Meta AI发布SAM 3:支持文本/图像双提示,图像视频分割性能翻Meta 近日推出 Segment Anything 系列新一代模型——SAM 3,首次实现文本、图像示例双提示驱动的开放式概念分割,可精准识别并分割“带红色条纹的雨伞”等细粒度概念,在图像与视频分割...多模态模型# Meta AI# SAM 3# 分割模型3个月前0230
腾讯开源HunyuanOCR:以1B参数覆盖9大场景,支持百种语言在OCR领域常陷入“大参数换高性能”的内卷时,腾讯混元于11月25日开源的HunyuanOCR,以1B的轻量化参数实现了颠覆性突破。这款依托混元原生多模态架构打造的端到端OCR专家模型,不仅在多项权威...多模态模型# HunyuanOCR3个月前0270
谷歌发布 WeatherNext 2:AI 天气预报模型速度提升 8 倍,精准到小时级谷歌DeepMind与Google Research联合发布全新AI天气预报模型WeatherNext 2,定位为“迄今最先进、最高效的全球天气预报解决方案”。该模型以“速度提升8倍、分辨率达小时级...多模态模型# WeatherNext 2# 天气预报# 谷歌4个月前0910
谷歌 DeepMind 发布 SIMA 2:AI智能体首次在虚拟世界中“自我改进”谷歌DeepMind发布通用AI智能体下一代产品SIMA 2的研究预览,通过深度整合大语言模型Gemini的语言与推理能力,实现从“单纯遵循指令”到“理解环境并互动”的核心突破。这款由Gemini 2...多模态模型# SIMA 2# 谷歌 DeepMind4个月前0380
百度开源ERNIE-4.5-VL-28B-A3B-Thinking:3B活跃参数实现大型模型级多模态推理百度正式开源 ERNIE-4.5-VL-28B-A3B-Thinking,一款专注于文档、图表与视频理解的多模态推理模型。尽管模型总参数达 约 30B,但通过稀疏激活机制,每次推理仅激活 3B 参数...多模态模型# ERNIE-4.5-VL-28B-A3B-Thinking# 多模态推理# 百度4个月前0420
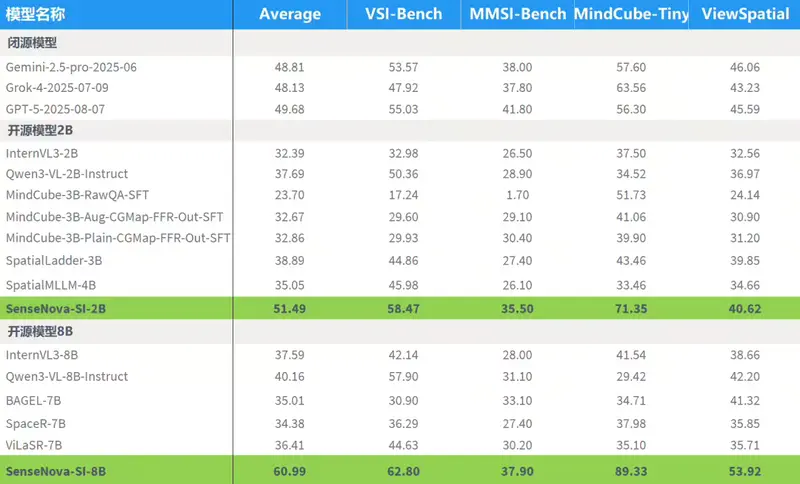
商汤开源SenseNova-SI:面向空间智能的多模态模型当前主流多模态基础模型在文本、图像理解、推理和生成任务上已取得显著进展,但在空间智能(Spatial Intelligence)方面仍存在系统性短板。具体表现为: 对物体尺度、距离、比例的估计不准确 ...多模态模型# SenseNova-SI# 商汤# 空间智能4个月前01330
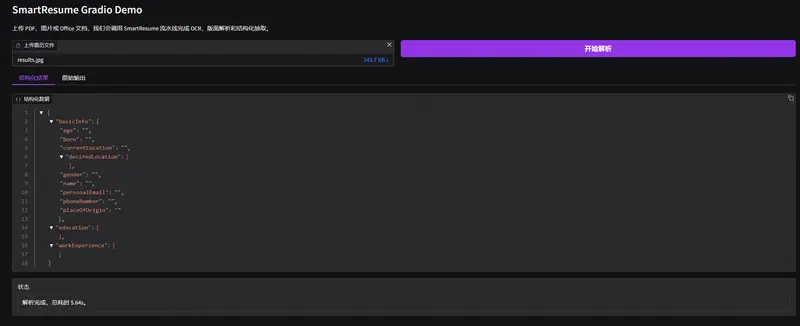
阿里巴巴推出 SmartResume:一个能“读懂”复杂简历版式的智能解析系统在企业招聘中,自动化处理海量简历是刚需,但简历格式千奇百怪——多栏排版、图文混排、表格嵌套,传统文本提取工具常会打乱语义顺序,导致关键信息错位。 针对这一难题,阿里巴巴企业智能团队发布了 SmartR...多模态模型# SmartResume# 智能简历解析# 阿里巴巴4个月前01870
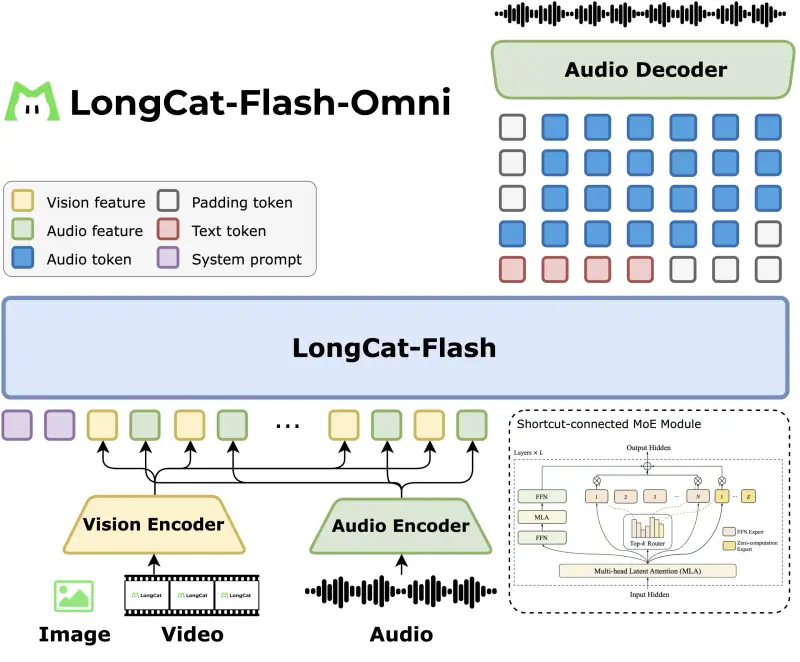
美团发布LongCat-Flash-Omni:开源全模态大模型的实时交互新标杆美团 LongCat 团队近日开源了 LongCat-Flash-Omni —— 一款参数总量达 5600 亿、每 token 动态激活 270 亿参数 的 全模态大模型(Full-Modal LLM...多模态模型# LongCat-Flash-Omni# 美团4个月前0160
百度飞桨发布 PaddleOCR-VL(0.9B):轻量级端到端多语言文档解析模型百度飞桨团队近日开源 PaddleOCR-VL(0.9B)——一款专为复杂版式文档智能解析设计的视觉语言模型(VLM)。该模型以仅 9亿参数的轻量级架构,实现了对文本、表格、数学公式、图表及手写体的高...多模态模型# PaddleOCR-VL# 文档解析模型4个月前0240
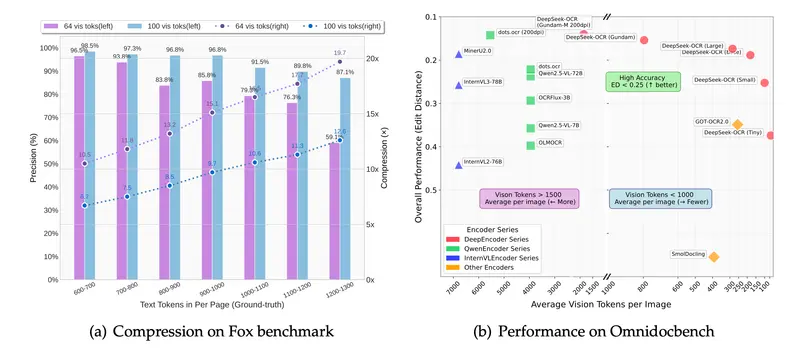
DeepSeek 开源DeepSeek-OCR :用视觉模态压缩文本,3B 小模型撬动长上下文新思路DeepSeek 开源了 DeepSeek-OCR,一个仅 30 亿参数的视觉语言模型(VLM),却在 OCR 与文本压缩领域展现出令人瞩目的创新力。其核心并非追求更大参数量,而是提出一种“光学压缩...多模态模型# DeepSeek# DeepSeek-OCR5个月前01800
Nanonets开源OCR2系列模型:图像转结构化Markdown+视觉问答双核心Nanonets 正式发布并开源了 OCR2 系列模型,包含 Nanonets-OCR2-Plus、Nanonets-OCR2-3B 与 Nanonets-OCR2-1.5B-exp 三个版本。作为一...多模态模型# Nanonets-OCR2# Qwen2-VL5个月前02290
阿里巴巴 Qwen 推出紧凑型多模态模型 Qwen3-VL 4B/8B,支持 FP8 低显存部署阿里巴巴通义千问(Qwen)团队于 2025 年 10 月 15 日正式发布 Qwen3-VL 4B 与 8B 两款稠密视觉语言模型,每款均提供 指令版(Instruction) 与 思维版(Reas...多模态模型# Qwen3-VL 4B# Qwen3-VL 8B# 多模态模型5个月前03210