周一,华为宣布一项重大举措:开源其盘古70亿参数(7B)密集模型和720亿参数(72B)Pro MoE混合专家模型,以及基于昇腾平台的高效推理技术。
这一动作被视为华为持续推进大型AI模型研究与产业应用的关键步骤,旨在加速人工智能在各行各业的价值创造,并进一步拓展昇腾生态系统的影响力。
开源内容概览
目前,华为已在开源平台上发布了以下资源:
- 盘古 Pro MoE 72B 模型权重
- 基础推理代码
- 基于昇腾的大型 MoE 模型推理实现
此外,盘古7B模型的权重与推理代码也将于近期上线。
华为诚邀全球开发者、研究人员和企业合作伙伴下载使用这些资源,共同参与测试、反馈和优化工作,共建开放的AI生态体系。
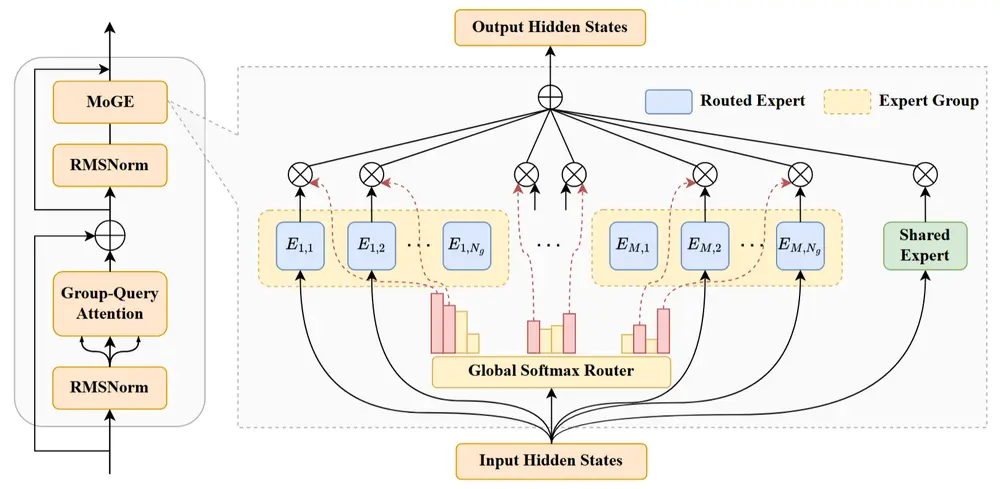
盘古 Pro MoE:昇腾原生的大规模混合专家模型
盘古 Pro MoE 是华为盘古团队提出的一种面向大规模训练和推理的分组混合专家模型(Mixture of Grouped Experts, MoGE),具有以下核心特点:
模型架构创新:MoGE 架构
传统 MoE(Mixture of Experts)模型存在设备间负载不均衡的问题,影响训练效率。为此,华为提出了 MoGE 架构,其核心思想是:
- 将所有专家划分为多个组
- 每个 token 在每组中激活相同数量的专家
- 实现设备间的天然负载均衡
该设计使得模型既能保持高参数量带来的表达能力,又能有效利用硬件资源,提升训练与推理效率。
关键参数如下:
| 参数 | 数值 |
|---|---|
| 总参数量 | 720 亿 |
| 激活参数量 | 160 亿 |
| 层数 | 48 |
| 词表大小 | 153,376 |
| MoGE 配置 | 4 个共享专家,64 个路由专家,分成 8 组,每组激活 1 个专家 |
训练与推理优化策略
为了充分发挥 MoGE 架构的潜力,华为从训练、系统、算法和算子等多个层面进行了深度优化。
🔧 训练优化
- 数据规模:采用 13 万亿 token 的多源语料库进行训练
- 训练阶段:
- 第一阶段:通用预训练
- 第二阶段:推理增强训练
- 第三阶段:退火调整
- 微调方法:结合监督微调(SFT)与强化学习(RL),提升模型表现
- 昇腾优化:
- 分层 EP All-to-All 通信
- 自适应流水掩盖技术
- 显著提升 NPU 算力利用率
⚙️ 推理优化
华为对推理过程进行了全方位优化,确保在昇腾平台上实现高效部署:
- 系统层面:
- 分层混合并行
- 通信优化
- 算法层面:
- 使用量化压缩技术,降低内存占用
- 算子层面:
- 开发 MulAttention 和 SwiftGMM 算子,显著提升推理速度
实验结果:性能领先,推理高效
在多个主流基准测试中,盘古 Pro MoE 表现出色,包括但不限于:
- C-Eval
- MMLU
特别是在推理性能方面:
| 平台 | 吞吐量(tokens/s) |
|---|---|
| 昇腾 800I A2(单卡) | 原始:1148 / 优化后:1528 |
| 昇腾 300I Duo | 推理性价比显著优于同类方案 |
这些结果验证了 MoGE 架构在千亿级模型中的可行性与领先优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...