
在语音处理领域,标记化(tokenization)是生成或理解语音的关键步骤。传统的语音编码模型通常依赖于低参数量的架构,使用具有强归纳偏置的组件,如卷积神经网络(CNN)和循环神经网络(RNN)。然而,这些模型在极低比特率下的语音质量表现有限。为了突破这一瓶颈,Stability AI 提出了一种基于大规模 Transformer 架构的新型音频编码模型——TAAE(Transformer Audio AutoEncoder),结合了灵活的有限标量量化(Finite Scalar Quantization, FSQ)瓶颈,在 400 或 700 比特/秒的极低比特率下实现了前所未有的语音质量。
- 项目主页:https://stability-ai.github.io/stable-codec-demo
- GitHub:https://github.com/Stability-AI/stable-codec
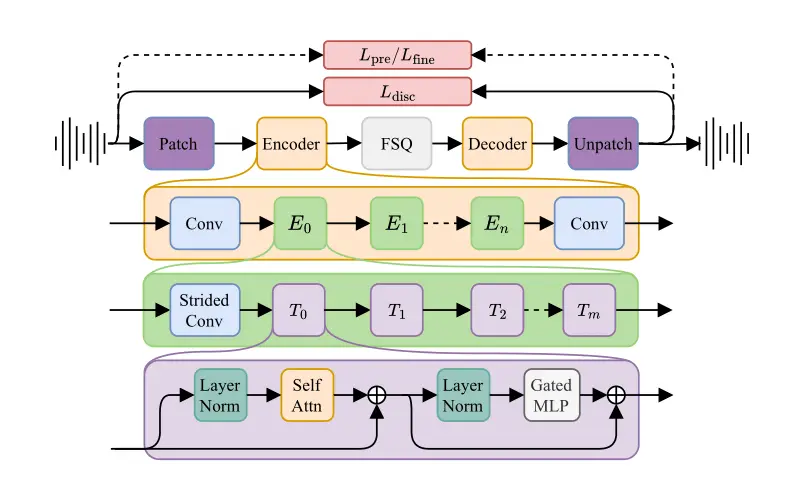
模型架构
1. 编码器块
TAAE 的编码器块由多个子块组成,每个子块包含以下组件:
- 多头自注意力机制(Multi-head Self-Attention):用于捕捉语音信号中的长程依赖关系。通过将输入序列分割成多个“头”,模型可以并行处理不同部分的特征,从而提高表达能力。
- 前馈神经网络(Feed-Forward Neural Network, FFN):用于进一步处理自注意力机制的输出,增强特征表示。
- 残差连接(Residual Connections):通过将输入直接加到输出上,避免了深层网络中的梯度消失问题,有助于模型的训练稳定性。
- 层归一化(Layer Normalization):对每一层的输出进行归一化处理,确保激活值的分布更加稳定,加速训练过程。
2. 解码器块
解码器块的结构与编码器块类似,唯一的区别在于:
- 步幅卷积(Strided Convolution):在编码器中用于降采样,而在解码器中则使用其转置版本(Transposed Convolution),用于升采样,逐步恢复原始语音信号的分辨率。
- Tm 块:解码器中的 Tm 块位于整个解码器的末尾,负责最终的特征重建和输出生成。
关键创新
1. 大规模 Transformer 架构
TAAE 的核心创新之一是扩展了 Transformer 的参数规模。传统的小型模型由于参数量有限,难以捕捉复杂的语音特征,尤其是在极低比特率下。通过引入大规模的 Transformer 架构,TAAE 能够更好地建模语音信号中的细微变化,从而在极低比特率下实现高质量的语音重建。这种架构的优势在于能够处理更长的上下文信息,并且在多模态任务中表现出色。
2. 有限标量量化(FSQ)瓶颈
为了在极低比特率下保持语音质量,TAAE 引入了有限标量量化(FSQ)瓶颈。FSQ 是一种灵活的量化方法,能够在压缩语音信号的同时,最大限度地保留重要的语音特征。具体来说,FSQ 通过对连续的语音特征进行离散化处理,将它们映射到有限的标量值上。这不仅显著降低了比特率,还确保了量化后的语音信号仍然具有较高的保真度。
FSQ 的灵活性体现在它可以适应不同的比特率需求,用户可以根据实际应用场景选择合适的量化精度。例如,在 400 比特/秒的极端低比特率下,FSQ 仍然能够提供接近真实语音的质量,而在 700 比特/秒时,语音质量进一步提升,几乎与原始语音无异。
3. 极低比特率下的卓越表现
TAAE 在 400 和 700 比特/秒的极低比特率下表现出色,显著优于现有的语音编解码器。通过 MUSHRA 主观测试,研究人员发现 TAAE 在语音质量方面取得了最先进的成果,甚至在某些情况下接近了真实语音(ground truth)。MUSHRA 测试是一种广泛使用的主观评估方法,能够有效地衡量编解码器的语音质量。TAAE 在该测试中的优异表现表明,基于 Transformer 的编解码架构在语音质量和压缩方面具有巨大的潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











