由香港中文大学、西湖大学、上海人工智能实验室与马克斯·普朗克智能系统研究所联合开展的研究团队,近日推出 SGP-Gen ——一项探索大语言模型(LLM)在符号图形编程(Symbolic Graphics Programming, SGP) 领域能力的前沿工作。
该研究聚焦一个尚未被充分挖掘的问题:
大模型能否像写代码一样,“写”出一张图像?
研究人员提出并开源了 SGP-GenBench,首个面向 SVG 程序生成的综合性评估基准,并通过强化学习(RL)方法显著提升开源模型的表现,使它们在视觉生成任务中接近闭源模型水平。

为什么是符号图形编程(SGP)?
传统文本到图像模型(如扩散模型)生成的是像素图像,而 SGP 的目标是生成结构化代码(如 SVG),通过程序化方式构建图形。
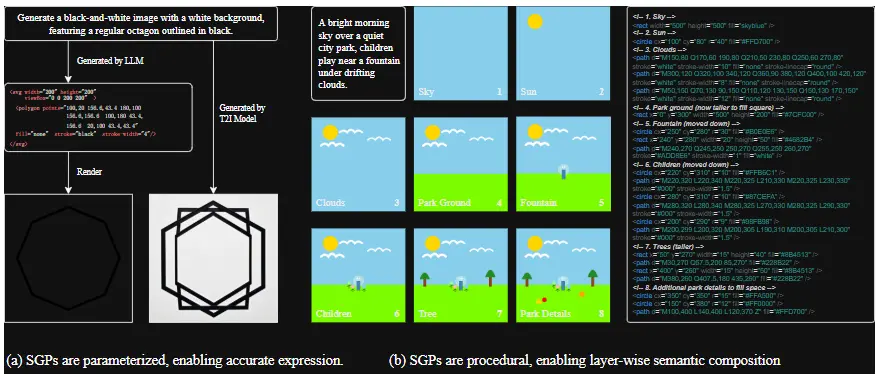
以 SVG 为例,它是一种广泛使用的矢量图形格式,由 <circle>、<path> 等标签组成,具备以下优势:
| 特性 | 价值 |
|---|---|
| ✅ 参数化控制 | 可精确调整几何形状、颜色、位置 |
| ✅ 程序化结构 | 支持嵌套、复用、层次化建模 |
| ✅ 可解释性强 | 生成结果可读、可编辑、可追溯 |
| ✅ 轻量高效 | 文件小,缩放无损,适合网页与 UI 设计 |
SGP 本质上是“将语言语义转化为可视化程序”,是检验 LLM 跨模态理解与结构化输出能力的理想测试场。
SGP-GenBench:首个全面的 SGP 评估基准
为系统评估 LLM 的 SGP 能力,研究团队构建了 SGP-GenBench,包含三大任务维度:
1. 物体生成(Object Generation)
- 基于 SGP-Object-val 数据集,含 930 个单物体示例;
- 测试模型对具体物体(如“一只黄色鸭子”)的准确渲染能力。
2. 场景生成(Scene Generation)
- 基于 COCO-val 子集,涵盖 80 类物体与复杂语义描述;
- 包含 1,024 个样本,评估模型构建多对象场景的能力。
3. 组合生成(Compositional Generation)
- 使用 SGP-CompBench,含 3,200 个提示;
- 重点测试:
- 属性绑定(如“红色的苹果”)
- 空间关系(如“猫在桌子左边”)
- 数量控制(如“三个蓝色方块”)
所有任务均采用自动化指标(如 DINO、CLIP、VQA 准确率)进行评估,确保可复现与可扩展。
方法创新:无需配对数据的强化学习训练
如何提升 LLM 生成 SVG 的能力?研究团队提出一种基于视觉反馈的强化学习框架。
核心思路:
- 给定文本提示,让 LLM 生成 SVG 代码;
- 将 SVG 渲染为图像;
- 使用视觉编码器(如 SigLIP、DINO)计算渲染图与原始文本描述之间的语义相似度;
- 将该相似度作为奖励信号,用于更新 LLM 策略。
🔄 整个过程无需“图像-程序”配对训练数据,仅依赖视觉模型提供反馈。
关键优势:
- 无需真实 SGP 训练集:摆脱对人工标注程序的依赖;
- 隐式知识提炼:从强大视觉模型中学习跨模态对齐;
- 语言-视觉闭环:确保生成内容既符合语义,又具备视觉合理性。
实验结果:RL 显著缩小开源与闭源模型差距
1. 闭源模型仍领先
在未微调情况下,主流闭源模型表现优异:
- Claude 3.7 Sonnet Thinking:
- 属性绑定得分:90.5
- 数量控制得分:89.4
- Gemini 2.5 Pro Preview:
- DINO 物体匹配得分:0.653(最高)
- 场景 VQA 得分:0.554
表明前沿模型已具备较强的符号生成能力。
2. 强化学习显著提升开源模型
经过 RL 后训练的 Qwen-2.5-7B 表现惊艳:
- 组合性得分从 8.8 提升至 60.8;
- 在所有模型中取得最高的 VQA 得分 0.596,略超 Claude;
- 超越 DeepSeek-R1、QwQ-32B 等其他开源模型。
✅ 证明:通过 RL,小型开源模型可逼近甚至超越大型闭源系统。
深入分析:训练动态与消融实验
训练过程观察
- 模型生成的 SVG 元素数量和代码长度逐步增加;
- 开始使用更复杂的结构(如分组、变换);
- 能将复杂对象分解为基本图形组件(如用多个
<path>构建动物轮廓); - 主动添加上下文细节(如阴影、背景),增强视觉丰富性。
消融研究发现
- SigLIP 比 CLIP 更适合做奖励模型:在事实性对齐与多样性方面表现更优;
- 更大的视觉编码器不总是更好:模型容量需与任务匹配;
- 添加视觉编码器对 VQA 提升有限,但能更好匹配人类偏好。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











