两年前,复杂的推理任务还需要依赖数据中心。如今,Liquid AI 发布的 LFM2.5-1.2B-Thinking 模型,让这一切在任何拥有 900MB 可用内存的手机上成为可能。
这不仅是一个轻量模型,更是一个具备内部思考能力的设备端推理引擎。它能在生成最终答案前,先进行系统化的推理规划,从而在数学、工具调用和指令遵循等任务上实现显著提升。
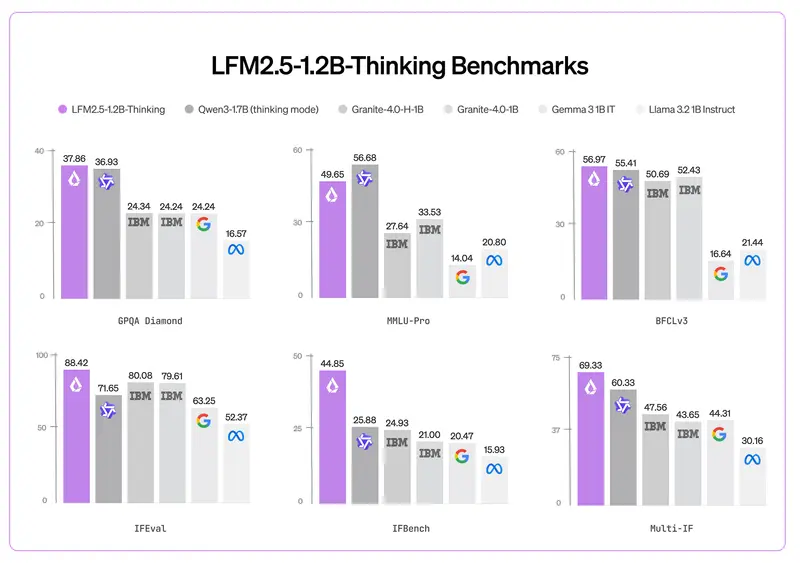
性能飞跃:更小,却更强
尽管参数量比前代减少 40%,LFM2.5-1.2B-Thinking 在多项关键指标上大幅超越其 Instruct 版本:
| 能力 | 前代(Instruct) | 新版(Thinking) | 提升 |
|---|---|---|---|
| 数学推理(MATH-500) | 63 | 88 | +40% |
| 指令遵循(Multi-IF) | 61 | 69 | +13% |
| 工具使用(BFCLv3) | 49 | 57 | +16% |
更令人惊讶的是,它在大多数基准测试中媲美甚至超越 Qwen3-1.7B(思考模式),同时:
- 生成答案所需的 输出 token 更少
- 推理时计算量更低
- 内存占用低于 1GB
边缘部署优势
LFM2.5-1.2B-Thinking 专为设备端高效推理设计:
- 运行内存 < 1GB,可在主流手机、平板、嵌入式设备上流畅运行
- 解码速度:
- AMD CPU:239 tokens/秒
- 移动 NPU:82 tokens/秒
- 广泛兼容:支持
llama.cpp、MLX(Apple Silicon)、vLLM等主流推理后端
相比纯 Transformer 架构(如 Qwen3-1.7B)或混合架构(如 Granite-4.0-H-1B),它在延迟和内存效率上均表现更优。
技术基础
该模型基于 LFM2 混合架构,通过以下方式强化推理能力:
- 扩展预训练:训练数据从 10T tokens 增至 28T tokens
- 多阶段强化学习:专门优化“思考-执行”链路,提升问题分解与工具调用能力
- 简洁推理训练:鼓励模型用最少步骤得出正确答案,避免冗余输出
应用前景
- 移动端 AI 助手:在手机上本地运行复杂任务(如解题、数据分析)
- 离线智能设备:工业终端、车载系统、IoT 设备无需联网即可推理
- 隐私敏感场景:医疗、金融等领域可完全避免数据上传
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











