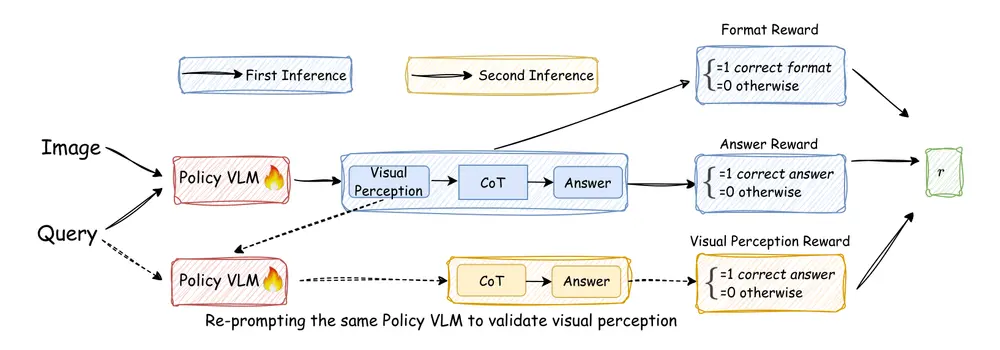
阿里巴巴通义千问(Qwen)团队于 2025 年 10 月 15 日正式发布 Qwen3-VL 4B 与 8B 两款稠密视觉语言模型,每款均提供 指令版(Instruction) 与 思维版(Reasoning) 两种任务配置,并同步开放 FP8 量化检查点,显著降低部署门槛。
- GitHub:https://github.com/QwenLM/Qwen3-VL
- 模型:https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe
此举旨在为 单 GPU 或边缘计算场景 提供高性能、低资源消耗的多模态推理方案,作为此前 30B 和 235B 混合专家(MoE)版本的轻量级补充。
核心特性:小模型,全功能
尽管参数规模大幅压缩(4B 模型约 48.3 亿参数,8B 约 87.7 亿),新模型完整保留 Qwen3-VL 全套能力,包括:
- 超长上下文支持:原生 256K,可扩展至 100 万 token
- 多语言 OCR:支持 32 种语言 的文本识别
- 空间理解:2D/3D 物体定位、坐标推理
- 视频理解:长时序视频事件分析
- 智能体控制:可操作桌面或移动端 GUI,支持视觉编程
这些能力使其适用于文档解析、智能客服、机器人视觉导航、自动化测试等实际场景。
架构延续:三大核心技术下放
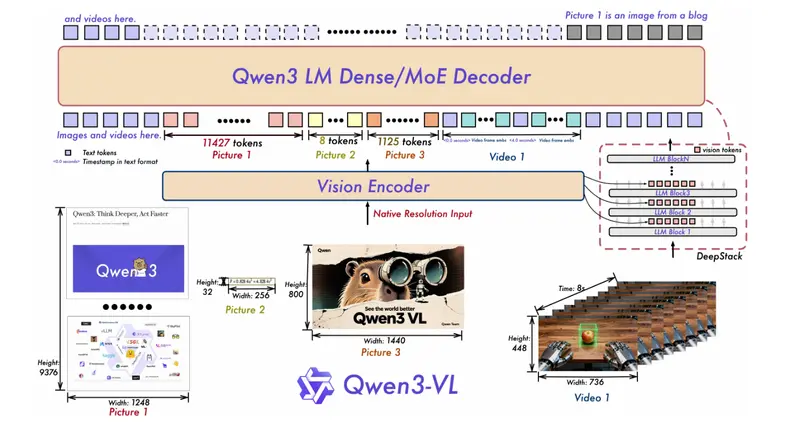
Qwen3-VL 4B/8B 继承了大模型的核心架构设计:
- Interleaved-MRoPE:支持图像、文本、视频交错输入的长序列位置编码
- DeepStack ViT:融合多层级视觉特征,提升图文对齐精度
- Text–Timestamp Alignment:实现视频中事件与文本描述的精准对齐
这确保了小模型在保持轻量的同时,不牺牲多模态理解的深度。
FP8 量化:为低显存环境优化
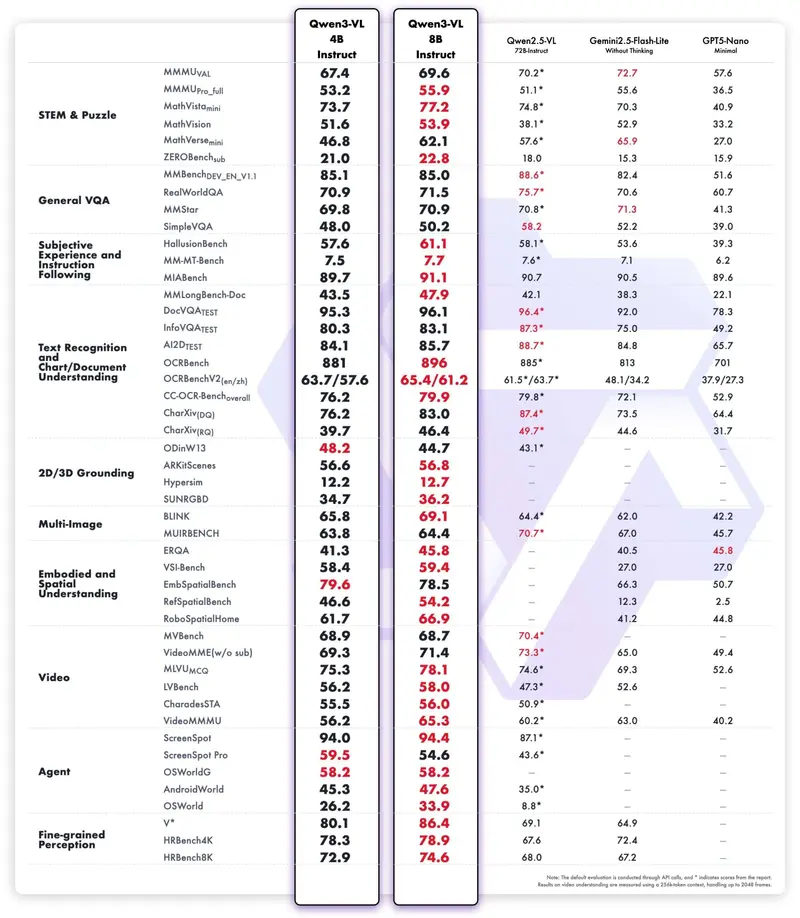
为提升部署效率,Qwen 团队同步发布 FP8 量化版本:
- 采用 块大小为 128 的细粒度量化,推理精度接近原始 BF16 模型
- 显著降低显存占用,适配 H100 等支持 FP8 的 GPU
- 暂不支持 Hugging Face Transformers 直接加载,推荐使用 vLLM 或 SGLang 部署
- 官方提供启动代码与部署指南,开箱即用
这一策略大幅减少开发者自行量化与验证的成本,加速落地。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











