在生成式 AI 领域,“大力出奇迹”的规模法则(Scaling Law)似乎是不可动摇的铁律。然而,Liquid AI 今日发布的 LFM2.5-350M 向这一传统观念发起了有力挑战。这是一个仅有 3.5 亿参数 的紧凑模型,却通过在 28 万亿 token 上的海量预训练和创新的架构设计,实现了惊人的“智能密度”,在多项基准测试中超越了比它大两倍以上的模型。
- 官方介绍:https://www.liquid.ai/blog/lfm2-5-350m-no-size-left-behind
- 模型:https://huggingface.co/LiquidAI/LFM2.5-350M
LFM2.5-350M 不仅仅是一个模型,更是一份关于如何在资源受限的边缘设备上实现高效智能的技术宣言。
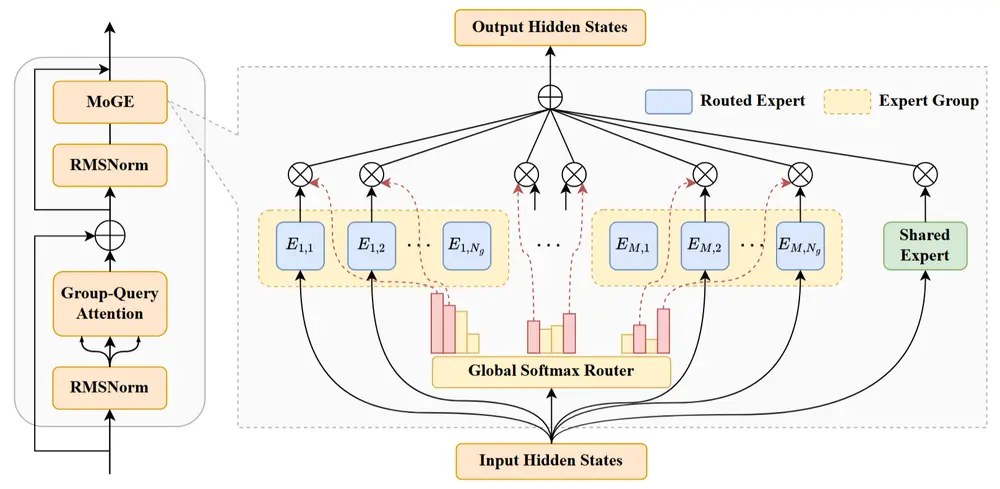
核心突破:告别纯 Transformer,拥抱混合架构
LFM2.5-350M 的最大亮点在于其彻底脱离了传统的纯 Transformer 架构,转而采用了一种基于 线性时变系统(Linear Time-Varying, LIV) 的混合主干网络。
1. 混合 LIV 主干网
为了解决 Transformer 自注意力机制随上下文长度呈平方级增长的内存瓶颈,Liquid AI 设计了独特的双层结构:
- 10 个双门控 LIV 卷积块:作为主力军,处理绝大部分序列信息。LIV 块类似于高级 RNN,拥有恒定的状态内存,不仅训练时可并行化,推理时更无需庞大的 KV 缓存,极大降低了 I/O 开销。
- 6 个分组查询注意力(GQA)块:作为“精兵”,穿插其中以保留高精度的长距离依赖捕捉能力和检索精度,同时避免了标准 Attention 的高昂成本。
2. 32k 上下文与极低显存
得益于 LIV 架构,LFM2.5-350M 原生支持 32,768 (32k) token 的超长上下文窗口,却仅需极小的内存占用。这使其成为处理长文档、日志分析或复杂对话历史的理想选择,而无需担心显存爆炸。
性能表现:小身材,大能量
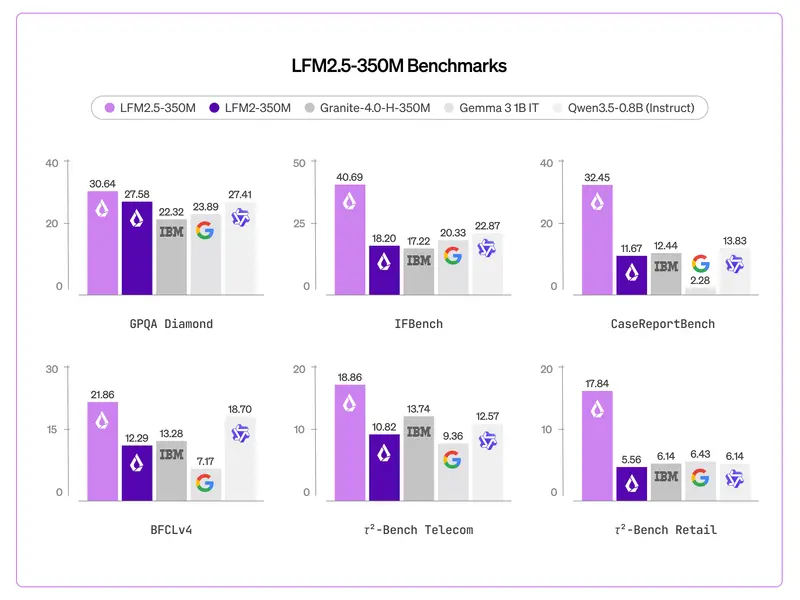
1. 极高的智能密度
- 训练数据量:28 万亿 token(是同类小模型的数倍)。
- Token/参数比:高达 80,000:1。这种“饱和式训练”榨干了每一个参数的潜力。
- 基准成绩:
- IFEval (指令遵循):76.96 —— 表现卓越,擅长结构化任务。
- GPQA Diamond:30.64
- MMLU-Pro:20.01
2. 定位明确:边缘智能体专家
Liquid AI 明确指出,LFM2.5-350M 不是 为了替代大模型进行复杂数学推理、高阶编码或创意写作。它的核心优势在于:
- 指令遵循:完美执行结构化命令。
- 工具使用与函数调用:快速解析并调用 API。
- 数据提取:从非结构化文本中高效提取 JSON 等格式数据。
- 实时分类与路由:作为大模型前的“守门人”,快速处理简单请求。
边缘部署:打破“内存墙”
LFM2.5-350M 专为本地化和移动端部署而生,其低内存特性令人咋舌:
| 硬件平台 | 推理引擎 | 峰值内存占用 | 意义 |
|---|---|---|---|
| Snapdragon GPU | RunAnywhere Q4 | 81 MB | 可在低端手机后台常驻运行 |
| Snapdragon NPU | RunAnywhere Q4 | 169 MB | 利用专用 NPU 实现低功耗推理 |
| Raspberry Pi 5 | Cactus Engine int8 | 300 MB | 让树莓派也能跑 32k 上下文大模型 |
| NVIDIA H100 | 原生 | 40.4K tokens/s | 单卡超高吞吐,适合大规模并发处理 |
对比:同等上下文长度的传统 Transformer 小模型,其 KV 缓存往往需要数倍于此的内存,难以在移动端流畅运行。
应用场景推荐
鉴于其特性,LFM2.5-350M 最适合以下场景:
- 端侧智能助手:在手机、IoT 设备上运行本地语音助手或自动化脚本,无需联网,保护隐私。
- RAG 前置路由器:在检索增强生成系统中,先用 LFM2.5-350M 快速理解用户意图、提取关键词或重写查询,再交给大模型生成,大幅降低整体成本。
- 结构化数据清洗:批量处理日志、报表,提取关键指标并转换为 JSON/CSV 格式。
- 实时内容审核:利用高吞吐和低延迟,对海量流式数据进行即时分类和过滤。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











