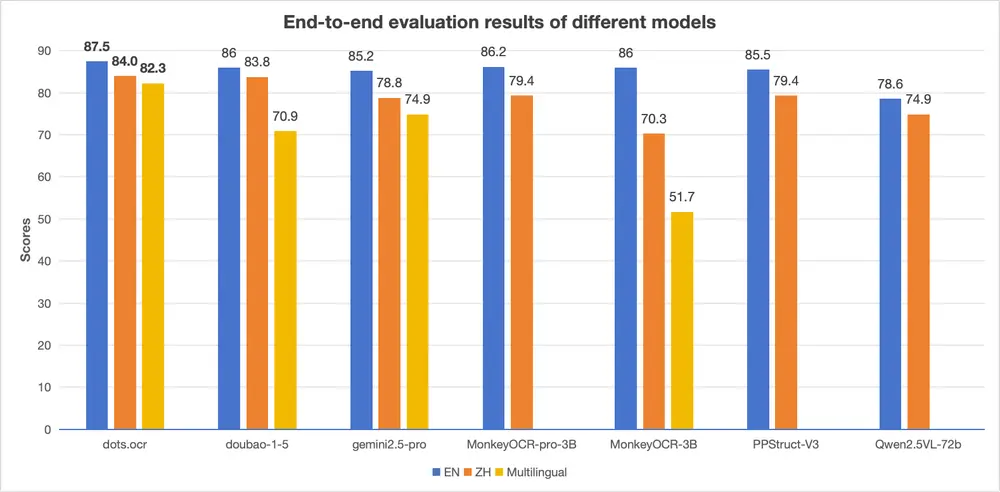
小红书 hi lab 推出 dots.ocr:一个更高效、更统一的文档解析方案小红书 hi lab 团队近期发布了一款名为 dots.ocr 的多语言文档解析模型。它不是传统OCR工具的简单升级,而是一次架构层面的重构——将布局检测与内容识别统一在一个视觉-语言模型(VLM)中...多模态模型# dots.ocr# 小红书6个月前01,1000
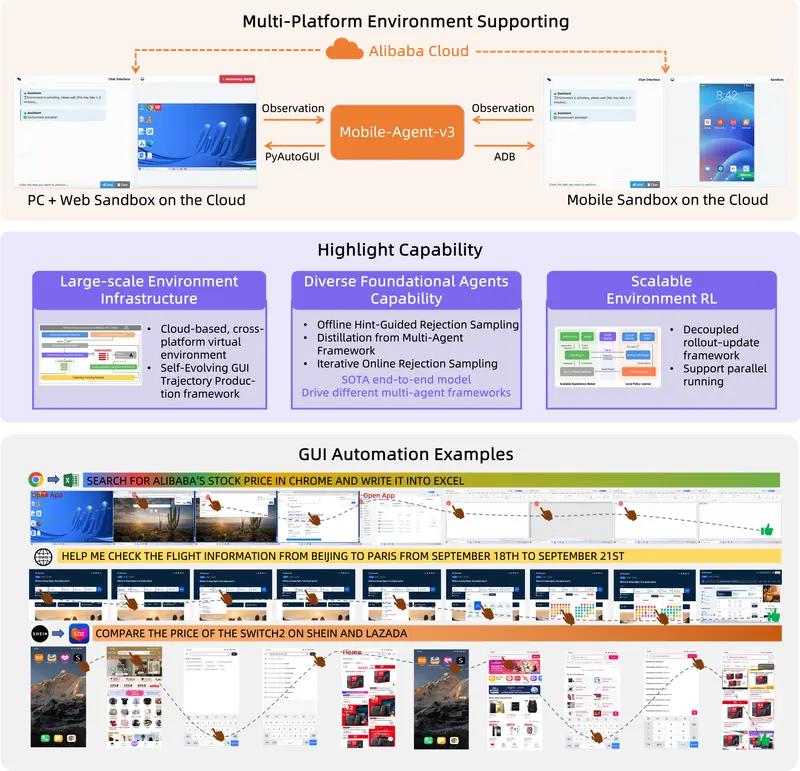
阿里通义实验室推出 Mobile-Agent-v3 框架:为图形用户界面(GUI)任务的自动化带来了全新的解决方案在当今数字化时代,自动化技术的发展日新月异。阿里通义实验室作为行业内的创新先锋,于近期推出了令人瞩目的Mobile-Agent-v3框架,为图形用户界面(GUI)任务的自动化带来了全新的解决方案。 G...多模态模型# Mobile-Agent-v3# 图形用户界面# 通义实验室5个月前09380
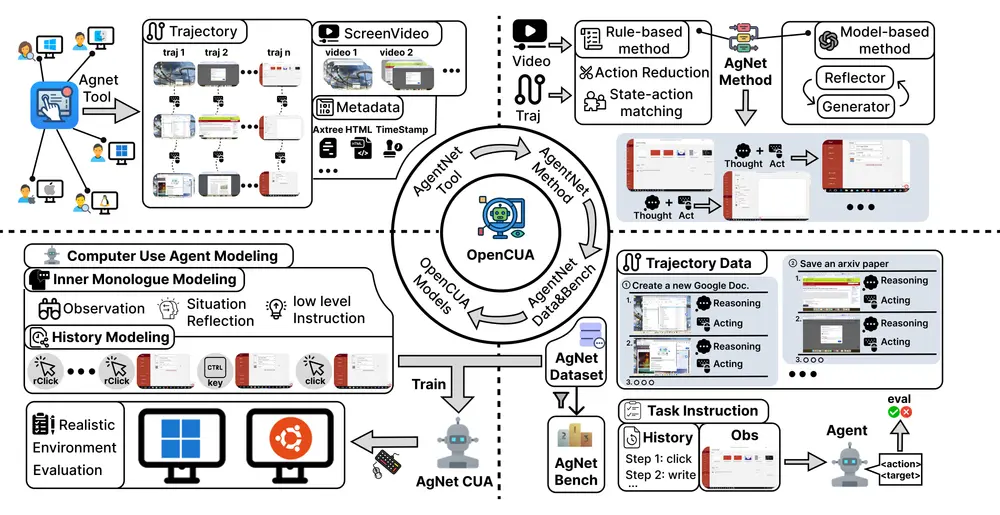
OpenCUA:首个开源的计算机使用智能体框架发布你是否曾希望有一个 AI 助手,能像你一样操作电脑——打开浏览器查资料、在 Excel 中整理数据、切换应用完成多步骤任务?如今,这类被称为“计算机使用智能体”(Computer Use Agents...多模态模型# OpenCUA# 智能体框架6个月前09220
深度求索推出新颖自回归框架 Janus: 具有图像生成功能的 13 亿多模态模型多模态AI模型是能够理解和生成视觉内容的强大工具。然而,现有方法通常使用单一视觉编码器来处理这两项任务,这导致了由于理解和生成在本质上不同的需求而表现不佳。理解需要高层次的语义抽象,而生成则关注局部细...多模态模型# Janus# 多模态模型12个月前09090
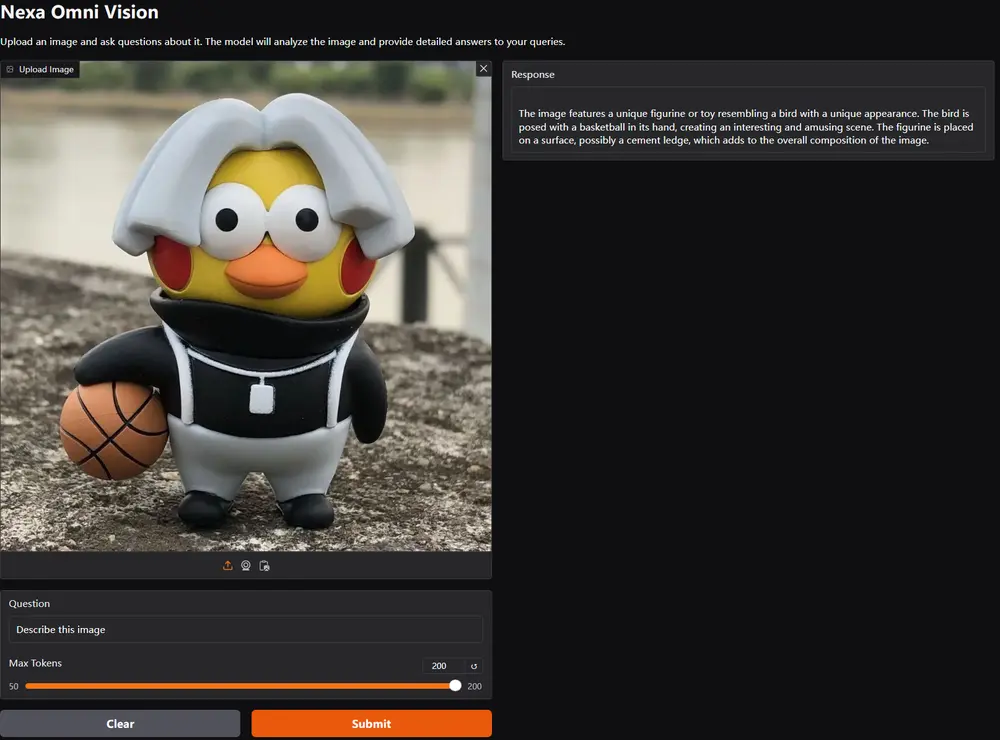
Nexa AI 推出迷你视觉语言模型 OmniVision-968MNexa AI 最新发布了 OmniVision-968M,这是一款专为边缘设备设计的视觉语言模型,它通过技术创新,将图像标记数量大幅减少,显著降低了延迟和计算负担,还提升了处理速度,为边缘计算领域带...多模态模型# Nexa AI# OmniVision-968M# 视觉语言模型12个月前07350
新型目标检测模型Mamba-YOLO-World:能够理解并识别各种不同物体的智能系统,即使这些物体在训练时没有被明确标记复旦大学计算机学院、腾讯优图实验室、上海交通大学等的研究人体推出新型目标检测模型Mamba-YOLO-World,它专门设计用于开放词汇检测(Open-Vocabulary Detection,简称O...多模态模型# Mamba-YOLO-World# 目标检测模型12个月前06740
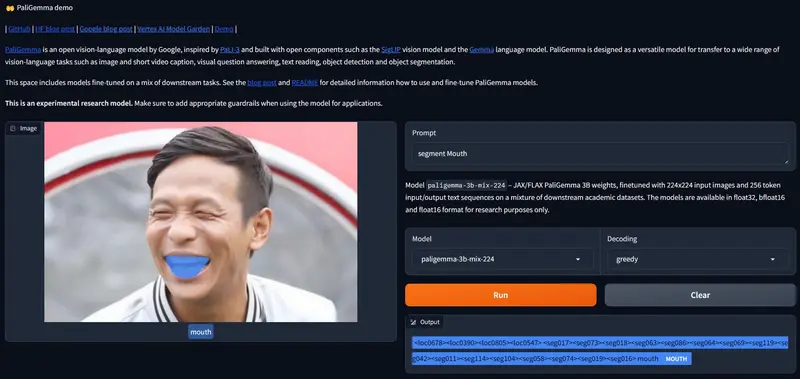
设计灵感来源于PaLI-3!谷歌推出开源视觉语言模型PaliGemmaPaliGemma 是谷歌推出的新一代视觉语言模型家族,其设计灵感来源于PaLI-3,能够接收图像与文本输入并生成文本输出。PaliGemma建立在包括SigLIP视觉模型和Gemma语言模型在内的开...多模态模型# PaliGemma# 谷歌12个月前06530
新型CLIP专家混合模型CLIP-MoE:可以无缝替换CLIP,以即插即用的方式,而无需在下游框架中进一步适应香港中文大学、上海人工智能实验室和舒尔茨大学的研究人员推出新型CLIP模型CLIP-MoE,它是为了增强现有的多模态智能模型CLIP而设计的。CLIP-MoE可以无缝替换CLIP,以即插即用的方式,而...多模态模型# CLIP-MoE# 多模态智能模型12个月前05860
英伟达推出多模态大语言模型Describe Anything 3B:为图像和视频局部描述量身定制的多模态 AI 模型英伟达、加州大学伯克利分校和加州大学旧金山分校的研究人员推出了 Describe Anything 3B (DAM-3B),这是一个专门用于生成细粒度图像和视频字幕的多模态大语言模型(LLM)。DAM...多模态模型# Describe Anything 3B# 多模态大语言模型# 英伟达9个月前05830
多模态大语言模型Qwen2-VL-7B-Captioner-Relaxed:经过指令调整的Qwen2-VL-7B-Instruct版本Qwen2-VL-7B-Captioner-Relaxed 是 Qwen2-VL-7B-Instruct 的一个经过指令调整的版本,它是一个多模态大语言模型。这个经过精细调整的版本是基于一个为文生图模...多模态模型# Qwen2-VL-7B-Captioner-Relaxed# 多模态大语言模型12个月前05630
大型多模态模型LLaVA-Video:专门设计来处理视频指令并进行视频内容理解字节跳动、南洋理工大学S-Lab和北京邮电大学的研究人员推出大型多模态模型LLaVA-Video,专门设计来处理视频指令并进行视频内容理解。这个模型特别擅长于解析和生成与视频内容相关的语言描述,比如详...多模态模型# LLaVA-Video# 多模态模型12个月前05600
面壁智能发布 MiniCPM-V 4.5:8B 参数模型实现多模态能力新突破面壁智能正式推出其最新视觉语言模型 MiniCPM-V 4.5,这是 MiniCPM-V 系列中性能最强、功能最全面的版本。该模型在保持 80 亿参数规模的前提下,实现了在视觉理解、视频处理、文档解析...多模态模型# MiniCPM-V 4.5# 面壁智能5个月前05460