新Gemini 3 Flash 引入智能体视觉:视觉推理+代码执行,答案基于视觉证据谷歌正式为 Gemini 3 Flash 推出全新能力——智能体视觉,通过将视觉推理与代码执行深度结合,让AI从“静态一瞥”升级为“主动调查”,彻底改变图像理解方式。这项功能可使多数视觉基准测试质量提...多模态模型# Gemini 3 Flash# 智能体视觉10小时前070
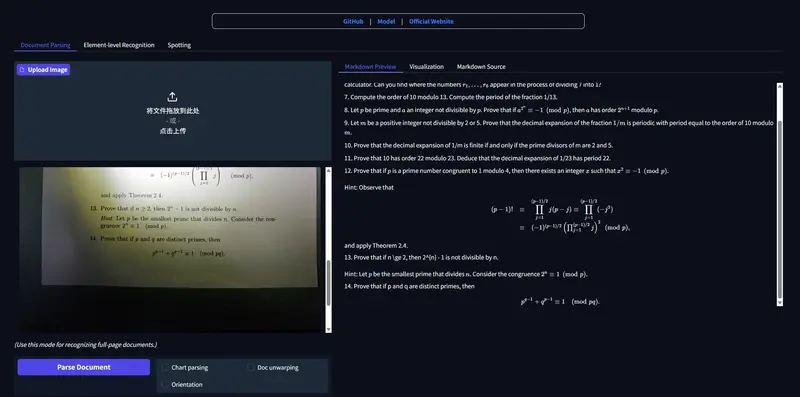
新百度飞桨发布PaddleOCR-VL-1.5:0.9B轻量多模态模型,真实场景文档解析全面SOTA百度飞桨近期完成 PaddleOCR 3.4.0 版本更新,正式推出新一代视觉语言模型 PaddleOCR-VL-1.5。这款面向真实场景的文档解析专用模型,仅0.9B参数量却实现资源高效与性能领先...多模态模型# PaddleOCR-VL-1.5# 百度飞桨11小时前0120
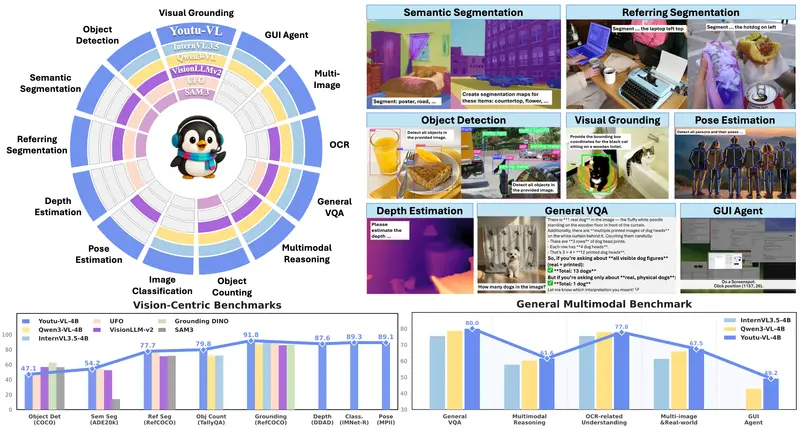
新腾讯优图发布 Youtu-VL:40 亿参数轻量模型,统一处理视觉与语言任务腾讯优图实验室近日开源了 Youtu-VL——一款仅有 40 亿参数 的轻量级视觉语言模型(VLM),却能在无需任务专用模块的前提下,同时胜任通用多模态任务与高难度的以视觉为中心的任务(如图像分割、深...多模态模型# Youtu-VL2天前0230
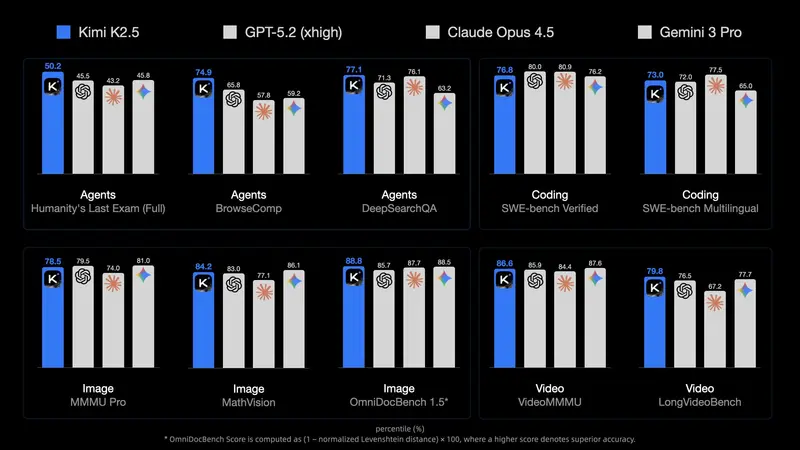
新月之暗面开源最强多模态模型 Kimi K2.5,支持百智能体协同与视觉编程月之暗面(Moonshot AI)正式发布 Kimi K2.5——目前最强的开源多模态大模型。它在 Kimi K2 基础上,基于约 15 万亿混合视觉-文本 Token 进行预训练,不仅在编码与视觉理...多模态模型# Kimi K2.5# 月之暗面3天前050
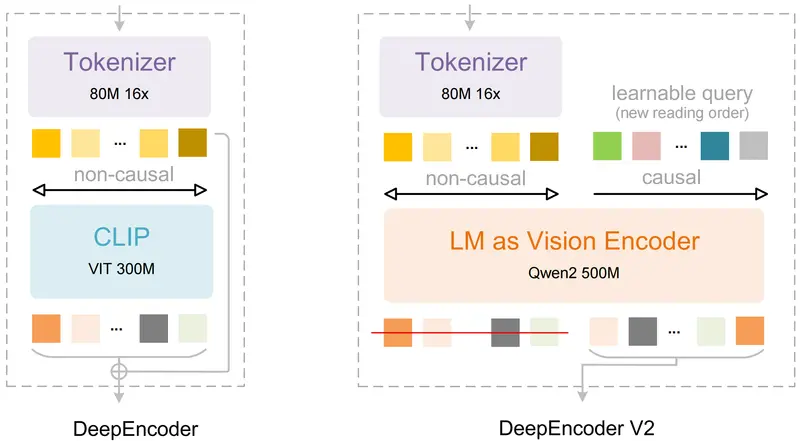
新DeepSeek-OCR-V2:用 LLM 替代 CLIP,让 OCR 学会“像人一样阅读”DeepSeek 发布 OCR-V2,这不是一次常规升级,而是一次架构级革新:彻底弃用 CLIP 视觉编码器,改用小型 LLM(Qwen2-0.5B)作为视觉编码器,并引入 “视觉因果流”(Visua...多模态模型# DeepSeek-OCR-V2# OCR模型3天前0100
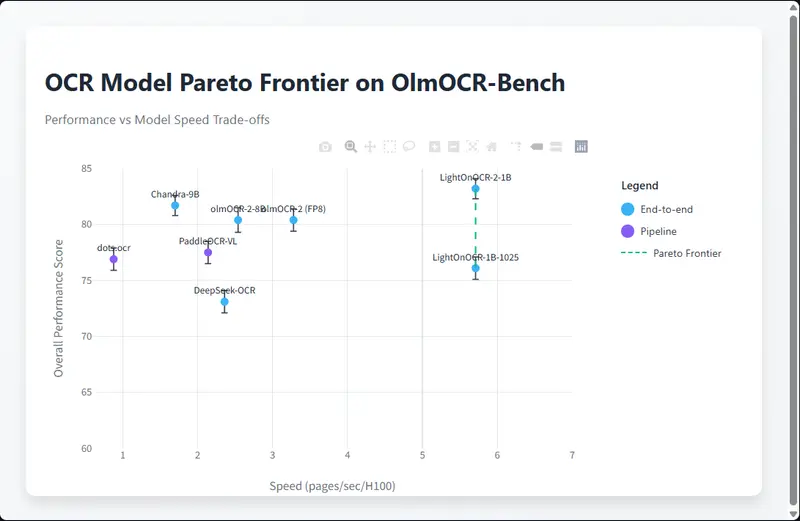
LightOn AI推出的第二代模型 LightOnOCR-2-1B:1B 参数端到端 OCR 模型,支持边界框输出在文档数字化处理领域,兼顾高精度转录、轻量化部署、高效推理的OCR模型一直是行业刚需。LightOn AI推出的第二代模型 LightOnOCR-2-1B,以1B参数量实现端到端PDF文档转写能力,不...多模态模型# LightOn AI# LightOnOCR-2-1B# OCR 模型1周前0500
腾讯优图实验室推出 Youtu-LLM:持 128K 上下文、本地运行,专为端侧 AI 设计在大模型普遍走向百亿、千亿参数的今天,腾讯优图实验室推出了一款仅 1.96B 参数的轻量级语言模型——Youtu-LLM。它不追求规模堆砌,而是以 STEM 能力与原生智能体(Agentic)能力为核...多模态模型# Youtu-LLM# 腾讯优图实验室3周前0210
阿里开源 Qwen3-VL 多模态检索模型:Embedding + Reranker 两阶段提升跨模态精度在多模态 AI 应用日益普及的今天,如何高效检索混合了文本、图像、截图甚至视频的内容,仍是技术难点。传统方案往往依赖多个专用模型,导致系统复杂、语义割裂。 官方说明:https://qwen.ai/b...多模态模型# Qwen3-VL-Embedding# Qwen3-VL-Reranker3周前0290
Yume1.5:用一张图或一段文字,生成可实时探索的虚拟世界想象一下:你上传一张街景照片,或输入一句描述——“一个穿风衣的男人走在雨夜的东京街头,霓虹灯闪烁,远处有全息广告”——模型随即生成一个可自由行走、视角可调、事件可触发的动态 3D 世界。你用键盘控制角...多模态模型# Yume1.5# 世界模型1个月前0210
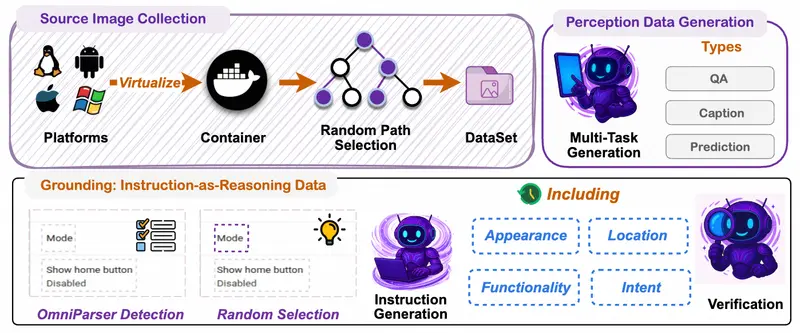
阿里通义开源 MAI-UI:32B 模型 GUI 定位超 Gemini-3-Pro,端云协同重构智能体交互阿里通义实验室近日开源 MAI-UI —— 一个面向真实世界部署的 通用 GUI(图形用户界面)智能体基座模型系列,涵盖 2B、8B、32B 和 235B-A22B 四种规模。其 32B 版本在 Sc...多模态模型# MAI-UI# 通用 GUI模型1个月前0410
VideoRAG:用知识图谱和多模态检索让大模型理解多小时视频当前的大语言模型(LLMs)在处理短视频时已表现出强大能力,但面对数小时甚至跨集的长视频(如讲座系列、纪录片、剧集),它们往往力不从心——上下文窗口有限、计算成本高、跨场景语义断裂。 GitHub:h...多模态模型# VideoRAG# 多模态检索# 知识图谱1个月前0170
Google DeepMind发布T5Gemma 2:支持多模态与 128K 上下文的高效编码器-解码器模型Google DeepMind 正式推出 T5Gemma 2——新一代基于 Gemma 3 架构的编码器-解码器(Encoder-Decoder)模型系列。它不仅继承了 Gemma 3 的先进特性,更...多模态模型# Google DeepMind# T5Gemma 21个月前0250