
腾讯混元团队发布了其自研的快思考模型 Turbo S ,并在腾讯云官网上架,开发者和企业用户可通过 API 调用体验。同时,该模型从今天起在腾讯元宝平台灰度上线,供广大用户体验。
Turbo S:秒回体验,性能全面提升
2月27日,腾讯混元正式推出 Turbo S 模型。作为一款“快思考”模型,Turbo S 与 Deepseek R1、混元 T1 等需要“深思熟虑”的慢思考模型形成鲜明对比。Turbo S 的核心优势在于:
- 响应速度更快 :吐字速度提升一倍,首字时延降低 44%,真正实现“秒回”。
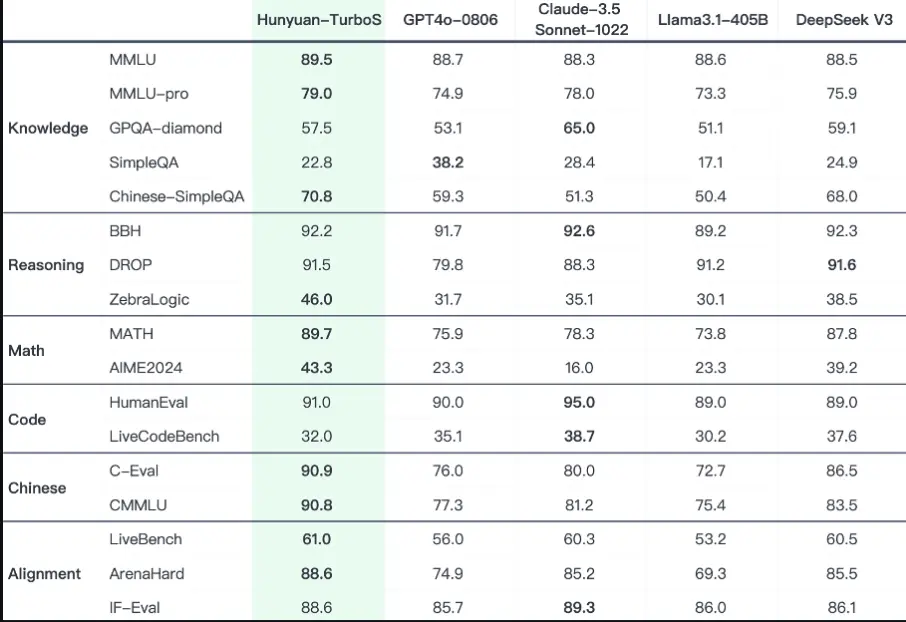
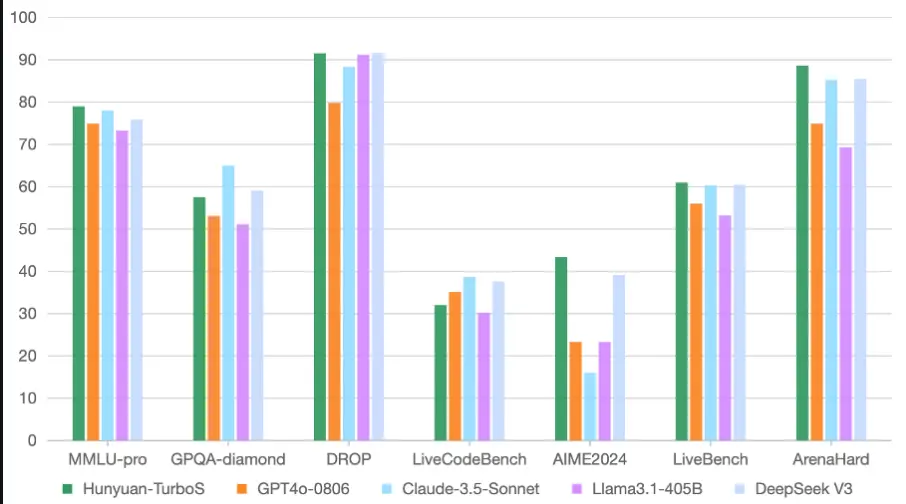
- 能力全面 :在知识问答、数理逻辑、内容创作等领域表现出色,媲美业界领先的 DeepSeek V3、GPT-4o 和 Claude 3.5 等模型。
- 成本更低 :通过架构创新,Turbo S 的部署成本大幅下降,进一步降低了大模型的应用门槛。
研究表明,人类约 90%-95% 的日常决策依赖直觉(快思考),而仅在复杂场景中启用理性分析(慢思考)。Turbo S 的设计正是基于这一理念,为通用场景提供快速响应能力,而慢思考模型则专注于深度推理和复杂问题解决。两者的结合让大模型更智能、更高效。
长短思维链融合:文科与理科能力兼备
为了兼顾文科类问题的快速响应和理科推理的深度需求,Turbo S 采用了长短思维链融合技术 :
- 短思维链 :优化快思考体验,确保在通用场景下快速响应。
- 长思维链 :基于自研混元 T1 慢思考模型生成的数据,显著提升了理科推理能力。
这种融合不仅让 Turbo S 在文科领域保持流畅体验,还在数学、推理等理科任务上实现了显著突破,整体效果大幅提升。
Hybrid-Mamba-Transformer 架构:效率与性能的双赢
Turbo S 的另一大亮点是其创新的Hybrid-Mamba-Transformer 融合架构 。这一架构有效解决了传统 Transformer 模型在处理长文本时面临的高计算复杂度和高显存占用问题:
- Mamba 的高效性 :擅长处理长序列数据,显著降低 KV-Cache 缓存占用。
- Transformer 的灵活性 :保留捕捉复杂上下文关系的优势。
- 混合架构优势 :兼具显存与计算效率,构建了工业界首个成功将 Mamba 架构无损应用于超大规模 MoE(混合专家)模型的案例。
通过这一架构创新,Turbo S 不仅降低了训练和推理成本,还突破了传统 Transformer 模型在长文处理上的瓶颈,为未来大模型的发展提供了新的方向。
Turbo S:混元系列的核心基座
作为混元系列的旗舰模型,Turbo S 将成为未来衍生模型的核心基座,为推理、长文、代码等专用模型提供基础能力。例如:
- 推理模型 T1 :基于 Turbo S 开发,通过引入长思维链、检索增强和强化学习等技术,已在腾讯元宝上线。用户可以选择使用 Deepseek R1 或混元 T1 模型进行回答。
- 正式版 T1 API :腾讯混元表示,T1 模型的正式版 API 即将上线,对外提供接入服务。
定价与试用:普惠开发者与企业
即日起,开发者和企业用户可以在腾讯云上通过 API 调用 Turbo S 模型,并享受为期一周的免费试用。正式定价如下:
- 输入价格:0.8 元/百万 tokens
- 输出价格:2 元/百万 tokens
相比前代混元 Turbo 模型,Turbo S 的价格下降了数倍,进一步降低了大模型的使用门槛。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











