
在大语言模型(LLM)处理长文本时,两个核心问题始终存在:计算开销高 和 中间信息丢失严重。为了解决这些问题,阿里通义实验室 Qwen-Doc 团队推出了一个全新上下文压缩框架 —— QwenLong-CPRS。
- GitHub:https://github.com/Tongyi-Zhiwen/QwenLong-CPRS
- Hugging Face:https://huggingface.co/Tongyi-Zhiwen/QwenLong-CPRS-7B
- 魔塔:https://modelscope.cn/models/iic/QwenLong-CPRS-7B
这个系统不是简单的优化,而是一次从架构到机制的深度重构。它不仅显著提升了处理效率,还大幅增强了模型在超长上下文下的准确性,成为当前该领域最前沿的解决方案之一。
为了推动技术落地,阿里正式开源了 QwenLong-CPRS 的首个版本 —— QwenLong-CPRS-7B,适用于各种需要长上下文处理的场景。
主要特性包括:
- 支持与主流 LLM 的无缝对接
- 极低资源占用,适合部署于多种硬件环境
- 即插即用,无需调整原有模型结构
什么是 QwenLong-CPRS?
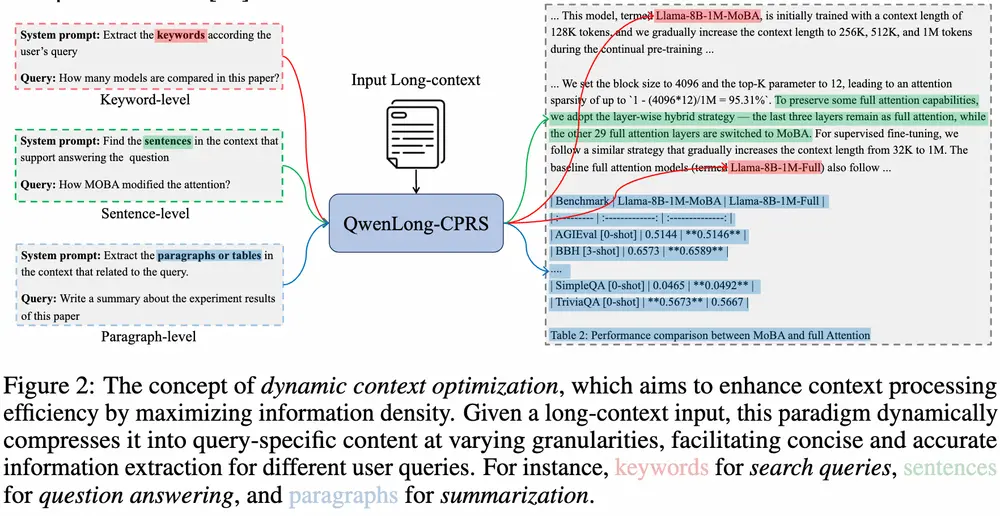
QwenLong-CPRS 是一个专为显式长上下文优化设计的上下文压缩框架。它基于自然语言指令驱动,能够在不重新训练主模型的前提下,实现对输入内容的多粒度压缩和高效利用。
换句话说,它让大模型“挑重点看”,而不是盲目地处理所有输入文本。
核心优势:三重提升
✅ 更高的准确性
QwenLong-CPRS 不像 RAG 那样进行粗粒度的块级检索,也不依赖稀疏注意力那样的复杂训练机制。它通过标记级的内容选择机制,保留关键信息,去除冗余内容,从而显著提升准确率。
✅ 更强的效率
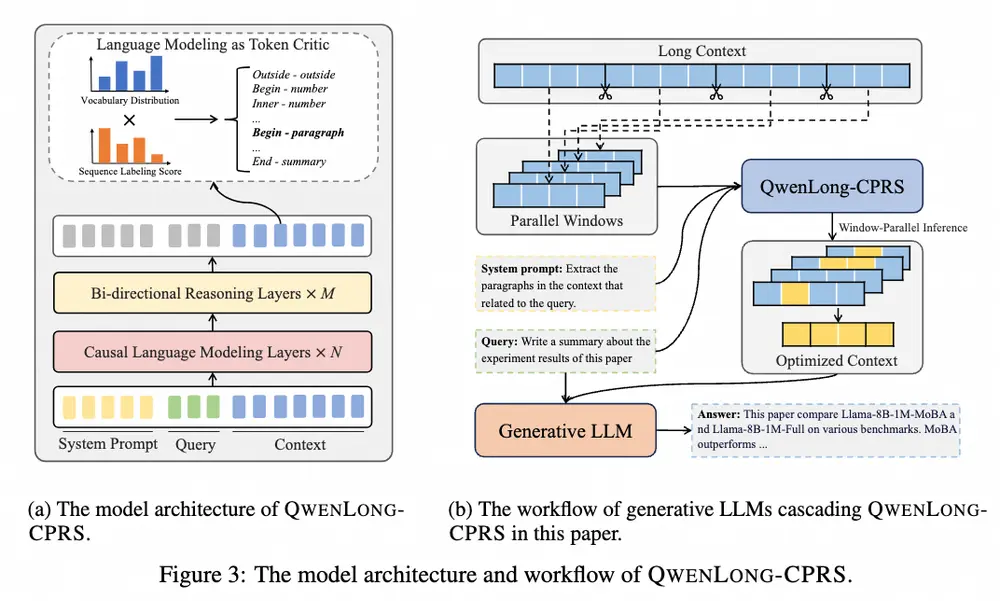
面对动辄数万、甚至上百万字的长上下文,传统方法往往卡顿明显。而 QwenLong-CPRS 引入了窗口并行推理机制,将长文本拆分成多个窗口并行处理,极大降低了预填充阶段的计算复杂度。
✅ 更广的兼容性
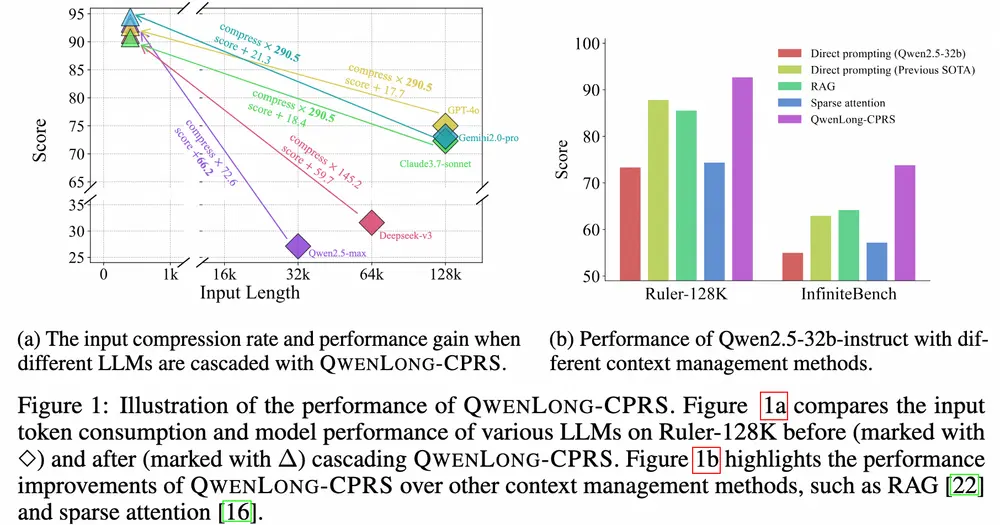
这是 QwenLong-CPRS 最具实用价值的一点:它是一个即插即用模块,无需对主模型进行任何改动或再训练,即可无缝集成到 GPT-4o、Gemini 2.0-pro、Claude 3.7-sonnet、DeepSeek-v3、Qwen2.5-max 等主流 LLM 中。
技术亮点:四项创新机制
- 自然语言引导的动态优化
- 用户只需提供控制提示 + 查询语句,系统就能自动生成紧凑且任务相关的上下文片段。
- 无需额外训练,适配性强。
- 增强边界感知的双向推理层
- 在上下文中精确定位关键位置,避免“中间丢失”问题。
- 提升模型对上下文边界的理解能力。
- 带语言建模头的标记批评机制(LM-as-Critic)
- 利用已有语言模型头部对标记相关性打分,决定哪些内容应被保留。
- 在压缩的同时保持知识完整性。
- 窗口并行推理机制
- 将长上下文划分为固定大小的窗口,进行并行处理。
- 显著降低计算资源消耗,提升响应速度。
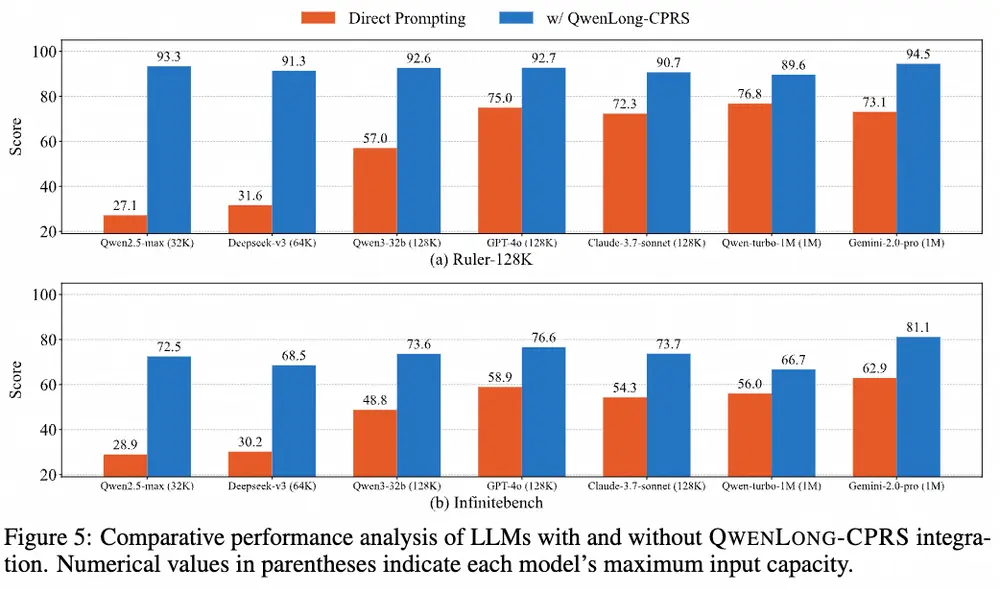
实测表现:全面领先
在五个不同长度的基准测试中(涵盖 4K 到 200 万字上下文),QwenLong-CPRS 表现亮眼:
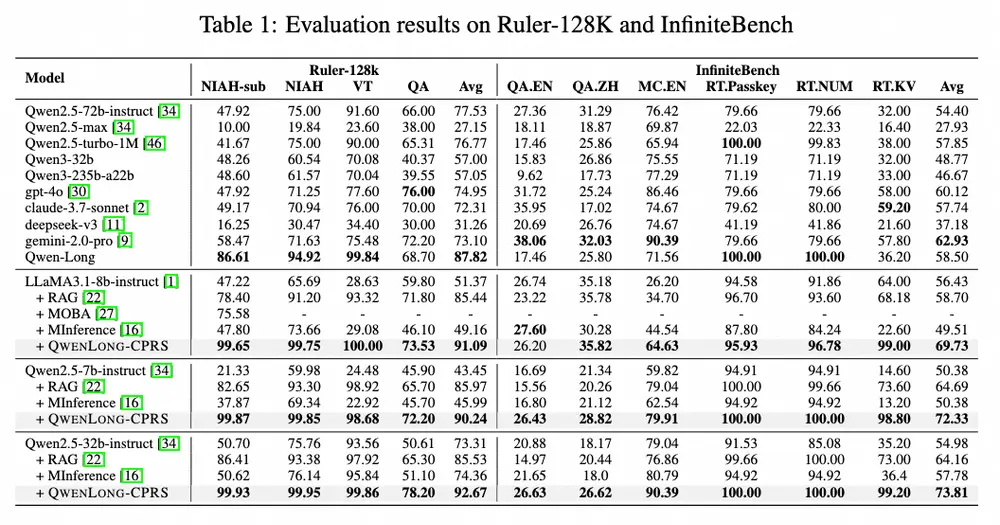
- 性能提升:在多个长文本基准测试中,QWENLONG-CPRS 显著提升了模型的性能。例如,在 Ruler-128K 数据集上,QWENLONG-CPRS 使 Qwen2.5-7b-Instruct 模型的性能提升了 39.72%,在 InfiniteBench 数据集上提升了 13.30%。
- 效率提升:QWENLONG-CPRS 在长文本处理中表现出线性扩展的效率,显著减少了计算开销。例如,在 128K 令牌的输入下,QWENLONG-CPRS 的延迟比直接提示方法减少了 3.47 倍。
- 多粒度优化:QWENLONG-CPRS 支持关键词、句子、段落等多种粒度的上下文压缩,适应不同的任务需求。例如,在 Needle-in-a-Haystack 任务中,QWENLONG-CPRS 能够在 1M 令牌的输入中完美地提取关键信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











