深度求索(DeepSeek)正式推出 DeepSeek-V3.1 —— 一个在架构设计、推理效率和智能体能力上全面升级的新版本模型。此次更新不仅提升了性能,更引入了混合思考模式,让同一个模型可灵活适应不同任务场景。

官方 App 与网页端已同步升级,API 接口也已完成部署,开发者可通过新接口调用两种运行模式,并享受更长上下文、更强工具调用与更低延迟。
核心升级概览
| 升级方向 | 主要改进 |
|---|---|
| 推理模式 | 支持“思考模式”与“非思考模式”自由切换 |
| 上下文长度 | 全系列扩展至 128K |
| Agent 能力 | 工具调用与复杂任务执行显著增强 |
| 训练数据 | 长上下文训练数据量大幅增加 |
| 输出效率 | 思考模式下 token 数减少 20%-50%,质量持平前代最优模型 |
| API 兼容性 | 新增对 Anthropic API 格式支持 |
混合模式设计:一模型,两用法
DeepSeek-V3.1 最重要的创新在于其混合推理架构:通过调整 chat template,同一模型可动态切换为:
- 思考模式(Reasoning Mode)
适用于需要多步推理、逻辑分析或工具调用的复杂任务,如代码修复、数学证明、复杂决策等。 - 非思考模式(Direct Mode)
用于简单问答、内容生成、指令响应等低延迟场景,响应更快,输出更简洁。
用户可通过官方 App 中的“深度思考”按钮自由切换;API 则通过
deepseek-reasoner(思考)与deepseek-chat(非思考)两个端点分别调用。
这种设计避免了部署多个模型的成本,同时兼顾了推理深度与响应效率。
更强的 Agent 能力:工具调用全面优化
DeepSeek-V3.1 经过后训练(Post-Training)专项优化,在工具使用和智能体任务中的表现显著提升:
- 函数调用准确率更高,结构更稳定
- 支持 strict 模式 Function Calling(API Beta 接口),确保输出严格符合 schema 定义
- 在复杂代理任务(如自动调试、终端操作)中成功率明显上升
在 Terminal-Bench 测试中,模型能更可靠地执行命令行任务;在 SWE-Bench(代码修复评测) 上,解决真实 GitHub issue 的能力较此前版本有明显进步。

训练细节:更大规模的长上下文训练
DeepSeek-V3.1 基于 DeepSeek-V3.1-Base 进行后训练,而该基础模型采用两阶段长上下文扩展方法构建,延续 DeepSeek-V3 技术路线:
| 阶段 | 原始数据量 | 扩展后数据量 | 标记数 |
|---|---|---|---|
| 32K 扩展 | ~63B tokens | 扩展 10 倍 | 630B tokens |
| 128K 扩展 | ~63B tokens | 扩展 3.3 倍 | 209B tokens |
通过引入更多长文档数据,并大幅增加训练步数,模型在处理超长输入时的连贯性与信息提取能力显著增强。

此外,训练过程中采用 UE8M0 FP8 Scale 参数精度格式,确保与微缩放(scaled-down)模型的数据格式兼容,便于后续轻量化部署。
性能表现:更快、更准、更高效
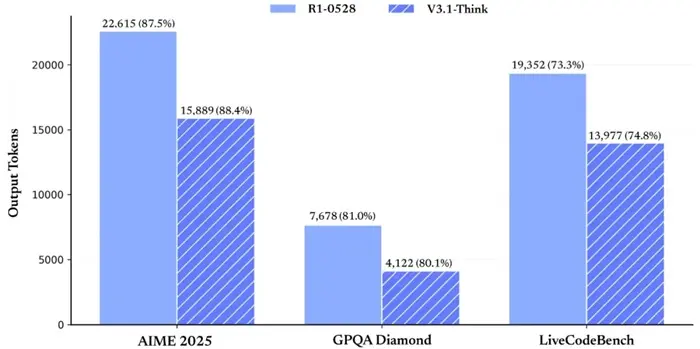
1. 推理效率提升
- DeepSeek-V3.1-Think 在多项复杂任务上的表现与此前高性能模型 R1-0528 相当;
- 但输出 token 数平均减少 20%-50%,意味着响应速度更快、成本更低;
- 非思考模式下,相比 DeepSeek-V3-0324,输出长度有效压缩,性能保持不变。
2. 多步推理与专家级任务领先
在以下评测中表现突出:
- browsecomp:需要多步网页搜索与判断的复杂任务,V3.1 表现大幅优于 R1-0528;
- HLE(Hard Long-form Expertise):跨学科专家级难题测试,涵盖法律、医学、工程等领域,V3.1 展现出更强的理解与推理能力。
API 升级:更灵活,更兼容
DeepSeek API 已完成同步升级,主要变化如下:
| 接口 | 功能 |
|---|---|
deepseek-chat | 非思考模式,适用于常规对话与生成 |
deepseek-reasoner | 思考模式,用于复杂推理与工具调用 |
| 上下文长度 | 全部支持 128K |
| Function Calling | Beta 接口支持 strict 模式,确保输出符合 schema |
| 兼容性 | 新增支持 Anthropic API 格式,可无缝接入 Claude Code 开发框架 |
模型下载信息
所有模型均支持 128K 上下文,参数总量一致,激活参数相同:
| 模型名称 | 总参数量 | 激活参数量 | 上下文长度 | 下载 |
|---|---|---|---|---|
| DeepSeek-V3.1-Base | 671B | 37B | 128K | HuggingFace | ModelScope |
| DeepSeek-V3.1 | 671B | 37B | 128K | HuggingFace | ModelScope |
⚠️ 注意:V3.1 对 分词器(tokenizer) 和 chat template 进行了较大调整,与 V3 存在不兼容。建议部署前仔细阅读新版说明文档。
价格调整通知(2025.9.6 起生效)
深度求索将于 北京时间 2025 年 9 月 6 日凌晨 起执行新的 API 定价策略:
- 启用新版价格表(详见定价页面)
- 取消夜间时段优惠

在此之前,所有 API 调用仍按原政策计费,用户可继续享受现有优惠。同时,平台已进一步扩容服务资源,以满足日益增长的调用需求。
总结:迈向高效智能体的新一步
DeepSeek-V3.1 不只是一个性能更强的模型,它代表了一种更务实的 AI 演进路径:
- 统一模型,双模式运行:兼顾效率与深度,降低部署复杂性;
- 更强的 Agent 能力:在真实复杂任务中更可靠地调用工具、执行操作;
- 更高的推理效率:用更少 token 实现同等甚至更优表现;
- 开放兼容的 API 设计:支持多种格式,便于集成进现有开发流程。
对于开发者而言,这意味着你可以用一个模型应对从快速响应到深度推理的全场景需求;对于研究者和企业用户,V3.1 提供了更稳定、可预测的智能体基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











