
Stability AI在3月18日推出了一个基于Stable Video Diffusion技术的生成模型Stable Video 3D(SV3D),首次将视频扩散模型应用到3D生成领域,只需要一张图片,Stable Video 3D就能生成高质量的多视角视频和3D模型。

模型细节
该模型经过训练,能够在给定相同大小的上下文帧时,生成分辨率为576x576的21帧视频。这一模型是在SVD Image-to-Video的基础上进行微调的。
该模型的两个版本:
- SV3D_u:这个版本基于单个图像输入生成360度环绕视频,无需相机条件设置。
- SV3D_p:这个版本扩展了SV3D_u的功能,它既能处理单个图像,也能处理轨道视图,允许用户沿着指定的相机路径创建3D视频。
主要功能与特点
论文中提出的SV3D(Stable Video 3D)模型是一个先进的AI系统,它能够从单张图片中生成高质量的三维物体。SV3D的主要功能和特点包括:
- 多视角图像生成:SV3D能够根据单张图片生成多个新视角的图像,这些图像在色彩、形状和姿态上保持一致性。
- 三维优化:通过结合新视角图像,SV3D能够创建出精细的三维网格模型,这些模型在细节上非常准确。
- 控制性:SV3D允许用户通过相机姿态控制来生成特定视角的图像,这意味着你可以指定从哪个角度查看物体。
- 泛化能力:SV3D在训练时使用了大量图像和视频数据,使其能够处理各种类型的物体,具有很强的泛化能力。
工作原理
SV3D的工作原理基于“潜在视频扩散模型”(latent video diffusion model),这是一种利用AI生成连贯视频的技术。SV3D首先将这种模型适应于从单张图片生成多个视角的图像,然后利用这些图像来优化和生成三维模型。
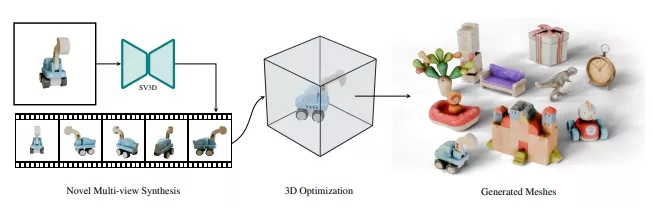
这个过程包括以下几个步骤:
- 新视角图像生成:SV3D使用潜在视频扩散模型来生成围绕物体的轨道视频,这些视频由多个视角的图像组成。
- 三维网格优化:通过迭代去噪和细化,SV3D将生成的多视角图像转化为三维网格模型。
- 细节增强:SV3D还设计了一种特殊的损失函数(如遮罩分数蒸馏采样损失,SDS loss),以增强模型在不可见区域的细节。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











