
尽管3D生成模型极大地改善了艺术家的工作流程,但现有的3D扩散模型在生成速度和泛化能力方面仍存在不足。为了解决这些问题,腾讯开发了一个名为 Hunyuan3D-1.0 的统一框架,它用于文本到3D(Text-to-3D)和图像到3D(Image-to-3D)的生成。这个框架通过两个阶段的方法,有效地解决了3D生成领域中的速度慢和泛化能力差的问题,同时保持了生成资产的质量和多样性。
- GitHub:https://github.com/Tencent/Hunyuan3D-1
- 模型:https://huggingface.co/tencent/Hunyuan3D-1
- Demo:https://huggingface.co/spaces/tencent/Hunyuan3D-1

例如,你是一名游戏设计师,需要快速将一个概念图或描述转化为3D模型,Hunyuan3D-1.0 可以接收文本提示或单张图片作为输入,快速生成高质量的3D资产。这大大缩短了从概念到模型的转换时间,提高了工作效率。

主要功能
多视图扩散模型:在第一阶段,该模型能够高效地生成多视图RGB图像,捕捉3D资产从不同视点的丰富细节。 前馈重建模型:在第二阶段,该模型能够快速且准确地从生成的多视图图像中重建3D资产。 文本到图像模型集成:框架集成了 Hunyuan-DiT,支持文本和图像条件的3D生成。
主要特点
速度与质量的平衡:Hunyuan3D-1.0 在显著减少生成时间的同时,保持了生成资产的质量和多样性。 双阶段方法:包括一个轻量版和一个标准版,支持文本和图像条件生成。 0-海拔姿态分布:在多视图生成中设计,最大化生成视图之间的可见区域。 混合输入:结合校准和未校准的图像作为输入,提高3D重建的准确性。 超分辨率模块:提高细节表示能力,增强3D形状的几何信息。
方法概述
Hunyuan3D-1.0 是一个两阶段的3D生成框架,旨在提高生成速度和泛化能力。以下是两个阶段的详细说明:
1、 第一阶段:多视图扩散模型
大规模2D扩散模型生成多视图图像,增强模型对3D信息的理解,并设置0-海拔相机轨道以最大化生成视图之间的可见区域。利用
目标:高效生成多视图RGB图像。 方法:采用多视图扩散模型,从不同视角捕捉3D资产的丰富细节,将任务从单视图重建放松到多视图重建。 效率:在约4秒内生成多视图RGB图像。
2、 第二阶段:稀疏视图重建模型
使用生成的多视图图像快速重建3D资产,学习处理多视图扩散引入的噪声和不一致性,并利用条件图像中的信息有效恢复3D结构。
目标:根据生成的多视图图像快速且忠实地重建3D资产。 方法:引入前馈重建模型,处理多视图扩散引入的噪声和不一致性,利用条件图像中的可用信息高效恢复3D结构。 效率:在约7秒内完成3D资产的重建。
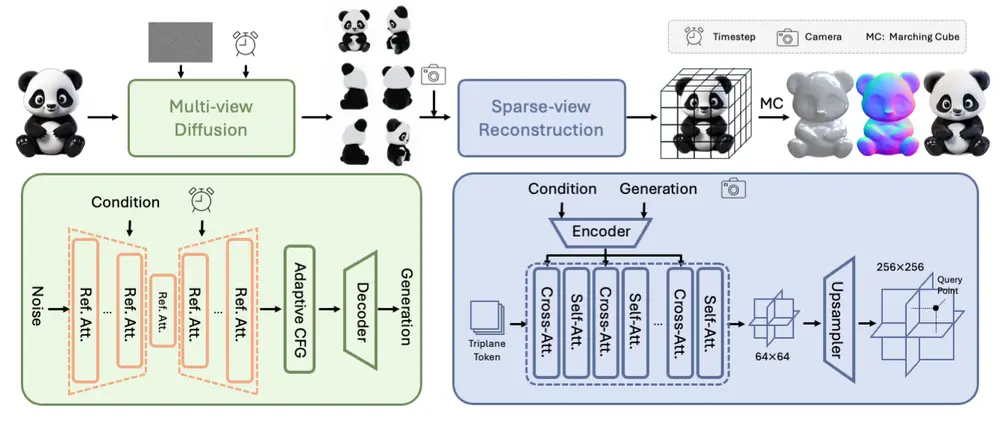
统一框架
Hunyuan3D-1.0 涉及一个文本到图像模型,即 Hunyuan-DiT,使其成为一个统一的框架,支持文本和图像条件的3D生成。标准版比精简版和其他现有模型多3倍的参数,从而在生成速度和质量之间实现了令人印象深刻的平衡。
性能评估
通过与其他开源3D生成方法进行评估,Hunyuan3D-1.0 在5个指标上获得了最高的用户偏好。具体表现如下:
精简模型:在NVIDIA A100 GPU上从单张图像生成3D网格大约需要10秒。 标准模型:在NVIDIA A100 GPU上从单张图像生成3D网格大约需要25秒。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











