腾讯优图实验室推出 Youtu-LLM:持 128K 上下文、本地运行,专为端侧 AI 设计在大模型普遍走向百亿、千亿参数的今天,腾讯优图实验室推出了一款仅 1.96B 参数的轻量级语言模型——Youtu-LLM。它不追求规模堆砌,而是以 STEM 能力与原生智能体(Agentic)能力为核...多模态模型# Youtu-LLM# 腾讯优图实验室2个月前0370
阿里开源 Qwen3-VL 多模态检索模型:Embedding + Reranker 两阶段提升跨模态精度在多模态 AI 应用日益普及的今天,如何高效检索混合了文本、图像、截图甚至视频的内容,仍是技术难点。传统方案往往依赖多个专用模型,导致系统复杂、语义割裂。 官方说明:https://qwen.ai/b...多模态模型# Qwen3-VL-Embedding# Qwen3-VL-Reranker2个月前0390
Yume1.5:用一张图或一段文字,生成可实时探索的虚拟世界想象一下:你上传一张街景照片,或输入一句描述——“一个穿风衣的男人走在雨夜的东京街头,霓虹灯闪烁,远处有全息广告”——模型随即生成一个可自由行走、视角可调、事件可触发的动态 3D 世界。你用键盘控制角...多模态模型# Yume1.5# 世界模型2个月前0330
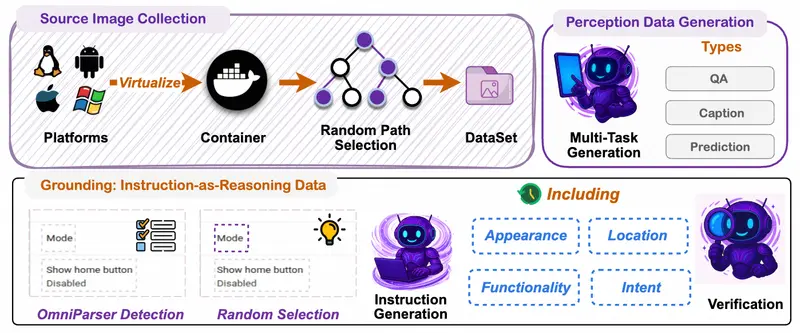
阿里通义开源 MAI-UI:32B 模型 GUI 定位超 Gemini-3-Pro,端云协同重构智能体交互阿里通义实验室近日开源 MAI-UI —— 一个面向真实世界部署的 通用 GUI(图形用户界面)智能体基座模型系列,涵盖 2B、8B、32B 和 235B-A22B 四种规模。其 32B 版本在 Sc...多模态模型# MAI-UI# 通用 GUI模型2个月前0680
VideoRAG:用知识图谱和多模态检索让大模型理解多小时视频当前的大语言模型(LLMs)在处理短视频时已表现出强大能力,但面对数小时甚至跨集的长视频(如讲座系列、纪录片、剧集),它们往往力不从心——上下文窗口有限、计算成本高、跨场景语义断裂。 GitHub:h...多模态模型# VideoRAG# 多模态检索# 知识图谱2个月前0370
Google DeepMind发布T5Gemma 2:支持多模态与 128K 上下文的高效编码器-解码器模型Google DeepMind 正式推出 T5Gemma 2——新一代基于 Gemma 3 架构的编码器-解码器(Encoder-Decoder)模型系列。它不仅继承了 Gemma 3 的先进特性,更...多模态模型# Google DeepMind# T5Gemma 23个月前0300
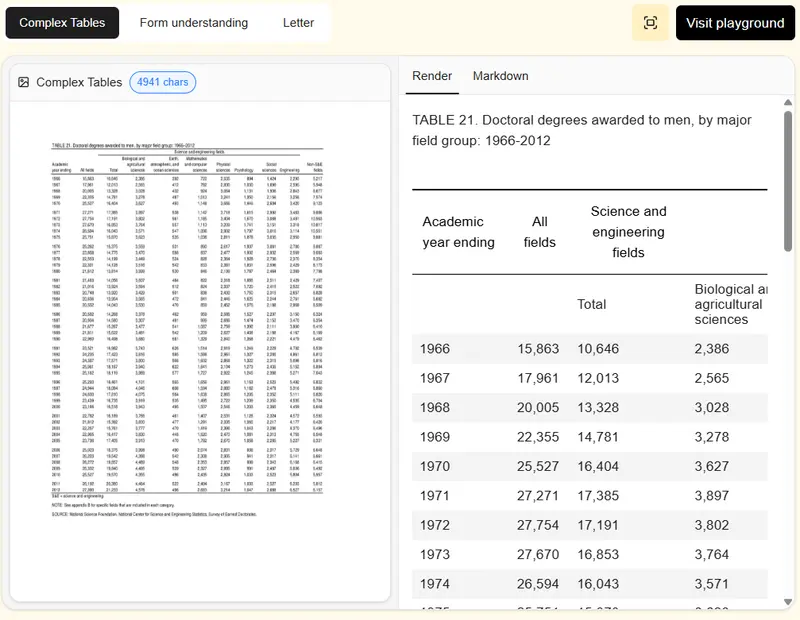
Mistral OCR 3 发布:手写、表格、低质量扫描件识别全面升级Mistral AI 正式推出 Mistral OCR 3,其在复杂文档场景下的识别准确率显著超越前代模型与主流竞品。该模型专注于真实业务环境中的多样化文档——从手写批注、低质量扫描件到多层级表格...多模态模型# Mistral OCR 33个月前0310
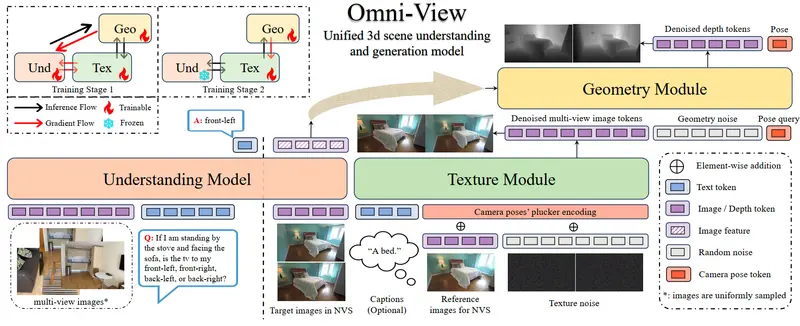
Omni-View:通过生成任务增强3D场景理解的统一模型北京大学、阿里巴巴国际数字商业集团、中国科学院自动化研究所与 TeleAI 联合提出 Omni-View —— 一个面向多视角图像输入的统一3D场景理解与生成模型。该工作首次在端到端框架中系统性验证了...多模态模型# Omni-View3个月前0260
Dolphin-v2:字节跳动发布支持21类元素的通用文档解析模型在办公自动化、知识管理与智能体工作流中,将非结构化文档转化为结构化数据是关键第一步。然而,现实中的文档来源复杂:既有干净的 PDF、Word,也有手机拍摄的带畸变、阴影、模糊的纸质文件。现有解析模型往...多模态模型# Dolphin-v2# 字节跳动# 文档解析模型3个月前01390
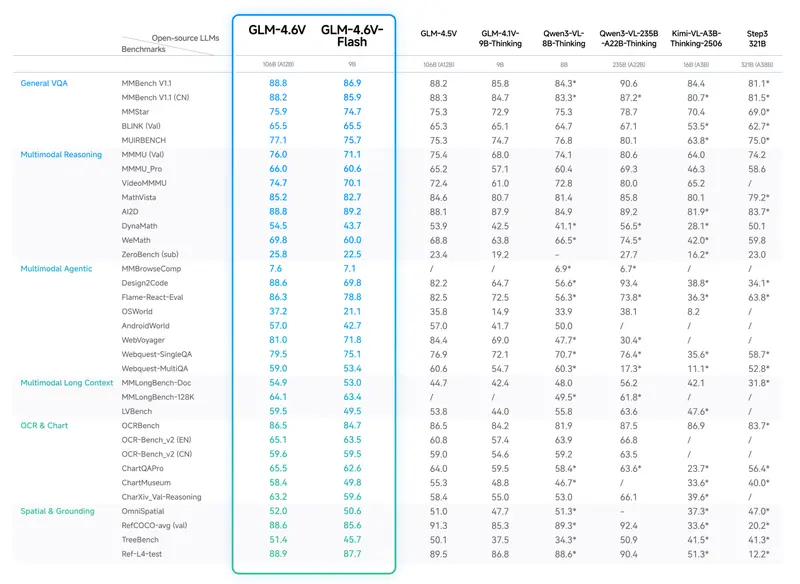
智谱AI开源GLM-4.6V:128K上下文视觉语言模型,原生工具调用打通感知与执行链路智谱AI正式推出并开源 GLM-4.6V 系列多模态大语言模型,包含面向云端与高性能集群的 GLM-4.6V (106B) 基础模型,以及针对本地部署和低延迟场景优化的 GLM-4.6V-Flash ...多模态模型# GLM-4.6V# 智谱AI3个月前0260
Mistral AI正式发布Mistral 3系列模型:开源多模态模型家族,覆盖从边缘到企业级场景Mistral AI 正式推出新一代模型系列 Mistral 3,此次发布不仅包含适配边缘场景的 Ministral 3 系列小型密集模型,更带来了性能顶尖的稀疏专家混合模型 Mistral Larg...多模态模型# Mistral 3# Mistral AI# Mistral Large 33个月前01090
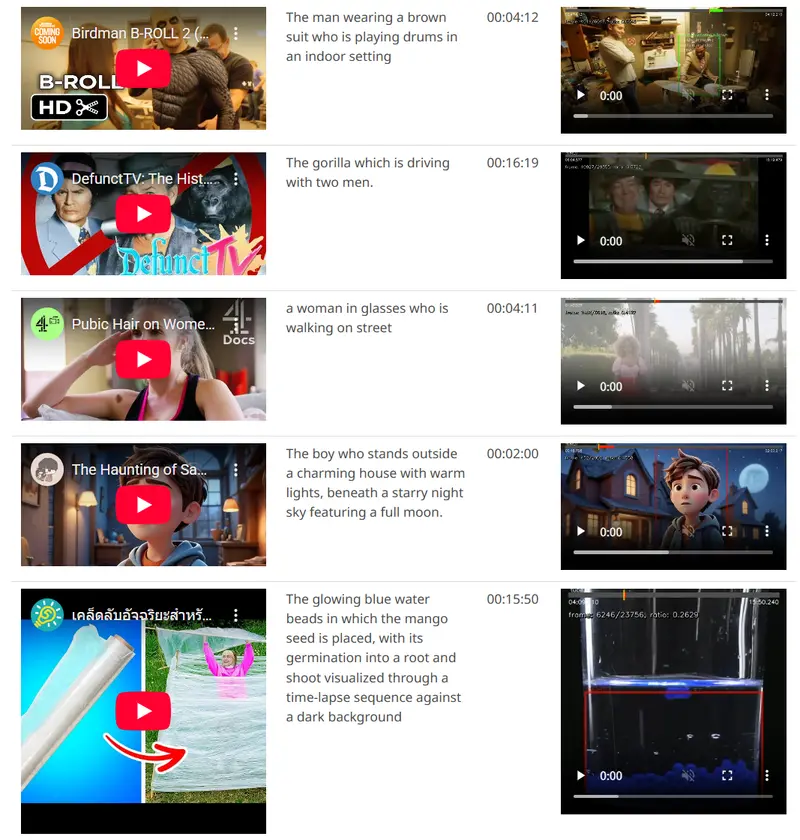
字节跳动发布Vidi2:攻克细粒度时空定位,视频检索性能领先GPT - 5字节跳动智能创作团队推出的第二代多模态视频模型Vidi2,凭借在时空定位、时间检索和视频问答三大核心能力上的突破,打破了传统视频模型在长视频理解和精细交互上的局限。该模型不仅在核心任务中实现对Gemi...多模态模型# Vidi2# 多模态视频模型# 字节跳动3个月前01800