中国科学技术大学、上海交通大学、香港中文大学和上海人工智能实验室的研究人员推出无需预先训练框架MotionClone,它能够实现一种无需训练的运动克隆,用于可控的视频生成。简单来说,这项技术可以让一个视频里的动作(比如一个人走路或者动物游泳)被“克隆”出来,并应用到另一个不同的场景中,同时保持与文本描述的高度一致性。MotionClone在多个标准数据集上进行了广泛的实验验证,包括心电图(ECG)和语音时间序列分类、长期和短期时间序列预测以及时间序列异常检测等任务,并展示了其在不同任务中的优越性能。
例如,一个导演想要在电影中加入一个角色在火星表面行走的场景,但实际拍摄成本太高或不可能实现,MotionClone可以帮助从现有的行走动作视频中克隆动作,并将其应用到新的火星场景中,从而生成逼真的视频片段。

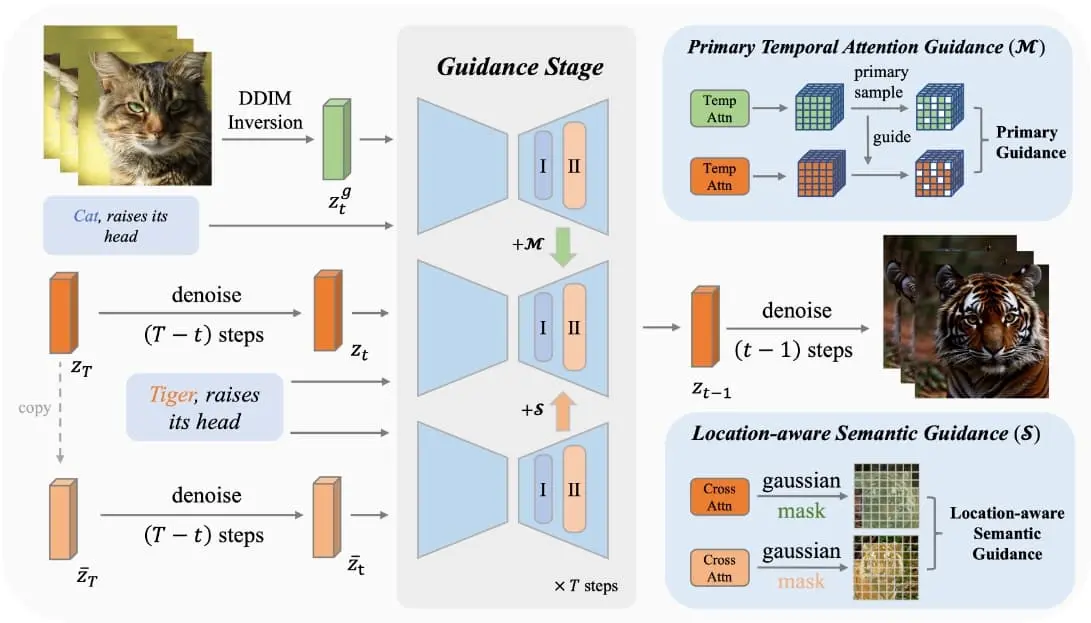
MotionClone运用视频倒置技术中的时间注意力机制来捕获参考视频中的动态要素,并设计了首要时间注意力引导策略,旨在减少注意力权重中杂乱或细微动作的干扰影响。为促进生成模型构建合理的空间布局并提升其遵循文本指令的效率,研究团队创新性地引入了一种关注位置的语义引导方法。此方法结合参考视频中前景的大致位置信息与基本的无分类器引导特性,共同优化视频的生成导向。大量实验证实,MotionClone不仅擅长处理全局摄像机移动和局部物体运动,而且在动作的真实度、与文本的契合度及时序一致性上,展现出了卓越的性能优势
主要功能:
- 运动克隆:将一个视频中的动作克隆到另一个视频中。
- 文本到视频的生成:根据文本提示生成视频,并且这些视频能够展现出与文本描述相符的动作。
主要特点:
- 无需训练:与以往需要大量训练数据和微调的方法不同,MotionClone不需要训练即可使用。
- 高运动保真度:克隆的动作在新视频中保持高度的真实性和一致性。
- 文本对齐:生成的视频能够与文本描述紧密对齐,确保动作与文本描述相符。
工作原理:
- MotionClone使用了一个称为时间注意力(temporal attention)的机制,这有助于捕捉参考视频中的运动信息。
- 它引入了一种主要时间注意力引导(primary temporal-attention guidance)方法,专注于时间注意力权重中的主要组成部分,以忽略噪声或微小的运动。
- 此外,它还提出了一种位置感知的语义引导(location-aware semantic guidance)机制,利用参考视频中的前景粗略位置和原始的无分类器引导特征来指导视频生成。
具体应用场景:
- 视频内容创作:在电影、电视和在线媒体中,可以根据剧本描述生成具有特定动作的视频内容。
- 虚拟现实和增强现实:在VR和AR应用中,可以根据用户的交互生成相应的动作反应。
- 教育和培训:在教育领域,可以生成演示特定动作或过程的教学视频。
- 游戏开发:在电子游戏中,可以根据玩家的操作或指令生成角色的动作。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...