中国人民大学和蚂蚁集团的研究人员推出新型大语言模型LLaDA,基于扩散模型(Diffusion Model)从头开始训练,挑战了自回归模型(ARM)在大型语言模型中的主导地位。与传统的从左到右的生成方法不同,LLaDA 通过扩散模型生成文本。其核心是通过“前向掩码”和“反向预测”来生成文本,而不是像 ChatGPT 那样逐个生成单词。
- 项目主页:https://ml-gsai.github.io/LLaDA-demo
- GitHub:https://github.com/ML-GSAI/LLaDA
- 模型:https://huggingface.co/GSAI-ML
- Demo:https://huggingface.co/spaces/multimodalart/LLaDA
LLaDA 是一种基于扩散模型的大语言模型,旨在通过掩码扩散模型(MDM)来模拟语言分布。与传统的自回归模型(ARM)不同,LLaDA 通过一个前向掩码过程和一个反向过程来建模,能够同时优化双向依赖关系,并通过似然下界优化来生成文本。例如,在处理一个需要推理的任务时,LLaDA 可以通过反向过程逐步恢复被掩码的文本,从而生成连贯的输出。
主要功能
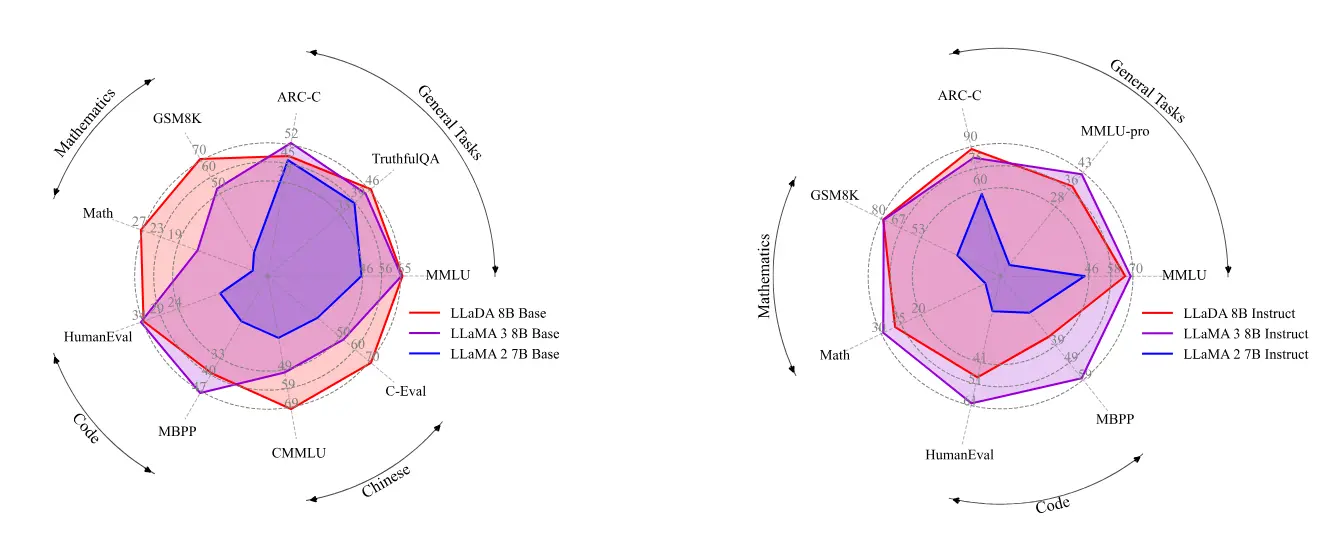
- 强大的可扩展性:LLaDA 在多个基准测试中表现出色,与自回归模型(ARM)相比具有竞争力。
- 上下文学习能力:在零样本和少样本学习任务中,LLaDA 表现出色,能够理解上下文并生成相关的回答。
- 指令跟随能力:经过监督微调(SFT)后,LLaDA 在多轮对话等任务中表现出色,能够准确理解并执行指令。
- 反向推理能力:LLaDA 在反向推理任务中表现出色,例如在补全诗歌的反向任务中,LLaDA 能够生成与给定句子相匹配的前一句,而 GPT-4o 等模型则难以完成此类任务。
主要特点
- 非自回归生成:与传统的自回归模型不同,LLaDA 采用掩码扩散模型,能够同时预测所有掩码的标记,避免了逐个标记生成的高计算成本。
- 双向依赖关系:LLaDA 的模型分布具有双向依赖关系,能够更好地捕捉文本中的上下文信息。
- 生成模型的可扩展性:LLaDA 通过优化似然下界来训练,具有良好的可扩展性,能够在大规模数据和模型上实现有效的训练。
- 反向推理能力:LLaDA 在反向推理任务中表现出色,能够有效地处理反向任务,而传统的自回归模型在这些任务中往往表现不佳。
工作原理
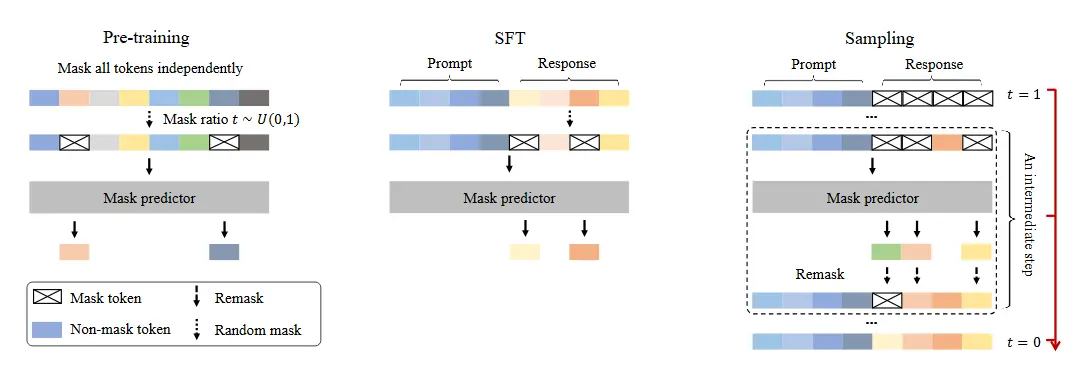
- 前向掩码过程:LLaDA 通过一个前向过程逐步掩码文本中的标记,直到所有标记都被掩码。
- 反向过程:LLaDA 通过一个反向过程逐步恢复被掩码的标记,从而生成文本。
- 掩码预测器:LLaDA 使用一个掩码预测器(如 Transformer)来预测被掩码的标记,该预测器以部分掩码的文本作为输入,并预测所有掩码的标记。
- 优化似然下界:LLaDA 通过优化似然下界来训练,确保模型能够有效地生成文本,同时保持生成过程的可扩展性。
应用场景
- 自然语言理解:LLaDA 可以用于处理各种自然语言理解任务,如问答系统、文本分类等。
- 数学和科学问题解决:LLaDA 在解决数学和科学问题方面表现出色,能够生成准确的解决方案。
- 代码生成:LLaDA 可以生成代码,帮助开发者快速实现编程任务。
- 多语言对话:LLaDA 支持多语言对话,能够理解和生成多种语言的文本。
- 诗歌创作:LLaDA 在诗歌创作方面表现出色,能够生成与给定句子相匹配的前一句或后一句。
总结
LLaDA 作为一种基于扩散模型的大型语言模型,通过掩码扩散模型(MDM)提供了一种有原则的生成方法,能够有效地处理复杂的语言任务。LLaDA 在多个基准测试中表现出色,特别是在反向推理任务中,展现了其独特的优势。未来的研究可以进一步探索 LLaDA 的潜力,包括在多模态数据处理、系统级架构优化以及与强化学习的结合等方面。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











