
来自Meta和慕尼黑工业大学的研究人员推出ViewDiff,它能够根据文本描述或已有的图像输入,生成与3D对象一致的高质量图像。
想象一下,你只需要告诉计算机你想要的3D对象是什么样子,比如“一个穿着绿色帽子的泰迪熊坐在绿色的毯子上”,ViewDiff就能生成一系列从不同角度观看这个泰迪熊的逼真图片。

主要功能:
ViewDiff的核心功能是生成多视角一致的图像。这意味着无论你从哪个角度查看生成的图像,3D对象的外观都是一致的,就像在现实世界中观察一个真实物体一样。
主要特点:
- 3D一致性: 生成的图像在不同视角下保持一致性,确保了3D对象的真实感。
- 高质量渲染: 方法利用预训练的文本到图像模型,生成具有高分辨率和丰富细节的图像。
- 真实环境: 生成的图像不仅包括3D对象,还包括真实的背景环境,使得整个场景更加真实。
- 文本引导: 用户可以通过文本描述来指导图像的生成,提供了高度的可定制性。
工作原理:
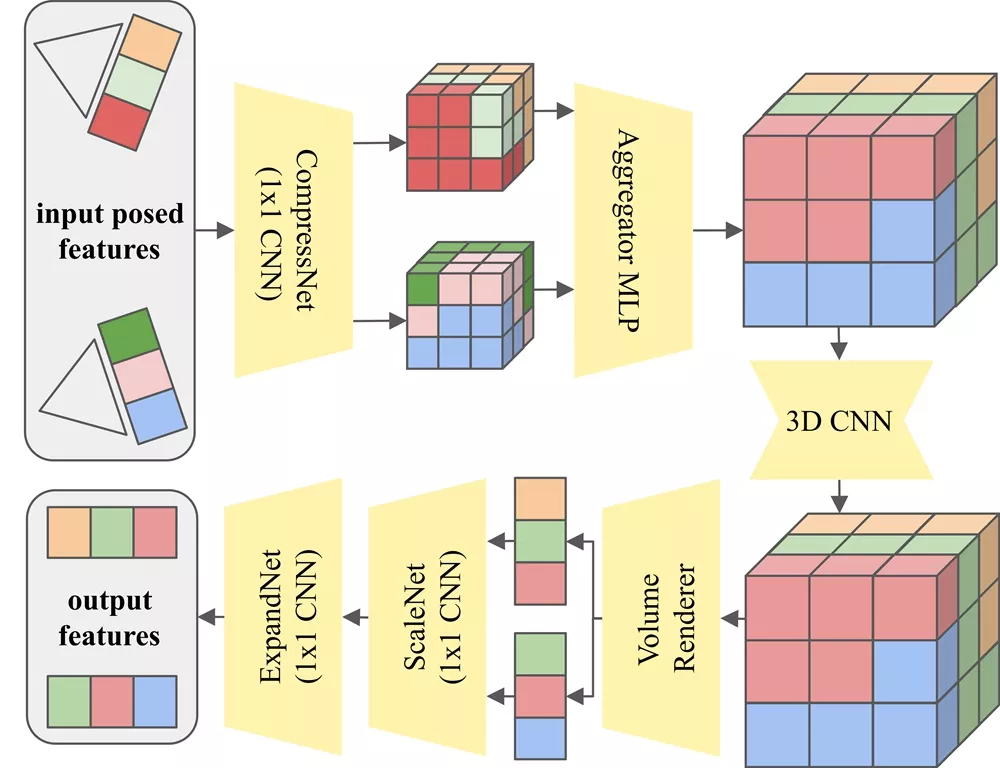
ViewDiff通过在现有的U-Net架构中添加新的层来实现其功能。这些新层包括跨帧注意力层和投影层,它们帮助模型在生成过程中保持3D一致性。在训练过程中,模型学习如何从多视角图像中提取特征,并使用这些特征来渲染出一致的3D对象。此外,ViewDiff还采用了自回归生成方案,允许模型在给定的视角上直接渲染新的图像。
应用场景:
- 3D建模: 艺术家和设计师可以使用ViewDiff快速创建3D模型的多视角图像,用于游戏开发、电影制作或虚拟现实。
- 增强现实(AR)和虚拟现实(VR): 在AR和VR应用中,ViewDiff可以用于生成逼真的3D对象图像,提高用户体验。
- 产品展示: 零售商可以使用ViewDiff生成产品的多角度视图,帮助顾客在线上更全面地了解产品。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











