上海AI实验室发布 Intern-S1-Pro:万亿参数 MoE 多模态科学推理模型上海AI实验室推出 Intern-S1-Pro —— 一款面向科学发现的万亿级混合专家(MoE)多模态大模型。该模型在保持强大通用能力的同时,专为 AI for Science(AI4Science...多模态模型# Intern-S1-Pro# 上海AI实验室# 书生科学多模态大模型1个月前0200
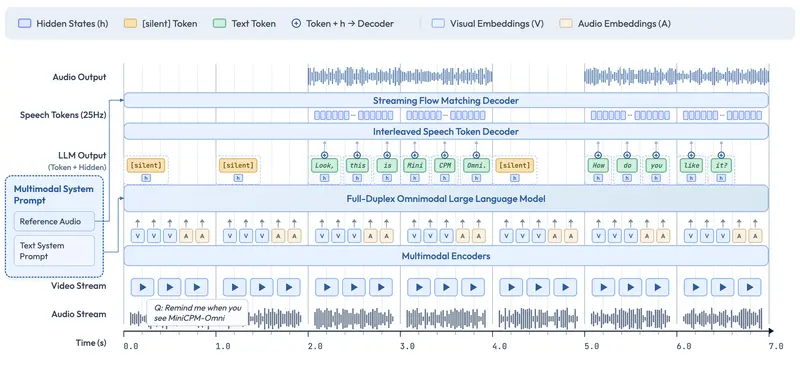
面壁智能发布MiniCPM-o 4.5:9B参数端侧全双工多模态大模型,对标Gemini 2.5 Flash面壁智能正式推出MiniCPM-o系列最新旗舰模型——MiniCPM-o 4.5。这款总参数量仅9B的端侧多模态大模型(MLLM),基于SigLip2、Whisper-medium、CosyVoice...多模态模型# MiniCPM-o 4.5# 面壁智能1个月前0640
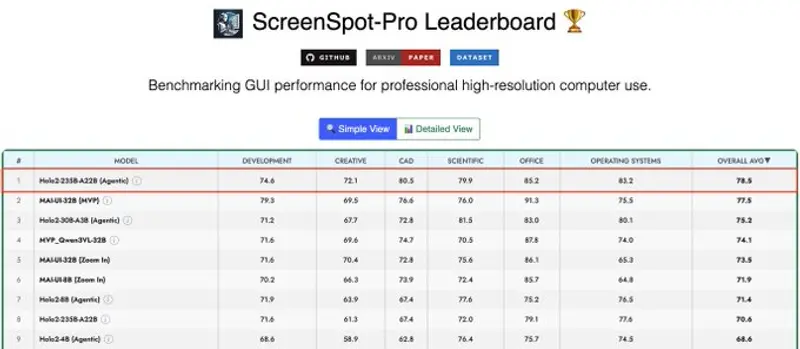
两个月再升级!HCompany推出2350亿参数Holo2-235B-A22B,刷新UI定位模型基准距离首款Holo2模型发布仅两个月,HCompany便推出迄今最大规模的UI定位模型Holo2-235B-A22B Preview,一举在ScreenSpot-Pro基准测试中创下78.5%的新纪录...多模态模型# HCompany# Holo2# Holo2-235B-A22B1个月前0220
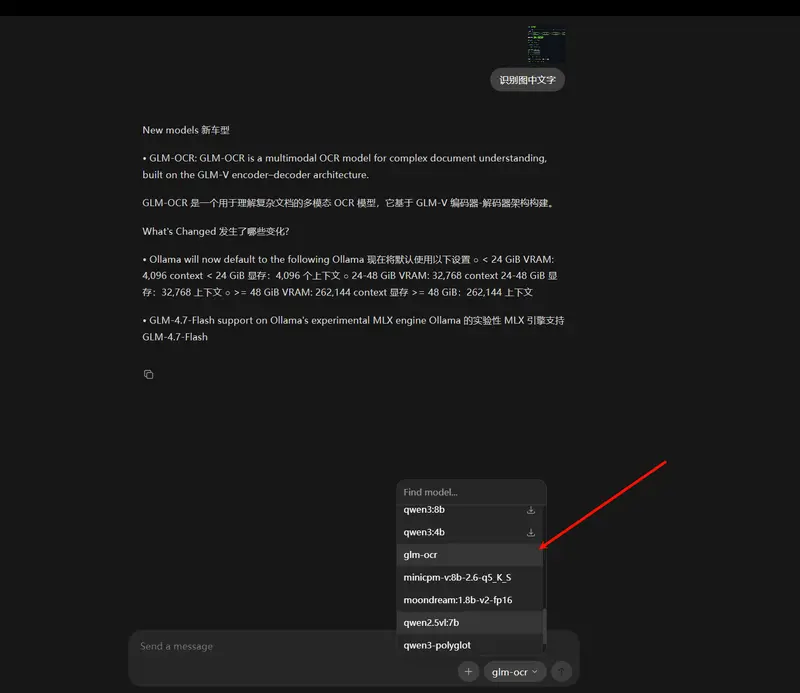
智谱AI开源GLM-OCR:0.9B参数拿下榜单第一,支持vLLM部署,一行命令就能用智谱AI又放出一款实用开源模型——GLM-OCR,这是一款专为复杂文档理解打造的多模态OCR模型,不仅在权威基准测试中拿下综合第一,还做到了轻量高效、易部署,关键是完全开源,个人和企业都能免费使用。 ...多模态模型# GLM-OCR# 智谱AI1个月前02230
优必选开源具身智能大模型Thinker:小参数、高性能,专为工业人形机器人打造过去一年,人形机器人在实验室环境中的“场景理解”与“任务规划”能力突飞猛进。然而,一旦进入真实的工业产线,它们便常常陷入“想得到但抓不准、算得出但跟不上”的困境。这背后,是长期存在的鸿沟:空间层面的度...多模态模型# Thinker# 优必选# 具身智能大模型1个月前0280
商汤开源 SenseNova-MARS:多模态自主推理模型登顶 MMSearch 榜单商汤科技正式开源 SenseNova-MARS —— 一款支持动态视觉推理与图文搜索深度融合的多模态大模型(VLM)。该模型提供 8B 与 32B 双版本,在多模态搜索与推理核心基准 MMSearch...多模态模型# SenseNova-MARS# 商汤1个月前0390
Gemini 3 Flash 引入智能体视觉:视觉推理+代码执行,答案基于视觉证据谷歌正式为 Gemini 3 Flash 推出全新能力——智能体视觉,通过将视觉推理与代码执行深度结合,让AI从“静态一瞥”升级为“主动调查”,彻底改变图像理解方式。这项功能可使多数视觉基准测试质量提...多模态模型# Gemini 3 Flash# 智能体视觉1个月前0310
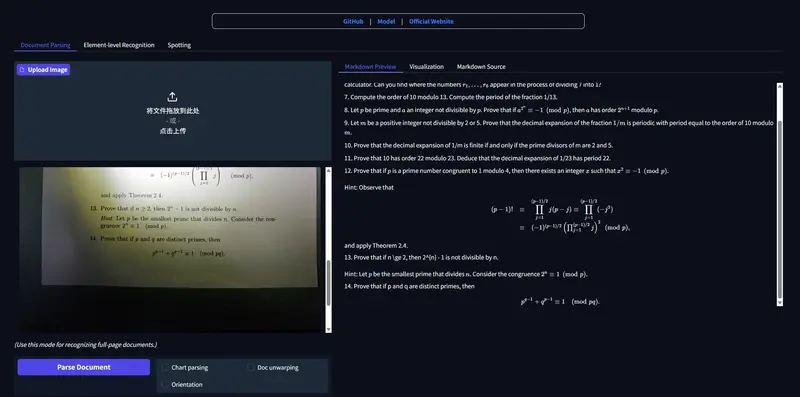
百度飞桨发布PaddleOCR-VL-1.5:0.9B轻量多模态模型,真实场景文档解析全面SOTA百度飞桨近期完成 PaddleOCR 3.4.0 版本更新,正式推出新一代视觉语言模型 PaddleOCR-VL-1.5。这款面向真实场景的文档解析专用模型,仅0.9B参数量却实现资源高效与性能领先...多模态模型# PaddleOCR-VL-1.5# 百度飞桨1个月前0550
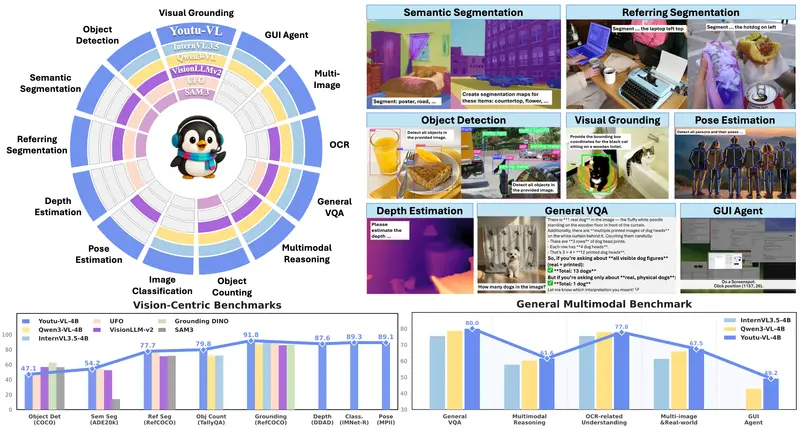
腾讯优图发布 Youtu-VL:40 亿参数轻量模型,统一处理视觉与语言任务腾讯优图实验室近日开源了 Youtu-VL——一款仅有 40 亿参数 的轻量级视觉语言模型(VLM),却能在无需任务专用模块的前提下,同时胜任通用多模态任务与高难度的以视觉为中心的任务(如图像分割、深...多模态模型# Youtu-VL1个月前01150
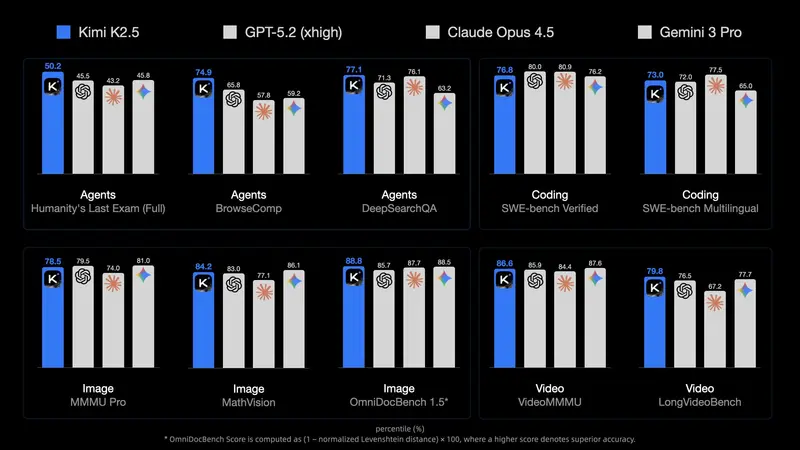
月之暗面开源最强多模态模型 Kimi K2.5,支持百智能体协同与视觉编程月之暗面(Moonshot AI)正式发布 Kimi K2.5——目前最强的开源多模态大模型。它在 Kimi K2 基础上,基于约 15 万亿混合视觉-文本 Token 进行预训练,不仅在编码与视觉理...多模态模型# Kimi K2.5# 月之暗面1个月前0250
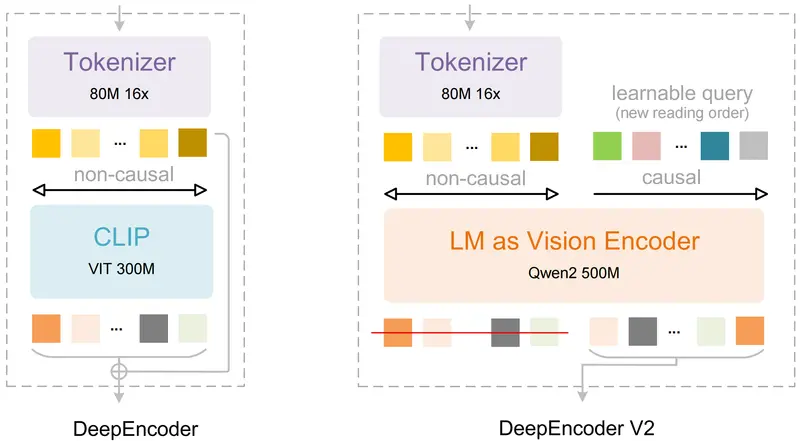
DeepSeek-OCR-V2:用 LLM 替代 CLIP,让 OCR 学会“像人一样阅读”DeepSeek 发布 OCR-V2,这不是一次常规升级,而是一次架构级革新:彻底弃用 CLIP 视觉编码器,改用小型 LLM(Qwen2-0.5B)作为视觉编码器,并引入 “视觉因果流”(Visua...多模态模型# DeepSeek-OCR-V2# OCR模型1个月前0500
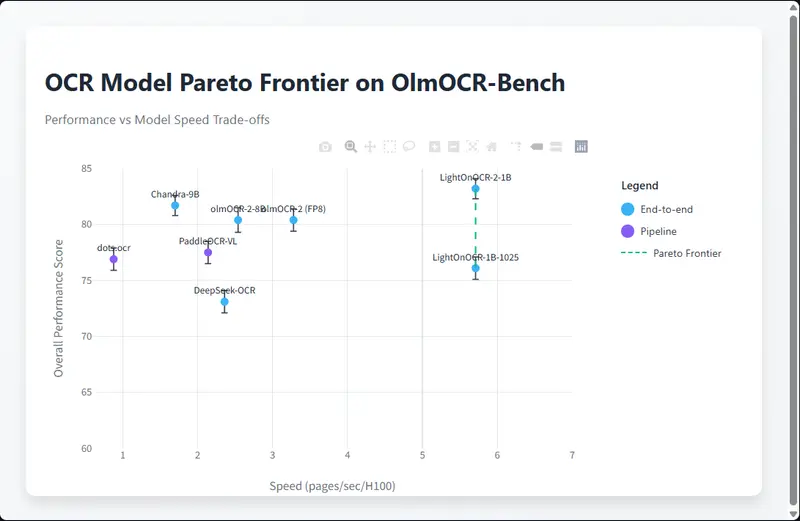
LightOn AI推出的第二代模型 LightOnOCR-2-1B:1B 参数端到端 OCR 模型,支持边界框输出在文档数字化处理领域,兼顾高精度转录、轻量化部署、高效推理的OCR模型一直是行业刚需。LightOn AI推出的第二代模型 LightOnOCR-2-1B,以1B参数量实现端到端PDF文档转写能力,不...多模态模型# LightOn AI# LightOnOCR-2-1B# OCR 模型2个月前0820