来自大连理工大学、ZMO AI的研究人员提出了一种全新的图像、视频和3D定制生成模型StableIdentity,它能够将任何人的面部特征稳定地融入到各种不同的场景中。这项技术的核心在于,它能够通过一张单张照片来学习并保持人物的身份特征,然后在各种不同的背景和情境下生成新的图像。
更具体地说,StableIdentity使用一个带有身份先验的面部编码器来编码输入的面部,然后将面部表示投入到一个可编辑的先验空间中,该空间是由名人名字构建的。通过结合身份先验和可编辑性先验,学习到的身份可以被注入到各种上下文中。此外,该团队还设计了一个带屏蔽的两阶段扩散损失来增强对输入面部的像素级感知并保持生成的多样性。

主要特点:
- 单张照片学习:StableIdentity能够仅用一张面部照片来学习并保持人物的身份特征,这对于个性化图像生成来说是一个巨大的进步。
- 身份一致性:该模型生成的图像在保持人物身份特征的同时,还能够适应不同的文本提示,生成与文本相符的图像。
- 灵活的编辑性:StableIdentity不仅能够生成静态图像,还能够与现有的图像、视频和3D生成模型结合,实现更加灵活的定制化生成。
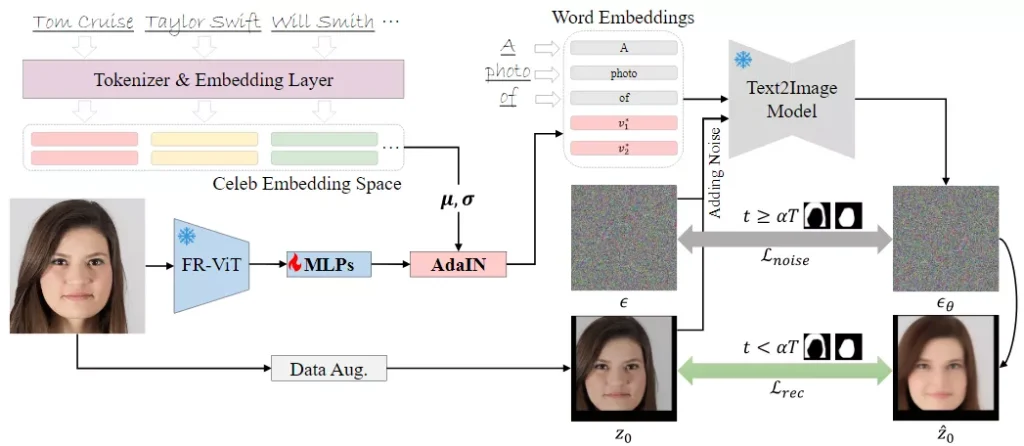
工作原理:
- 面部编码器:使用一个经过人脸识别任务训练的编码器(FR-ViT)来捕捉输入照片中的身份表示。
- 身份先验:通过将学习到的身份表示映射到一个由名人名字构成的嵌入空间中,这个空间包含了丰富的可编辑性先验知识。
- 两阶段扩散损失:设计了一个掩蔽的两阶段扩散损失函数,分别在去噪过程的早期和晚期阶段赋予不同的目标,以提高像素级别的细节感知并学习更稳定的身份。

具体应用场景:
- 个性化肖像照片:用户可以上传自己的照片,生成穿着不同服装或在不同场景下的个性化肖像。
- 虚拟试穿:在时尚和零售领域,StableIdentity可以用来生成用户穿着不同服装的图像,帮助用户在购买前预览效果。
- 艺术与设计:艺术家和设计师可以利用这项技术来创作包含特定人物特征的艺术作品或设计草图。
- 视频和3D生成:StableIdentity还可以与视频和3D生成模型结合,实现视频中人物身份的一致性,或者在3D模型中插入特定的人物特征。
StableIdentity是第一个直接将从一个图像中学习到的身份注入到视频/3D生成中而无需微调的模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...