
Liquid AI 正式推出 LFM2.5 系列模型,这是该团队针对边缘 AI 部署打造的新一代旗舰产品,基于 LFM2 设备优化架构升级而来,实现了 1B 级模型能力边界的重大突破。此次发布覆盖基础文本、指令调优、日语专属、视觉语言及音频语言五大类模型,全系列均为开放权重,现已在 Hugging Face 和 LEAP 平台上线,同时与 AMD、Nexa AI 合作完成 NPU 端优化,可无缝适配车辆、移动设备、物联网终端等多种受限硬件。
相较于前代,LFM2.5 的核心升级在于训练数据规模与训练后流程的双重强化:预训练数据从 10T token 扩展至 28T token,同时通过多阶段强化学习优化指令遵循能力,旨在成为设备端代理 AI 的核心构建模块,为各类终端设备提供私密、快速、始终在线的智能体验。
核心模型家族:覆盖多模态设备端需求
LFM2.5 系列包含五大类模型,分别针对文本、多语言、视觉、音频等不同场景做深度优化,满足多样化边缘 AI 应用需求。
1. 通用文本模型:1B级性能天花板
LFM2.5 的通用文本模型分为两个版本,适配不同开发需求:
- LFM2.5-1.2B-Base:基础预训练模型,是全系列模型的骨干网络,适合需要基于专有数据微调、特定领域定制(如垂直行业助手)或探索新训练方法的开发者。
- LFM2.5-1.2B-Instruct:指令调优版模型,经过监督微调、偏好对齐与多阶段强化学习训练,开箱即用,具备出色的指令遵循和工具使用能力,可直接落地本地生产力助手、车载智能交互等场景。
基准测试表现:在 1B 规模模型中,LFM2.5-1.2B-Instruct 实现了性能与效率的双重领先。对比 Llama 3.2 1B Instruct、Gemma 3 1B IT 等同级模型,其在 GPQA(知识问答)、MMLU-Pro(多任务理解)、IFEval(指令遵循)等核心基准测试中全面领跑,具体数据如下:
| 模型 | GPQA | MMLU-Pro | IFEval | IFBench | Multi-IF | AIME25 | BFCLv3 |
|---|---|---|---|---|---|---|---|
| LFM2.5-1.2B-Instruct | 38.89 | 44.35 | 86.23 | 47.33 | 60.98 | 14.00 | 49.12 |
| Llama 3.2 1B Instruct | 16.57 | 20.80 | 52.37 | 15.93 | 30.16 | 0.33 | 21.44 |
| Gemma 3 1B IT | 24.24 | 14.04 | 63.25 | 20.47 | 44.31 | 1 | 16.64 |
同时,该模型针对 CPU 推理做深度优化,相比同规模模型内存占用更低,推理速度更快,完美适配无独立显卡的终端设备。
2. 日语专属模型:精准匹配语言文化特性
LFM2.5-1.2B-JP 是专为日语场景优化的聊天模型,在保留通用能力的基础上,强化了日语知识储备与指令遵循精度,可精准捕捉日语的文化和语言细微差别。
在 JMMLU(日语多任务理解)、M-IFEval (ja)(日语指令遵循)、GSM8K (ja)(日语数学推理)三大基准测试中,LFM2.5-1.2B-JP 显著优于同规模竞品,部分指标甚至超过更大参数量的 Qwen3-1.7B 指令模式模型,具体数据如下:
| 模型 | JMMLU | M-IFEval (ja) | GSM8K (ja) |
|---|---|---|---|
| LFM2.5-1.2B-JP | 50.7 | 58.1 | 56.0 |
| Qwen3-1.7B (指令模式) | 47.7 | 40.3 | 46.0 |
| Llama 3.2 1B Instruct | 34.0 | 24.1 | 25.2 |
该模型适合开发日语本地助手、文化内容生成等应用。
3. 视觉语言模型:多图像多语言理解能力升级
LFM2.5-VL-1.6B 是升级后的多模态模型,基于 LFM2.5-base 骨干网络构建,核心提升两点:
- 多图像理解:支持多张图片输入的关联分析,可处理更复杂的视觉任务;
- 多语言视觉指令:优化阿拉伯语、中文、法语、德语等 7 种语言的视觉提示理解能力,输出更精准。
在 MMStar(多模态综合能力)、OCRBench v2(光学字符识别)、多语言 MMBench(多语言视觉问答)等基准测试中,LFM2.5-VL-1.6B 全面超越前代 LFM2-VL-1.6B,同时优于 InternVL3.5-1B 等同级模型,成为边缘多模态应用(如本地图像分析、多语言视觉助手)的优选方案。
4. 音频语言模型:8倍提速,原生音频处理
LFM2.5-Audio-1.5B 是一款原生音频语言模型,与传统“语音转文字+LLM处理+文字转语音”的串联方案不同,该模型可直接接收语音和文本输入,输出语音或文本,消除了组件间的信息损耗,大幅降低端到端延迟。
其核心技术亮点在于定制化 LFM 音频解码器:
- 速度提升:在移动 CPU 上,同精度下推理速度比前代 Mimi 解码器快 8 倍;
- 量化优化:支持 INT4 量化感知训练,低精度部署下音质损失极小,与 FP32 精度的前代解码器性能接近;
- 框架兼容:提供 llama.cpp 支持的 GGUF 格式,可在终端设备上高效运行。
在 STOI(语音可懂度)、UTMOS(语音质量评分)等音频基准测试中,LFM2.5-Audio-1.5B(INT4)表现与前代 FP32 精度模型持平,远超同量化精度的竞品。
全框架部署支持:覆盖从终端到云端的硬件生态
LFM2.5 系列的核心优势之一是开箱即用的多框架部署能力,无需复杂适配即可在主流硬件上运行,覆盖从嵌入式设备到 GPU 服务器的全场景:
- LEAP 平台:Liquid 官方边缘 AI 平台,可像调用云 API 一样,将模型一键部署到 iOS 和 Android 设备;
- llama.cpp:CPU 推理首选方案,提供 GGUF 检查点,支持量化优化,适配各类终端设备;
- MLX:专为 Apple Silicon 优化,充分利用其统一内存架构,提升本地推理效率;
- vLLM:针对 GPU 加速场景,支持高吞吐量推理,适合模型的生产级服务部署;
- ONNX:跨平台推理标准,可部署在 AMD、Qualcomm、Nvidia 等多种硬件加速器上。
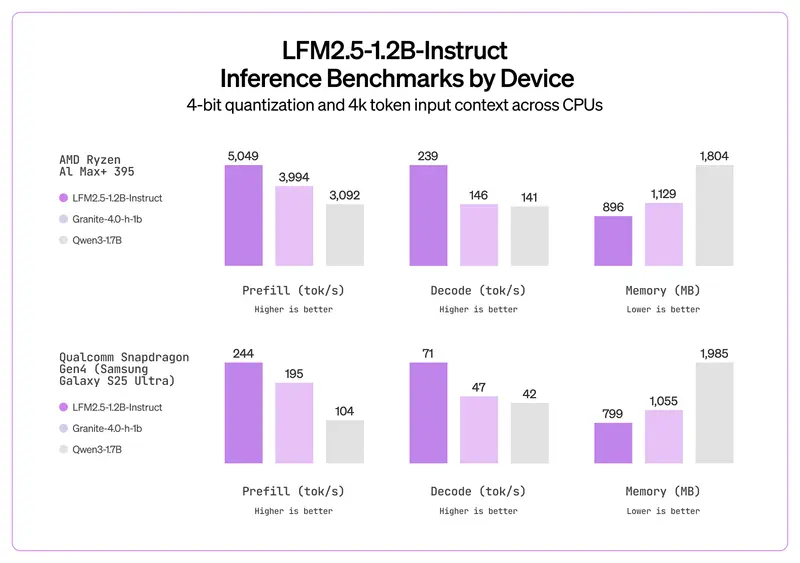
硬件推理速度基准:终端设备表现亮眼
Liquid AI 公布了 LFM2.5-1.2B-Instruct 在多款主流硬件上的推理性能数据(基于 1K 预填充 token、100 解码 token),充分展现了其设备端适配能力:
| 设备 | 推理硬件 | 框架 | 预填充 (tok/s) | 解码 (tok/s) | 内存占用 |
|---|---|---|---|---|---|
| AMD Ryzen AI 9 HX 370 | CPU | llama.cpp (Q4_0) | 2975 | 116 | 856MB |
| 高通骁龙 X Elite | NPU | NexaML | 2591 | 63 | 0.9GB |
| 三星 Galaxy S25 Ultra | CPU | llama.cpp (Q4_0) | 335 | 70 | 719MB |
对比同规模的 Qwen3-1.7B 模型,LFM2.5 在同款硬件上的预填充和解码速度均领先,内存占用降低约 40%,更适合资源受限的终端设备。
生态合作与获取方式
- 合作伙伴优化:与 AMD、Nexa AI 深度合作,完成 LFM2.5 系列模型的 NPU 端优化,解锁车辆、物联网设备等更多边缘部署场景;
- 模型获取渠道:全系列模型已在 Hugging Face、LEAP 平台开放下载,同时提供在线游乐场和 Demo 体验,开发者可直接访问对应平台获取检查点与部署文档。
LFM2.5 系列的发布,进一步降低了设备端 AI 的部署门槛。凭借开放权重、多模态支持和高效推理的核心优势,这款模型有望成为边缘智能应用的重要基础设施,推动车载助手、本地生产力工具、物联网终端等场景的智能化升级。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











