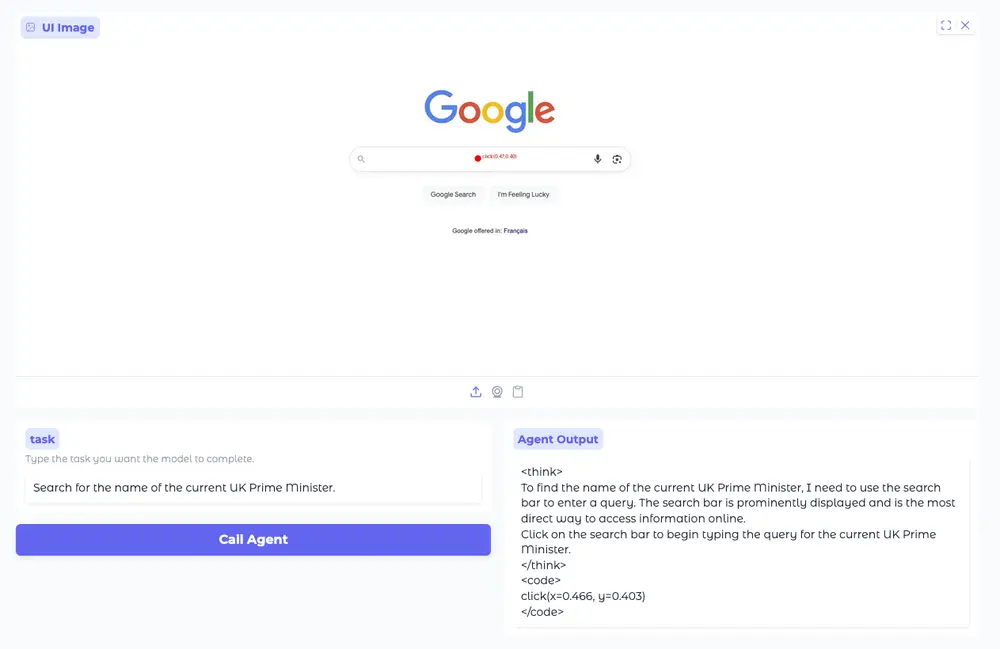
谷歌推出新型 AI 模型Gemini 2.5 Computer Use,可操作浏览器完成网页任务谷歌发布一款名为 Gemini 2.5 Computer Use 的新型 AI 模型,能够通过浏览器窗口执行点击、滚动、输入文本等交互操作,帮助用户在那些没有开放 API 的网站上自动完成任务。 这项...多模态模型# Gemini 2.5 Computer Use# 谷歌5个月前02010
阿里通义实验室发布 Qwen3-VL:迄今最强视觉语言模型,全面开源阿里通义实验室 Qwen 项目组正式推出全新升级的 Qwen3-VL 系列——这是截至目前 Qwen 多模态体系中能力最全面、性能最先进的视觉语言模型(Vision-Language Model, V...多模态模型# Qwen3-VL# 视觉语言模型6个月前04100
Hugging Face推出Smol2Operator:让小模型学会操作图形界面在人机交互日益复杂的今天,一个长期被忽视的问题是: 我们能让AI像人类一样“使用”计算机吗? 不是生成文本或识别图像,而是真正理解屏幕上的按钮、输入框、菜单,并通过点击、滑动、输入等动作完成任务——这...多模态模型# Hugging Face# Smol2Operator6个月前01210
阿里通义实验室推出Qwen3-Omni:支持文本、语音、图像、视频的全模态大模型通义实验室正式推出 Qwen3-Omni——一款统一处理多模态输入并支持流式文本与语音输出的大语言模型。该模型已在 Qwen API 平台上线,开发者可通过接口体验其在音频对话、跨模态理解与指令执行方...多模态模型# Qwen3-Omni# 通义实验室6个月前02040
Qianfan-VL:百度推出的多模态大模型系列,面向企业级视觉语言任务由百度 AI 云团队研发,Qianfan-VL 是一系列参数规模从 3B 到 70B 的多模态大语言模型(MLLM),专注于提升企业在文档理解、OCR识别和数学推理等高频场景下的自动化能力。 项目主页...多模态模型# Qianfan-VL# 多模态大模型# 百度6个月前01570
苹果发布多模态统一模型Manzano:能够同时理解和生成视觉内容苹果发布多模态统一模型Manzano,它能够同时理解和生成视觉内容。该模型通过结合一个混合图像标记化器和精心设计的训练方案,显著减少了在理解和生成能力之间的性能权衡。Manzano 在统一模型中实现了...多模态模型# Manzano# 多模态统一模型6个月前01090
视觉-语言模型中的“隐形损耗”:我们如何测量图像信息的丢失?视觉-语言模型(Vision-Language Models, VLMs)如 LLaVA、Qwen-VL 等,在图像理解、视觉问答和图文生成等任务中表现优异。这些模型通常依赖一个核心流程:将图像通过视...多模态模型# 视觉-语言模型6个月前01570
百度发布 PP-OCRv5:0.07亿参数模型,挑战百亿级大模型的OCR精度在通用视觉语言模型(VLM)主导多模态任务的当下,百度飞桨团队反其道而行之,推出新一代轻量级文字识别模型 PP-OCRv5 ——一个仅含 70万参数(0.07B)的超小模型,在多项 OCR 任务中表现...多模态模型# PP-OCRv5# 百度6个月前02930
Mistral AI 发布 Magistral Small 1.2:支持视觉输入的小型高效开源推理模型法国AI初创公司 Mistral AI 本周正式发布并开源其小型语言模型的新版本 —— Magistral Small 1.2。该模型在前代基础上全面升级,不仅提升了数学与编程任务的基准表现,还首次引...多模态模型# Magistral Small 1.2# Mistral AI6个月前02390
Moondream 团队推出 Moondream 3 预览版本:轻量架构下的高性能视觉推理模型Moondream 团队正式推出 Moondream 3 的预览版本——一款基于 9B 参数稀疏混合专家(MoE)架构的新模型,实际激活参数仅为 2B。它在保持极快推理速度和低运行成本的同时,实现了接...多模态模型# Moondream 3# 视觉推理模型6个月前05790
IBM 推出 Granite Docling:专为文档转换优化的轻量级多模态模型IBM Research 正式发布 Granite Docling-258M,一款基于 IDEFICS3 架构构建的新型多模态图像-文本到文本模型,专为高效、准确的文档理解与结构化转换而设计。 Git...多模态模型# Granite Docling-258M# 多模态模型# 文档转换6个月前01000
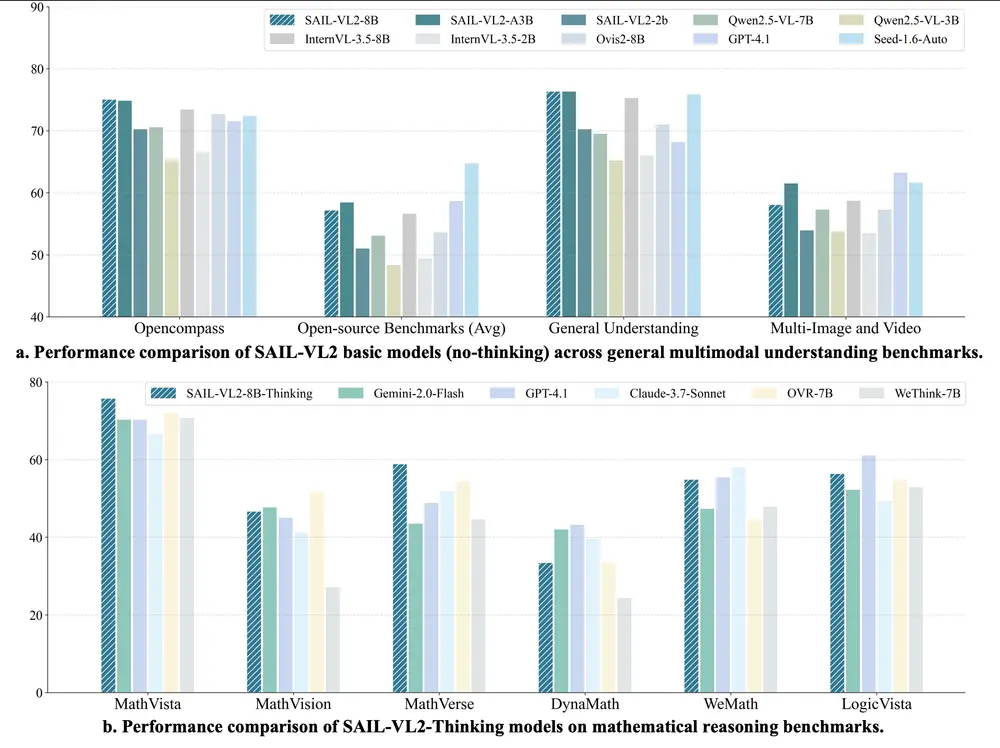
抖音推出SAIL-VL2:面向细粒度感知与复杂推理的新一代开源视觉语言模型由抖音 SAIL 团队与新加坡国立大学 LV-NUS 实验室联合研发,SAIL-VL2 是一款全新的开源视觉语言基础模型(Vision-Language Model, LVM),在 2B 和 8B 参...多模态模型# SAIL-VL2# 抖音# 视觉语言模型6个月前03230