在开源AI领域,“开放”往往局限于最终模型权重的分享,而模型训练的数据、流程、中间检查点等核心环节仍处于“黑箱”状态。Ai2(艾伦人工智能研究所)最新发布的 Olmo 3 系列模型,彻底打破了这一现状——不仅提供性能顶尖的多规格开源模型,更首次开放了从训练数据、代码、中间检查点到后训练流程的全链路资源,让开发者和研究者能“看透”模型的完整生命周期,真正实现可追溯、可定制、可协作的开源创新。
- 模型:https://huggingface.co/collections/allenai/olmo-3
- 官方介绍:https://allenai.org/blog/olmo3
- Demo:https://playground.allenai.org
Olmo 3 系列包含基础模型、推理模型、对话模型、强化学习模型四大分支,覆盖7B到320B参数规模,可运行于笔记本电脑到研究集群等各类设备,在编程、数学、阅读理解等核心任务中表现亮眼,成为开源AI领域的全新标杆。
核心突破:不止开放模型,更开放“完整开发流程”
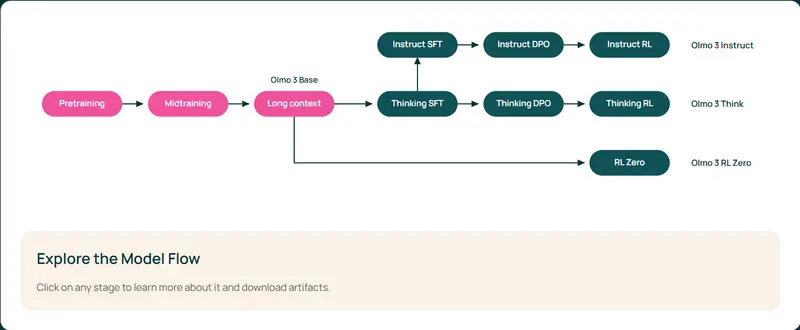
Olmo 3 的最大革新,在于将“模型流程”作为开放核心——这里的“流程”指模型从无到有的完整生命周期,包括:
- 训练数据:从初始预训练到后训练的全阶段数据集(含9.3万亿token的Dolma 3语料库);
- 中间检查点:预训练中期、长上下文扩展、后训练各阶段的模型快照,可在任意节点介入开发;
- 代码工具链:从数据清洗、训练框架到评估套件的全流程开源工具;
- 训练方案:多阶段训练策略、强化学习框架、超参数配置等完全文档化。
这种“全流程开放”带来三大价值:
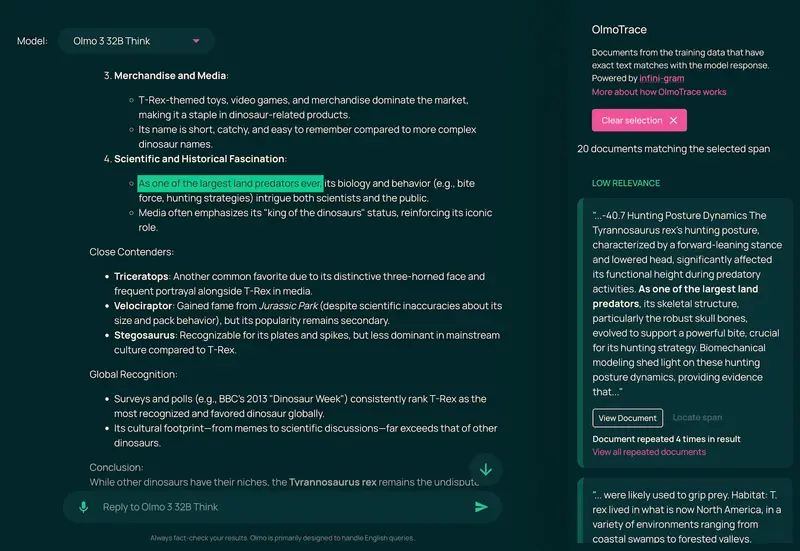
- 可追溯:通过 OlmoTrace 工具,能将模型输出追溯至对应的训练数据和训练决策,理解“模型为何这么做”;
- 可定制:开发者可在任意训练阶段分叉,替换领域特定数据、调整训练目标,快速适配专属场景;
- 可复现:完整的数据集、代码和流程文档,让研究结果可重复验证,推动开源社区的良性协作。
Olmo 3 系列模型:四大分支,覆盖全场景需求
Olmo 3 基于统一的基础模型扩展出四大功能分支,每个分支针对特定场景优化,兼顾性能与实用性:
1. Olmo 3-Base(基础模型):7B/32B/320B,开源领域的“全能底座”
- 定位:通用基础模型,适用于持续预训练、定向微调、强化学习等二次开发场景;
- 核心优势:
- 性能强劲:在完全开放的基础模型中(训练数据、代码、权重全公开)表现最优,与 Qwen 2.5、Gemma 3 等同类开放权重模型性能相当;
- 长上下文支持:可处理约65K token的长文本,在长文档检索、多章节内容理解等任务中保持性能稳定;
- 适配性强:支持与强化学习工作流无缝集成,易于扩展推理、工具使用、指令遵循等专业能力;
- 典型应用:作为企业级AI系统的底层底座,或研究者进行模型架构、训练方法创新的实验载体。
2. Olmo 3-Think(推理模型):7B/32B,最强开放“思维模型”
- 定位:专注多步骤推理,支持中间推理轨迹可视化,是强化学习、长程推理研究的核心工具;
- 核心优势:
- 推理性能顶尖:32B版本是目前已知最强的完全开放推理模型,在 MATH(数学解题)、HumanEvalPlus(编程)、BigBench Hard(通用推理)等基准测试中,与 Qwen 3 32B 等顶尖开放权重模型差距缩小,且训练所用token量仅为后者的1/6;
- 可检查推理过程:能输出中间思维步骤,结合 OlmoTrace 可追溯推理逻辑的来源;
- 轻量化可选:7B版本将相同推理能力压缩至小参数量,可在普通硬件上运行;
- 典型应用:数学解题、代码调试、复杂逻辑分析、智能体推理等场景。
3. Olmo 3-Instruct(对话模型):7B,高质量聊天与工具使用
- 定位:面向日常聊天、多轮对话、工具调用(函数调用)的实用型模型;
- 核心优势:
- 指令遵循能力强:在对话流畅度、任务完成度上匹配或超越 Qwen 2.5、Gemma 3、Llama 3.1 等同类开放模型;
- 工具调用性能突出:支持复杂函数调用场景,为构建聊天机器人、智能助手提供强大底座;
- 典型应用:客服机器人、个人助手、多轮对话系统、工具集成型应用。
4. Olmo 3-RL Zero(强化学习模型):7B,开放强化学习研究路径
- 定位:为强化学习算法研究提供清晰基准,支持复杂推理行为的定向引导;
- 核心优势:
- 提供四大领域检查点:涵盖数学、代码、指令遵循、通用聊天的聚焦训练快照;
- 完全开放RL流程:包含SFT(监督微调)、DPO(直接偏好优化)、RLVR(基于价值的强化学习)全阶段方案,可用于强化学习算法的对比实验;
- 典型应用:强化学习算法研究、推理行为优化、奖励机制设计等学术场景。
性能表现:多项任务领先,打破开源模型天花板
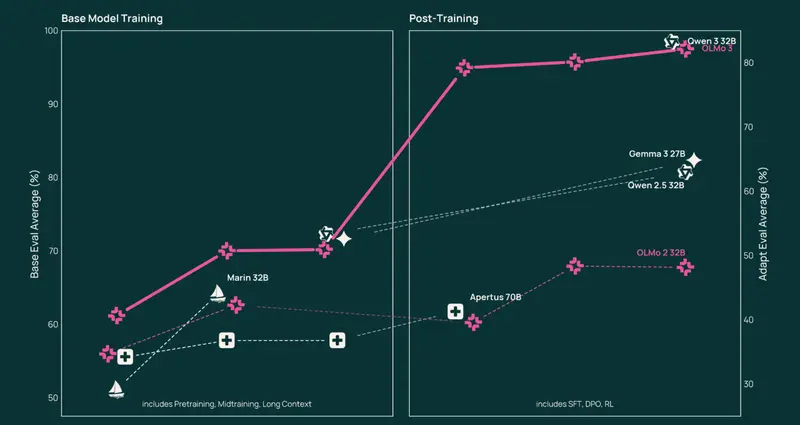
Ai2 为 Olmo 3 设计了覆盖数十个任务的集群化评估套件,全面测试其在数学、编程、阅读理解、推理、对话等领域的能力:
- 基础模型:Olmo 3-Base 32B 在编程(HumanEvalPlus)、数学(MATH)、长文本检索(RULER)等任务中表现突出,是开源领域32B规模的顶尖基础模型;
- 推理模型:Olmo 3-Think 7B 在 MATH 上匹配 Qwen 3 8B,在 HumanEvalPlus 编码测试中领先所有对比模型;32B版本在 OMEGA、BigBenchHard 等基准测试中与 Qwen 3 VL 32B Thinking 并列最高分;
- 对话模型:Olmo 3-Instruct 7B 在指令遵循、工具调用等任务中与同规模 Qwen 3 系列竞争,是完全开放模型中的优选方案。
这些成绩的背后,得益于 Ai2 在训练数据筛选、多阶段训练策略、算法优化等方面的持续投入——例如通过“初始大规模训练→中期难点强化→长上下文扩展”的三阶段预训练,让模型兼顾广度与深度。
全链路开放资源:数据、工具、流程一站式获取
Olmo 3 提供的开放资源覆盖模型开发全流程,无需额外依赖第三方工具:
1. 训练数据:9.3万亿token的全开放语料库
- Dolma 3:约9.3万亿token的预训练语料库,涵盖网页文本、科学PDF(经olmOCR处理)、代码库、数学题解、百科全书等,筛选后形成5.9万亿token的核心训练集;
- 专项数据集:Dolma 3 Dolmino(1000亿token,聚焦数学、代码、阅读理解)、Dolma 3 Longmino(500亿token,长文档训练)、Dolci(后训练专用数据集,含SFT、DPO、RL阶段数据);
- 所有数据集均提供多种格式版本,支持自定义筛选和混合使用,且遵循宽松开源许可。
2. 工具链:全流程开源,开箱即用
- 训练框架:Olmo-core(分布式训练框架,支持1024个H100 GPU集群,吞吐量达7.7K token/秒/设备);
- 数据处理:datamap-rs(Rust编写的大规模数据清洗工具)、duplodocus(高效模糊去重工具);
- 评估套件:OLMES(可重复评估工具包,含OlmoBaseEval评估集合);
- 辅助工具:decon(移除训练数据中的测试集污染)、OlmoTrace(模型输出追溯工具)。
3. 中间检查点:全阶段快照,支持任意节点分叉
Olmo 3 发布了每个关键训练阶段的模型检查点,包括:
- 预训练初始阶段、中期难点强化阶段、长上下文扩展阶段;
- 后训练SFT、DPO、RLVR各阶段的模型快照;
开发者可基于这些检查点,研究模型能力的涌现规律,或直接在最优阶段进行二次开发,大幅降低研发成本。
技术架构:多阶段训练,兼顾性能与效率
Olmo 3 采用“仅解码器的Transformer架构”,并通过多阶段训练流程实现能力升级:
- 预训练三阶段:
- 阶段一:大规模训练,构建广泛的语言理解和基础能力;
- 阶段二:难点强化,聚焦数学、代码、阅读理解等复杂任务;
- 阶段三:长上下文扩展,在极长文档上训练,支持65K token输入;
- 后训练三阶段:
- SFT(监督微调):对齐特定任务需求;
- DPO(直接偏好优化):基于人类偏好调整模型输出;
- RLVR(基于价值的强化学习):进一步提升复杂任务表现;
这种架构设计让 Olmo 3 在保持高效训练(后训练效率较Olmo 2提升4-8倍)的同时,实现了性能的全面突破。
适用场景:从学术研究到产业应用全覆盖
Olmo 3 系列的全流程开放特性和多规格模型,使其适配不同用户群体的需求:
- 研究者:可复现训练过程、进行消融实验、探索模型可解释性,推动AI基础研究;
- 开发者:基于基础模型快速微调领域专用模型(如法律、医疗、工业),或集成对话/推理能力构建应用;
- 企业:利用32B/320B大模型搭建企业级AI系统,无需依赖闭源模型,兼顾安全性与定制化;
- 教育机构:借助开放的流程和数据,开展AI教学与实践,培养相关人才。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











