在 4 大国际顶级赛事中斩获金牌:
- IMO 2025(国际数学奥林匹克):金牌水平;
- CMO 2025(中国数学奥林匹克):金牌水平;
- ICPC World Finals 2025(国际大学生程序设计竞赛全球总决赛):分数达到人类选手第 2 名;
- IOI 2025(国际信息学奥林匹克):分数达到人类选手第 10 名。
这一成绩证明开源模型已具备处理“人类顶尖水平复杂任务”的能力,打破了闭源模型在高端推理场景的垄断。
2. 首次实现“思考融入工具调用”,Agent 能力大幅提升
过往开源模型的“思考模式”与“工具调用”相互独立,无法同时启用,导致复杂任务处理时要么缺乏深度思考,要么无法借助工具补全能力。DeepSeek V3.2 彻底解决这一痛点:
- 核心创新:支持“思考模式 + 工具调用”双开启,模型可通过多轮思考规划工具使用步骤,再通过工具调用获取结果,最终输出精准答案;
- 训练支撑:通过大规模 Agent 训练数据合成方法,构造 1800+ 环境、85,000+ 复杂指令的强化学习任务,大幅提升模型泛化能力;
- 实测表现:在智能体评测中达到当前开源模型最高水平,大幅缩小与闭源模型的差距,且未针对测试集工具进行特殊训练,真实场景适配性更强。
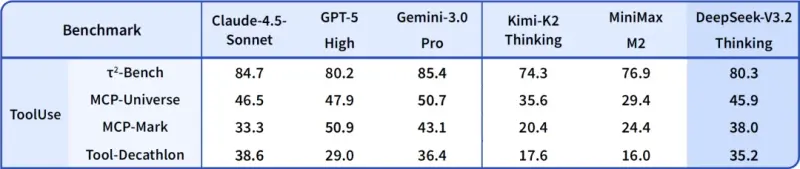
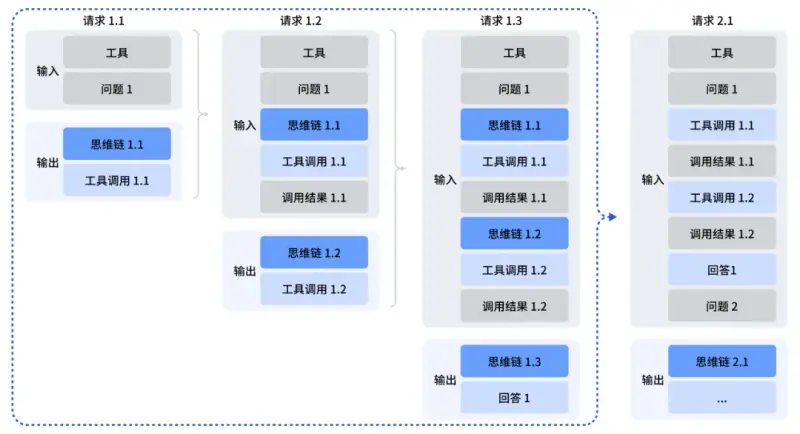
3. 差异化版本优化,兼顾效率与极限能力
- 效率优化(V3.2):平衡推理深度与输出长度,日常任务响应速度更快,Token 消耗更低,适合商业化应用与高频次使用场景;
- 极限增强(Speciale):强化长思考链条与数学/编程推理能力,最大输出长度默认 128K,可处理超长篇幅、高复杂度任务,但 Token 消耗更高,成本相对较高,目前聚焦研究场景。
核心功能与使用指南
1. 版本功能对比
| 特性 | DeepSeek V3.2(主力版) | DeepSeek V3.2 Speciale(增强版) |
|---|---|---|
| 核心定位 | 日常实用、平衡效率与推理 | 极限推理、研究场景、复杂任务处理 |
| 推理性能 | 追平 GPT-5,略低于 Gemini 3.0 Pro | 媲美 Gemini 3.0 Pro,4 大国际赛事金牌 |
| 特色能力 | 思考+工具调用融合、高泛化 Agent 能力 | 数学定理证明、顶级编程竞赛水平、128K 长输出 |
| 支持功能 | 工具调用、日常对话、通用问答、Agent | 仅支持思考模式对话,不支持工具调用 |
| 适用场景 | 商业应用、日常办公、通用代理开发 | 学术研究、复杂数学/编程任务、能力极限测试 |
| 开放形式 | 网页端、APP、API 正式开放 | 临时 API 开放(截至 2025-12-15),供评测研究 |
2. 调用方式与更新说明
(1)主力版(DeepSeek V3.2)
- 开放渠道:官网网页端、APP、API 已全面更新(由 V3.2-Exp 升级为正式版),使用方式不变;
- 工具调用支持:
- 支持思考模式与非思考模式下的工具调用,思考模式可实现多轮思考+工具联动;
- 新增 Claude Code 支持,用户可通过模型名“deepseek-reasoner”或 Claude Code CLI 按 Tab 键开启思考模式;
- 注意:思考模式暂未适配 Cline、RooCode 等非标准工具调用组件,建议此类场景使用非思考模式。
(2)增强版(DeepSeek V3.2 Speciale)
- 开放渠道:仅临时 API 开放,无网页端/APP 支持;
- API 配置:需设置 base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215";
- 限制说明:API 价格不变,仅支持思考模式对话,不支持工具调用,开放时间截止至 2025-12-15 23:59(北京时间)。
应用场景:从日常实用到极限探索
1. DeepSeek V3.2(主力版)适用场景
- 通用办公与问答:高效解答工作/学习中的复杂问题,支持工具调用(如查询、计算),答案精准且响应迅速;
- 通用 Agent 开发:作为 Agent 核心模型,处理多步骤任务(如行程规划、数据整理、跨平台操作),泛化能力强,适配多场景;
- 商业化应用集成:适合嵌入 SaaS 产品、智能助手等场景,平衡性能与成本,用户体验流畅。
2. DeepSeek V3.2 Speciale(增强版)适用场景
- 学术研究与教育:复杂数学定理证明、科研数据建模、编程算法优化,辅助科研人员与学生突破难题;
- 高端编程开发:处理 ICPC 级别的复杂编程任务,生成高效、严谨的代码,辅助资深开发者提升效率;
- 模型能力研究:供 AI 研究者测试开源模型的推理极限,探索长思考链条、复杂逻辑推理的优化方向。
行业影响与未来展望
1. 行业意义
- 打破开源与闭源模型的性能鸿沟:DeepSeek V3.2 系列证明开源模型可达到 GPT-5、Gemini 3.0 Pro 级别的推理能力,为开发者提供低成本、高性能的替代方案;
- 重构 Agent 开发范式:“思考+工具调用”的融合模式,降低了复杂 Agent 系统的开发门槛,推动开源 Agent 生态的发展;
- 树立开源模型赛事标杆:Speciale 版本在国际顶级赛事中的表现,为开源模型的“极限能力”提供了量化参考,激励行业技术迭代。
2. 未来方向
- 功能适配优化:完善思考模式对非标准工具调用组件的支持,实现全场景工具联动;
- 成本控制:在保持推理能力的前提下,进一步优化 Speciale 版本的 Token 消耗,降低商业化使用门槛;
- 能力拓展:持续强化模型在垂直领域的推理能力,如金融分析、医疗诊断、工业设计等,推动开源模型的工业化应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...