
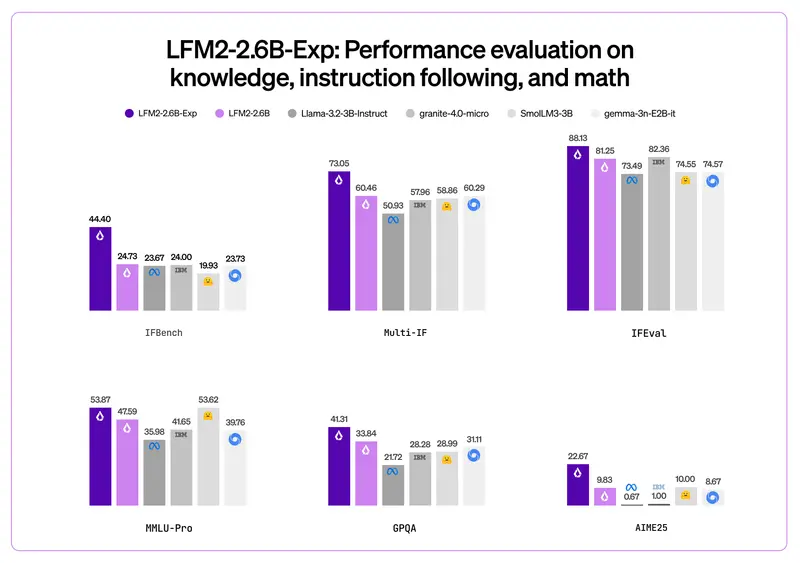
Liquid AI 正式推出 LFM2-2.6B-Exp —— 一个基于纯强化学习(RL)训练的实验性语言模型。它在指令遵循、常识推理和数学任务上表现突出,尤其值得注意的是:其 IFBench 评测分数已超过 DeepSeek R1-0528,而后者参数量是它的 263 倍。
这一结果再次印证了:模型性能不仅取决于规模,更依赖于训练方法与目标对齐。
小而高效:LFM2 系列的核心优势
LFM2 系列采用独特的 混合架构(卷积 + 注意力),在保持较小参数量的同时实现高推理效率。全系列支持 32,768 词元上下文 和 bfloat16 精度,训练数据量统一为 10 万亿词元,覆盖 8 种主流语言:英语、中文、阿拉伯语、法语、德语、日语、韩语、西班牙语。
| 模型 | 参数量 | 层数(Conv / Attn) |
|---|---|---|
| LFM2-350M | 354M | 10 / 6 |
| LFM2-700M | 742M | 10 / 6 |
| LFM2-1.2B | 1.17B | 10 / 6 |
| LFM2-2.6B | 2.57B | 22 / 8 |
所有模型均采用 65,536 词元的大型词汇表,提升语言表达密度与生成流畅度。
适用场景与使用建议
尽管 LFM2-2.6B-Exp 在多项基准中表现优异,Liquid AI 明确建议:
✅ 推荐用途:
- 智能代理(Agent)任务
- 结构化数据提取
- RAG(检索增强生成)中的重排或摘要
- 创意写作与多轮对话
- 在特定任务上微调以进一步提升性能
❌ 不推荐用途:
- 高度知识密集型任务(如专业领域问答)
- 复杂编程或代码生成
官方强调:“由于其规模较小,建议在特定用例上对 LFM2 模型进行微调,以最大化性能。”
开源与许可
全系列模型采用 LFM 开放许可证 v1.0 发布,允许研究与商业使用,详情见官方仓库。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











