
月之暗面(Moonshot AI)和加州大学洛杉矶分校的研究团队联合发布了 Moonlight,这是一款基于 Muon 优化器训练的混合专家(MoE)模型。该模型包含两种配置:一种具有 30 亿激活参数和总计 160 亿参数,并以 5.7 万亿 tokens 进行训练。Moonlight 的开发旨在应对大规模语言模型(LLM)训练中的挑战,特别是在优化效率、稳定性和计算成本方面。
背景与挑战
随着 LLM 的规模和数据集不断增长,传统的优化方法(如 AdamW)逐渐显现出其局限性。主要问题包括:
- 梯度消失或爆炸:在长期训练过程中,梯度可能变得过小或过大,导致模型难以收敛。
- 更新幅度不一致:不同参数矩阵之间的更新幅度差异可能导致训练不稳定。
- 分布式环境的资源需求:大规模训练需要高效的分布式实现,但传统方法通常伴随较高的内存开销和通信成本。
这些问题促使研究者探索更精细的优化技术,以提高训练效率和稳定性。
Moonlight 的技术创新
Moonlight 的核心创新在于使用了 Muon 优化器,这是一种基于 Newton-Schulz 迭代的矩阵正交化方法。Muon最初在小规模语言模型训练中表现出色,但其在大规模模型训练中的可扩展性尚未得到验证。
本研究通过引入权重衰减和调整参数更新尺度等技术,成功将 Muon 扩展到大规模语言模型训练中,并展示了其在计算效率和模型性能上的显著优势。
工作原理
- 权重衰减:通过在 Muon 的更新规则中加入权重衰减项,控制模型权重的增长,从而提高模型在大规模训练中的稳定性。
- 更新 RMS 调整:通过调整 Muon 的学习率和更新规则,使其更新的 RMS 与 AdamW 相匹配,从而优化了不同形状矩阵参数的更新效果。
- 分布式实现:通过 ZeRO-1 风格的优化,将优化器状态(如动量缓冲区)分区到不同的数据并行组中,减少了通信开销并优化了内存使用。
- 正交化更新:Muon 使用 Newton-Schulz 迭代来近似计算矩阵的正交化更新,从而优化了矩阵参数的更新方向,使其更加多样化。
实证评估与结果
1. 性能提升
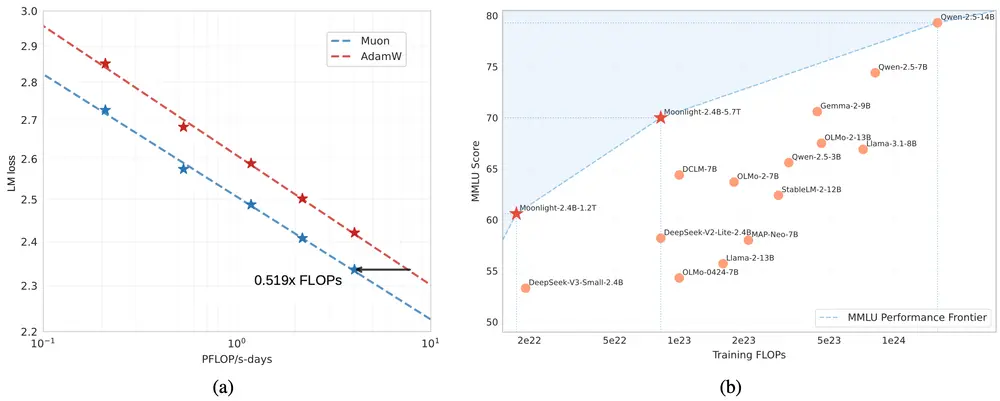
- 在 1.2 万亿 tokens 的中间检查点,Moonlight 相较于使用 AdamW 训练的同类模型(称为 Moonlight-A)以及其他类似的 MoE 模型表现出适度改进。
- 在语言理解任务中,Moonlight 在 MMLU 等基准测试中取得了稍高的分数。
- 在代码生成任务中,其性能提升更为明显,表明 Muon 的精细更新机制有助于更好地完成特定任务。
2. 缩放定律实验
- 实验表明,Muon 可以在大约一半的训练计算成本下,匹配 AdamW 训练模型的性能。
- 权重矩阵的光谱分析显示,使用 Muon 训练的模型具有更多样化的奇异值范围,这可能有助于模型在各种任务中实现更好的泛化能力。
3. 微调阶段的研究
- 在监督微调阶段,研究表明当使用 Muon 进行预训练和微调时,优化器的优势在整个训练流程中持续存在。
- 如果在预训练和微调之间切换优化器,效果差异则不太明显,这表明优化方法的一致性是有益的。
未来展望
Moonlight 项目的开源预计将促进对可扩展优化技术的进一步研究。未来的工作可能包括:
- 扩展到其他范数约束:探索将 Muon 的优势应用于其他类型的范数约束。
- 统一优化框架:将 Muon 的特性集成到涵盖所有模型参数的统一优化框架中。
- 更高效的训练策略:开发更强大、更高效的训练策略,逐步塑造 LLM 开发的新标准。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











