中科院大学、华南理工大学、斯坦福大学的研究人员推出一种名为 MACHINELEARNINGLM 的新型框架,旨在通过持续预训练(continued pretraining)提升大语言模型(LLMs)在多示例上下文学习(many-shot in-context learning, ICL)中的表现,特别是在处理表格数据时的推理能力。
- GitHub:https://github.com/HaoAreYuDong/MachineLearningLM
- 模型:https://huggingface.co/MachineLearningLM/MachineLearningLM-7B-v1
MACHINELEARNINGLM是一个基于持续预训练的框架,能够使通用语言模型在保持其通用知识和推理能力的同时,具备强大的多示例上下文学习能力,特别是在表格数据的机器学习任务中表现出色。
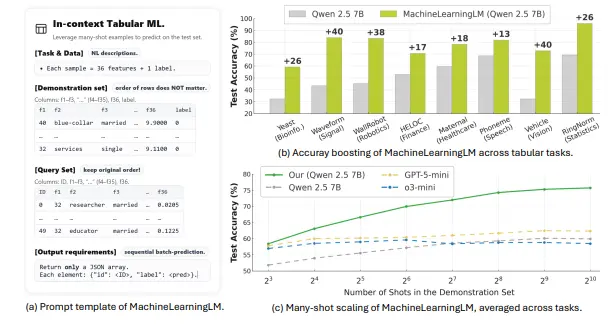
例如,在一个包含多个特征和标签的表格数据集中,MACHINELEARNINGLM 可以通过上下文中的多个示例(如 8 到 1,024 个)来学习和预测新的实例,而无需通过梯度下降进行微调。这使得模型能够更好地理解和处理复杂的表格数据,如金融、生物学、物理学和医疗保健领域的分类任务。
主要功能
- 多示例上下文学习:MACHINELEARNINGLM 能够利用上下文中的多个示例来学习和预测,支持从 8 到 1,024 个示例的多示例学习。
- 保持通用知识和推理能力:在提升表格数据处理能力的同时,模型保留了其在通用对话和推理任务中的能力。
- 跨领域适应性:该框架在多个领域(如金融、生物学、物理学和医疗保健)的分类任务中表现出色,具有良好的跨领域适应性。
主要特点
- 基于因果结构模型(SCM)的合成任务:通过从因果结构模型中合成大量的表格预测任务,确保预训练数据的多样性和丰富性。
- 随机森林教师模仿:在预训练初期,通过模仿随机森林教师的行为来增强模型在数值建模中的鲁棒性。
- 高效的上下文编码:采用紧凑的表格编码和整数化的数字编码,显著提高了上下文窗口内的示例数量,同时减少了计算成本。
- 顺序级批预测:通过将多个测试示例打包到一个序列中进行预测,提高了推理效率并减少了指令/上下文开销。
- 顺序鲁棒性:在推理时,通过随机打乱上下文示例的顺序并结合置信度加权的一致性投票,提高了模型对上下文顺序的鲁棒性。
工作原理
- 预训练数据合成:从因果结构模型(SCM)中合成大量的表格预测任务,涵盖不同的特征类型、边际分布和标签机制。
- 随机森林教师模仿:在预训练的初期阶段,通过模仿随机森林教师的预测结果来训练模型,增强其在数值建模中的鲁棒性。
- 高效的上下文编码:采用紧凑的表格编码和整数化的数字编码,将数值特征归一化到 [0,999] 范围内,减少上下文长度限制,提高上下文窗口内的示例数量。
- 顺序级批预测:将多个测试示例打包到一个序列中进行预测,通过批量推理提高推理效率并减少指令/上下文开销。
- 顺序鲁棒性:在推理时,通过随机打乱上下文示例的顺序并结合置信度加权的一致性投票,提高模型对上下文顺序的鲁棒性。
测试结果
- 多示例学习能力:MACHINELEARNINGLM 在多示例上下文学习中表现出色,随着上下文示例数量的增加,模型的准确性单调增加,从 8 到 1,024 个示例,平均比基线模型(如 Qwen-2.5-7B-Instruct)提高了约 15%。
- 与传统方法的比较:在多个领域(如金融、生物学、物理学和医疗保健)的分类任务中,MACHINELEARNINGLM 的表现接近随机森林水平,甚至在某些任务上超过了随机森林。
- 跨领域泛化能力:模型在不同领域的任务中表现出良好的泛化能力,尤其是在长文本上下文和多示例学习中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











