伊利诺伊大学厄巴纳-香槟分校计算机科学系和马萨诸塞大学安姆赫斯特分校智能信息检索中心的研究人员推出新型框架SEARCH-R1 ,通过强化学习( RL)训练大语言模型,使其能够在推理过程中自主生成搜索查询并与搜索引擎进行交互,从而获取外部知识和最新信息,以提升在复杂推理和文本生成任务中的表现。
- GitHub:https://github.com/PeterGriffinJin/Search-R1
- 模型:https://huggingface.co/collections/PeterJinGo/search-r1-67d1a021202731cb065740f5
SEARCH-R1 是一种扩展的 DeepSeek-R1 模型,通过强化学习让 LLM 在逐步推理过程中自主生成多个搜索查询,并实时检索信息。例如,当模型面临一个需要最新数据的问题,如“2024 年苹果公司季度报告中最高和最低销售产品的利润差额是多少?”时,SEARCH-R1 可以通过搜索引擎获取最新报告,并从中提取相关信息来回答问题。
主要功能
- 自主搜索查询生成:模型能够根据推理过程中的需求,自主生成多个搜索查询。
- 实时检索与推理结合:在推理过程中实时调用搜索引擎,获取外部知识以辅助推理。
- 多轮交互支持:支持多轮搜索和推理交互,动态调整检索策略以应对复杂问题。
- 强化学习优化:通过强化学习优化模型的推理和搜索行为,提升整体性能。
主要特点
- 检索增强推理:通过检索外部信息,增强 LLM 在复杂推理任务中的表现。
- 动态检索长度调整:根据问题复杂性动态调整检索结果数量,减少噪声和计算开销。
- 简单有效的奖励函数:采用基于最终结果的奖励函数,避免复杂的过程奖励设计。
- 兼容性强:支持多种强化学习算法(如 PPO 和 GRPO),并适用于不同的 LLM 架构。
工作原理
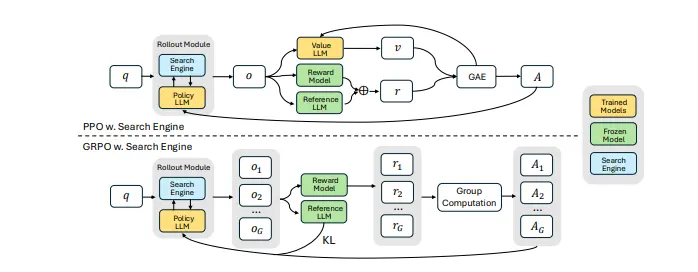
- 强化学习框架:
- 环境建模:将搜索引擎建模为环境的一部分,使模型能够在推理过程中插入搜索调用。
- 检索结果掩码:在优化过程中,对检索到的标记进行掩码处理,避免对检索内容进行不必要的优化,从而稳定训练过程。
- 多轮交互推理:
- 搜索调用:模型在推理过程中通过
<search>和</search>标记触发搜索调用。 - 检索内容处理:检索到的内容被包裹在
<information>和</information>标记中,作为后续推理的上下文。 - 答案生成:最终答案被包裹在
<answer>和</answer>标记中,明确区分推理、搜索和答案生成的步骤。
- 搜索调用:模型在推理过程中通过
- 奖励函数设计:
- 结果导向奖励:采用简单的基于结果的奖励函数,仅根据模型生成的最终答案是否正确来给予奖励,避免复杂的过程奖励设计。
应用场景
- 智能问答系统:在智能客服或在线问答平台中,SEARCH-R1 可以实时检索最新信息,提供准确的答案。
- 研究与分析:研究人员可以利用 SEARCH-R1 快速检索和分析大量文献,辅助科学研究和报告撰写。
- 教育领域:教师可以利用该框架快速准备教学材料,学生可以更高效地完成作业和研究项目。
- 金融分析:分析师可以实时获取市场数据和公司报告,辅助投资决策和市场分析。
总结
SEARCH-R1 通过强化学习优化 LLM 的推理和搜索行为,在多个问答数据集上显著提升了性能,平均相对改进率达到 10% 至 26%。该框架不仅提高了模型在复杂推理任务中的表现,还为检索增强推理提供了新的解决方案。未来工作可以探索更复杂的奖励机制、动态检索调整策略,以及将该框架应用于多模态推理任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











