
阿里通义实验室正式发布 Tongyi DeepResearch —— 一个在性能上可与当前最先进闭源系统相媲美的全开源 Web Agent。
- 项目主页:https://tongyi-agent.github.io/zh/blog/introducing-tongyi-deep-research
- GitHub:https://github.com/Alibaba-NLP/DeepResearch
- Hugging Face:https://huggingface.co/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B
- 魔塔:https://modelscope.cn/models/iic/Tongyi-DeepResearch-30B-A3B
它不仅在多个高难度信息检索与推理基准中取得领先成绩,更完整公开了从数据构建、预训练到强化学习的端到端训练方法论。这是业界首次将如此复杂且高性能的智能体系统全面开放,旨在推动 AI Agent 领域向更高水平演进。
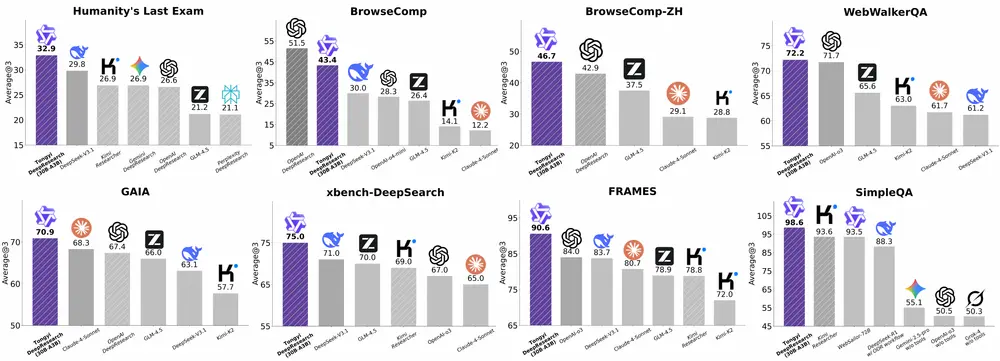
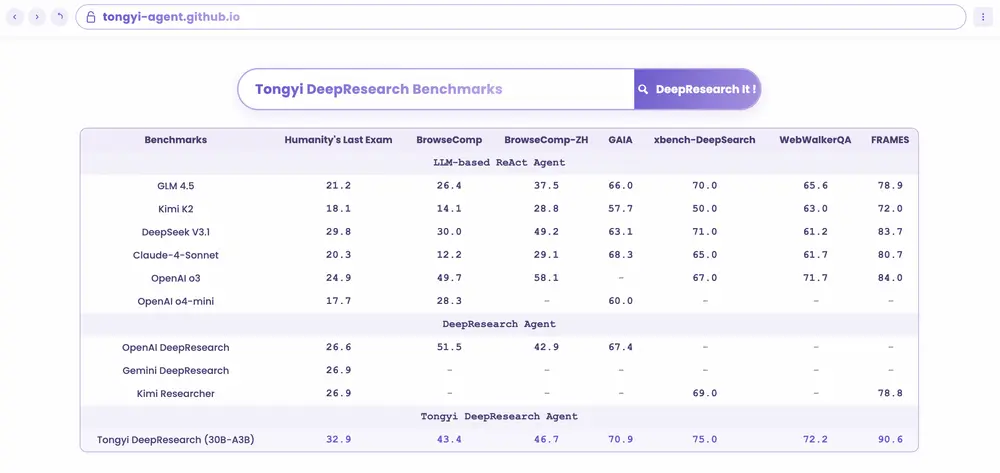
关键性能指标(SOTA 级别)
| 基准测试 | 得分 |
|---|---|
| Humanity’s Last Exam (HLE) | 32.9 |
| BrowseComp-EN | 45.3 |
| BrowseComp-ZH | 49.5 |
| xBench-DeepSearch | 75.0 |
在所有四项任务中均超越现有闭源与开源 Agent,达到当前最优水平。
为什么需要真正的“深度研究型”Agent?
今天的大多数大模型擅长回答静态知识问题,但在面对真实世界复杂任务时往往力不从心:
- 如何综合多网页内容判断某项政策的实际影响?
- 如何通过跨源数据验证一个学术假设?
- 如何在模糊线索下持续探索并得出可信结论?
这些问题要求模型具备长期规划、工具调用、动态记忆管理和抗噪声推理能力——而这正是 Web Agent 的核心使命。
Tongyi DeepResearch 正是为此类任务而生。它是一个拥有 300亿总参数、每 token 激活 30亿参数的稀疏激活模型,专为长期、多步、高复杂度的信息搜索任务设计。
核心能力概览
| 维度 | 能力说明 |
|---|---|
| ✅ 全面开源 | 完整模型 + 训练流程 + 数据合成方案全部公开 |
| 🔍 深度推理 | 支持 ReAct 与 IterResearch 双模式,兼顾基础能力与上限探索 |
| 🧠 自主决策 | 具备长期记忆管理、上下文重构和多路径探索机制 |
| ⚙️ 工具使用 | 稳定调用搜索、浏览、代码执行等外部工具 |
| 🌐 多语言支持 | 中英文场景下均表现优异,尤其在中文任务中领先明显 |
技术突破:不止于模型,更是方法论的革新
Tongyi DeepResearch 的成功并非来自单一模块优化,而是源于一套完整的、可复现的 Agent 构建体系。我们将其总结为三个关键阶段:
Agentic CPT → Agentic SFT → Agentic RL
这一端到端流程覆盖了从基座模型初始化到自我进化的全过程。
第一阶段:智能体增量预训练(Agentic CPT)
传统预训练关注通用语料理解,而我们在其中引入了 Agentic Continual Pre-training(CPT),专门用于培养模型的基础工具使用能力和环境交互直觉。
为此,我们开发了 AgentFounder —— 一套全自动、可扩展的数据合成流水线,基于以下来源生成高质量代理交互数据:
- 开放知识图谱与维基百科快照
- 后训练过程中积累的轨迹数据
- 工具调用返回结果(如网页摘要、搜索响应)
- 结构化表格与跨站关联信息
这些数据被组织成以实体为中心的“开放世界知识记忆”,并通过采样构造多样化的问题-答案对,模拟真实研究场景。
动作合成策略
我们构建了三类动作数据以丰富行为空间:
- 单步推理动作:如“根据网页A推断X事件发生在Y之前”
- 多步决策动作:还原完整任务链路,例如“先查定义 → 再找案例 → 最后对比差异”
- 规划扩展动作:通过对原始轨迹进行反向工程与扩展,激发模型探索未知路径的能力
该过程完全离线运行,无需依赖昂贵的商业API或人工标注。
第二阶段:监督微调(SFT)冷启动
为了快速建立初步行为规范,我们采用高质量合成数据进行有监督微调。
我们的核心方法是 High-quality QA 合成引擎,其流程如下:
- 问题生成
基于知识子图或融合表格数据,随机游走生成初始问答对; - 难度控制
引入“原子操作”理论框架,通过合并相似实体、模糊关键信息等方式系统提升问题复杂度; - 结构建模
使用集合论形式化建模信息搜索问题,减少推理捷径,增强逻辑严密性; - 自动验证
利用形式化规则高效校验答案正确性,解决合成数据难以评估的难题。
此外,我们还构建了 学术级复杂问题生成器:
- 从多学科知识库提取“种子”问题;
- 交由配备搜索、Python 执行和文献检索能力的 Agent 进行迭代升级;
- 每轮输出作为下一轮输入,形成“认知螺旋上升”循环。
这种方式能稳定生成博士级别研究任务,显著拉高模型能力天花板。
第三阶段:端到端强化学习(RL)
强化学习是让 Agent 实现自我进化的核心环节。我们采用严格 on-policy 的在线策略训练,并在算法与基础设施层面做了多项创新。
算法设计亮点
- 基于 GRPO 的定制化框架:确保策略更新与当前能力匹配;
- Token-level 策略梯度损失:精细化优化每一步决策质量;
- Leave-one-out 优势估计:有效降低方差,提高学习稳定性;
- 选择性负样本过滤:排除因超长未完成而导致的无效样本,防止格式崩溃。
训练动态显示,奖励持续上升,策略熵保持高位,表明模型始终处于积极探索状态,未出现早收敛。
基础设施保障
我们认为:数据质量和环境稳定性比算法本身更重要。
因此我们构建了四大支撑系统:
| 系统 | 功能 |
|---|---|
| 🧪 仿真训练环境 | 基于离线维基数据库 + 自定义工具集,实现高速、可控、低成本训练 |
| 🛠️ 统一工具沙盒 | 缓存、重试、限流一体化处理,并发调用稳定可靠 |
| 📊 自动数据管理 | 实时监控训练反馈,动态调整数据分布,形成“数据-模型”正向飞轮 |
| 🔁 异步训练框架 | 基于 rLLM 实现多实例并行交互,大幅提升采样效率 |
这套基础设施使得 RL 训练不再是“黑箱实验”,而成为可预测、可调试、可持续迭代的工程流程。
推理范式:两种模式,双重价值
Tongyi DeepResearch 支持两种部署模式,分别服务于不同目标。
1. ReAct 模式:衡量模型“本色”
- 严格遵循“思考 → 行动 → 观察”循环;
- 上下文长度达 128K,支持百轮以上交互;
- 不依赖任何提示工程,直接展现模型原生能力;
- 是评估 Agent 核心能力的黄金标准。
我们坚持 ReAct 设计,深受“The Bitter Lesson”启发:可扩展的通用方法终将胜过依赖人工雕琢的复杂设计。
2. 深度模式(IterResearch):释放最大潜力
针对极端复杂的长期任务,我们提出全新推理范式 —— IterResearch。
解决什么问题?
传统 Agent 将所有信息堆在一个不断增长的上下文中,导致:
- “认知过载”:重要信息被淹没;
- “噪音污染”:无关历史干扰当前判断。
如何工作?
IterResearch 将任务拆解为多个“研究轮次”:
- 每轮仅保留上一轮最关键的发现;
- 重建一个精简的工作空间;
- 在此空间内重新分析问题、整合证据、决定下一步行动;
- 输出一份逐步演进的“核心报告”。
这种“综合→重构”的机制,使 Agent 能在整个过程中保持清晰的认知焦点。
升级版:“研究-合成”框架
进一步地,我们支持多个 Agent 并行使用 IterResearch 探索同一问题的不同路径,最后汇总各自报告,生成更全面的答案。
这相当于为 AI 提供了“团队协作”能力,在有限上下文窗口内实现更广的探索覆盖。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











