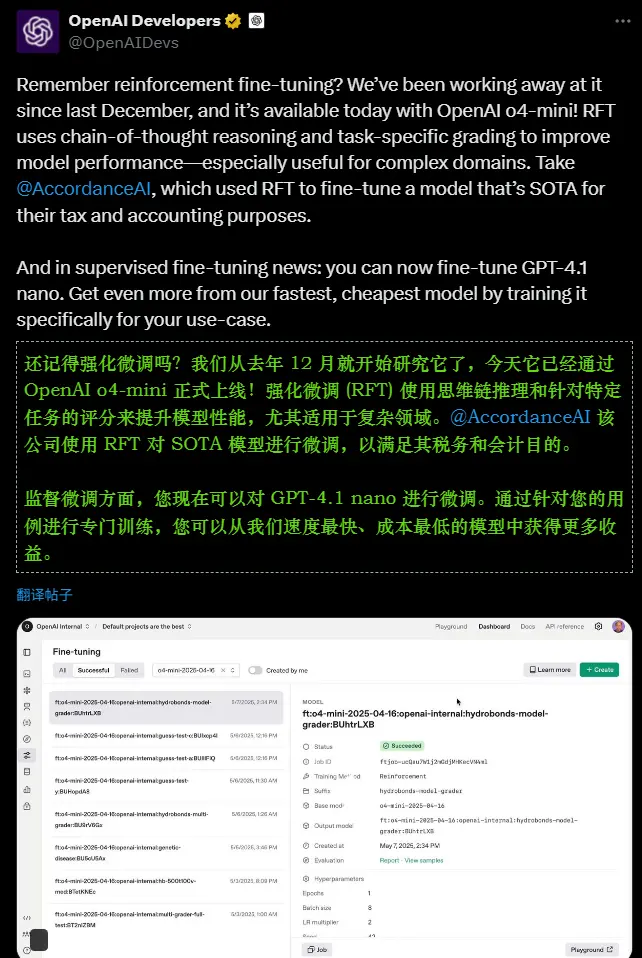
OpenAI今天宣布,第三方开发者现在可以通过强化学习(RFT)对o4-mini语言推理模型进行微调。这一功能的推出,使企业能够根据自身需求定制专属的私有版本,从而更好地服务于内部沟通、知识管理、任务自动化等场景。
相比传统的监督微调(SFT),RFT提供了更高的灵活性和控制力,尤其适合复杂且特定领域的任务。以下是关于这一新功能的详细解读,以及它如何为组织和企业带来价值。
RFT的核心功能与优势
RFT允许开发者通过反馈循环训练模型,使其更贴合企业的具体需求。以下是它的主要特点:
- 灵活的目标对齐:开发者可以通过定义评分函数,将模型输出与企业的“内部沟通风格”、术语、安全规则或政策合规性等目标对齐。例如,企业可以确保生成的内容符合内部文档风格或政策要求。
- 基于评分的优化机制:RFT通过评分模型为每个提示的多个候选回答打分,并调整模型权重以提高高分输出的概率。这种方法比传统的监督学习更具动态性,能够适应复杂的业务场景。
- 简单易用的工具链:开发者可以通过OpenAI的在线平台轻松启动RFT流程,包括上传数据集、配置训练任务、监控进度等。整个过程相对高效且成本可控。
- API部署支持:微调后的模型可以通过API集成到企业的内部系统中,用于聊天机器人、知识库检索、文档生成等场景。
适用场景与早期案例
OpenAI分享了多个跨行业的早期客户案例,展示了RFT在不同领域的实际应用效果:
- 税务分析:Accordance AI使用RFT微调模型处理复杂的税务分析任务,准确率提升了39%,性能超越其他领先模型。
- 医疗代码分配:Ambience Healthcare将RFT应用于ICD-10医疗代码分配,在金标数据集上的表现比医生基线高出12个百分点。
- 法律文档分析:Harvey利用RFT优化模型,提取法律文档中的引用信息,F1分数提高了20%,同时推理速度更快。
- 代码生成:Runloop通过RFT改进Stripe API代码片段生成,性能提升12%。
- 内容审核:SafetyKit使用RFT执行细致的内容审核政策,生产环境中模型的F1分数从86%提升至90%。
这些案例表明,RFT特别适合具有明确任务定义、结构化输出格式和可靠评估标准的场景。
使用RFT的步骤
如果您计划尝试RFT,可以按照以下步骤操作:
- 定义评分函数:确定如何评估模型输出的质量,可以选择OpenAI提供的评分器,也可以使用自定义评分逻辑。
- 准备数据集:上传包含提示和验证分割的数据集,确保数据质量高且与目标任务相关。
- 配置训练任务:使用OpenAI的API或微调仪表板设置训练任务,指定参数并启动训练。
- 监控与迭代:实时监控训练进度,审查检查点,并根据需要调整数据或评分逻辑。
定价与成本控制建议
RFT采用按训练时间计费的模式,具体费用如下:
- 核心训练时间:每小时100美元(按秒比例计算)。
- 仅对修改模型的工作收费,排队、安全检查和空闲阶段不计费。
- 如果使用OpenAI模型作为评分器,评分期间的推理令牌费用按标准API费率单独计费。
为了降低成本,OpenAI建议团队采取以下措施:
- 使用轻量或高效的评分器。
- 避免不必要的频繁验证。
- 从小规模数据集或短时间运行开始,逐步校准预期。
- 利用API或仪表板工具实时监控训练进度。
注意事项与潜在风险
尽管RFT提供了强大的定制能力,但微调后的模型可能存在越狱和幻觉问题,因此需要谨慎操作。此外,成功的RFT项目依赖于高质量的数据和明确的任务定义,开发者应确保数据的可靠性和评估标准的科学性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











