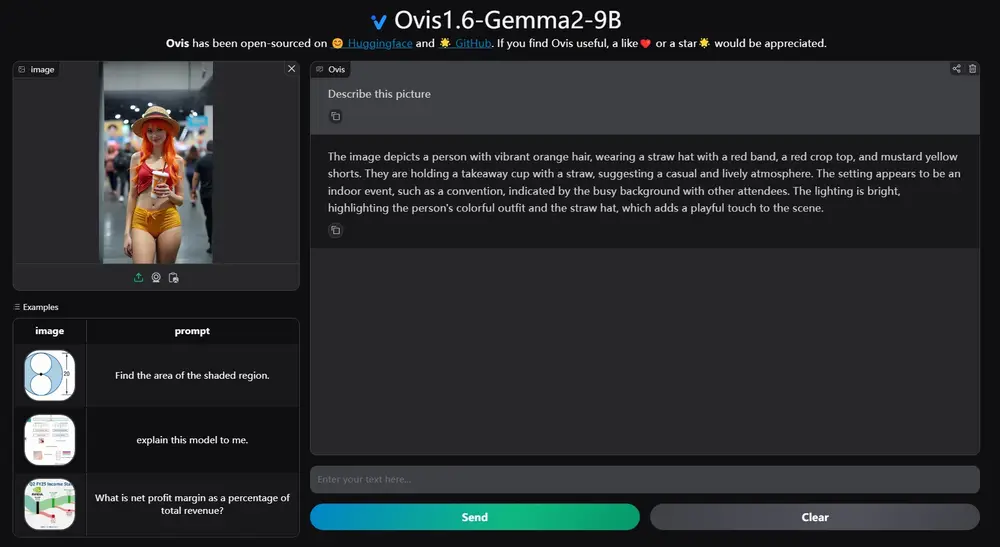
阿里国际推出多模态大语言模型 Ovis1.6-Gemma2-9B:能够同时处理和理解文本和视觉信息 Ovis1.6-Gemma2-9B是阿里国际推出的一款多模态大语言模型,Ovis是一种新颖的多模态大语言模型(MLLM)架构,旨在结构化地对齐视觉和文本嵌入。Ovis1.6-Gemma2-9B基于O...多模态模型# Ovis1.6-Gemma2-9B# 多模态大语言模型12个月前05430
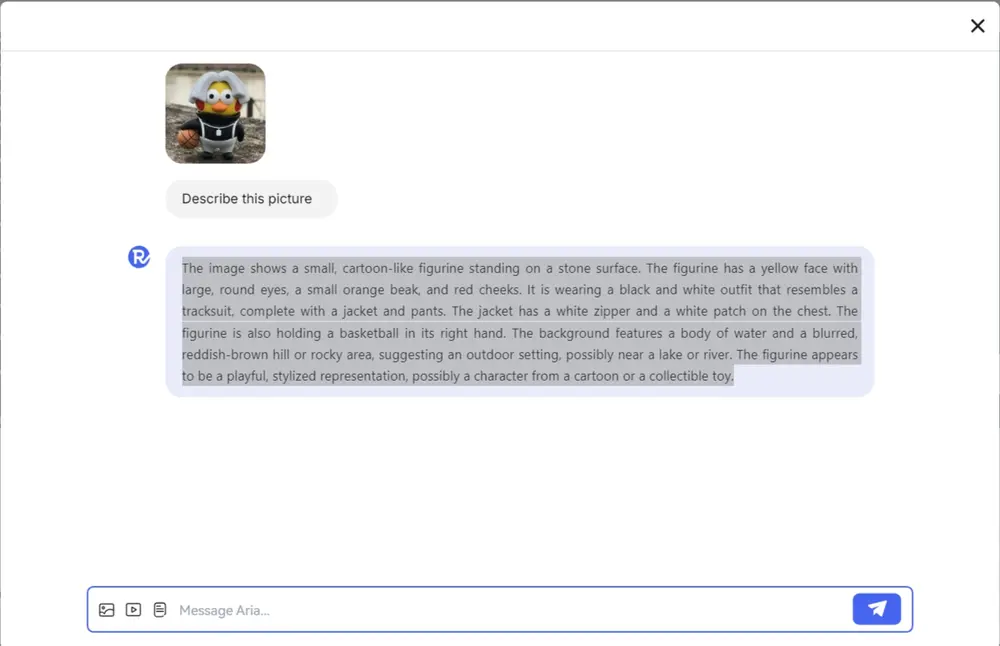
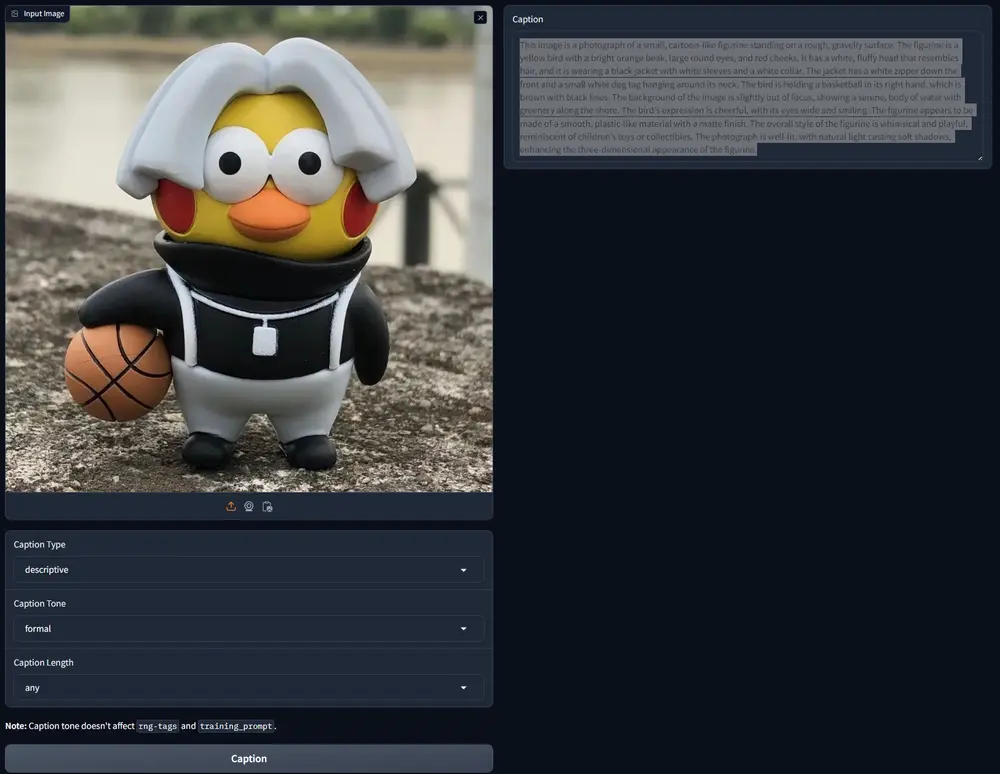
新型多模态原生模型Aria:专门设计来处理和理解多种类型的信息(文本、代码、图像和视频)Rhymes AI推出新型多模态原生模型Aria,这是一个开源的混合专家(MoE)模型,ARIA专门设计来处理和理解多种类型的信息,比如文本、代码、图像和视频,而且它能够像人类一样,不需要特别区分这些...多模态模型# Aria# Rhymes AI# 多模态模型12个月前05430
JoyCaption:从零开始构建的免费、开放且未经审查的视觉语言模型JoyCaption,一个从零开始构建的免费、开放且未经审查的视觉语言模型(VLM),旨在助力社区训练SD或Flux模型。它不仅免费开放,还提供训练脚本和丰富的构建细节,就像bigASP一样。 Dem...多模态模型# JoyCaption# 视觉语言模型12个月前05330
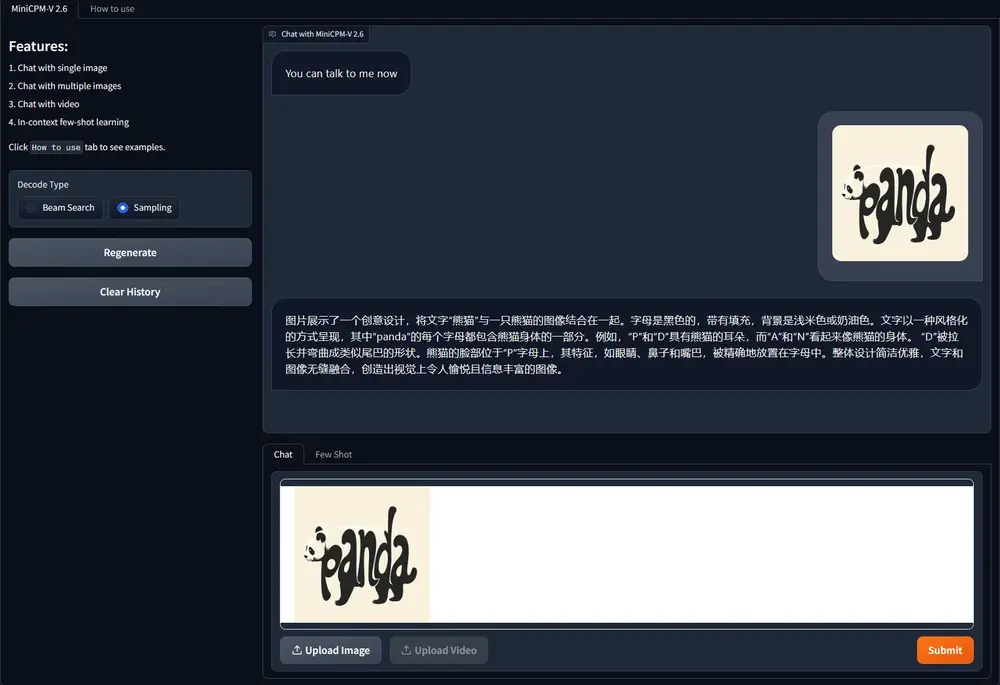
面壁智能推出开源多模态大语言模型MiniCPM-V 2.6:可以在手机上运行与GPT-4V水平相当的任务面壁智能昨日开源了 MiniCPM-V 2.6 模型,官方表示将端侧 AI 多模态能力拉升至全面对标 GPT-4V 水平。MiniCPM-V是面向图文理解的端侧多模态大模型系列。该系列模型接受图像和文...多模态模型# MiniCPM-V 2.6# 面壁智能12个月前05330
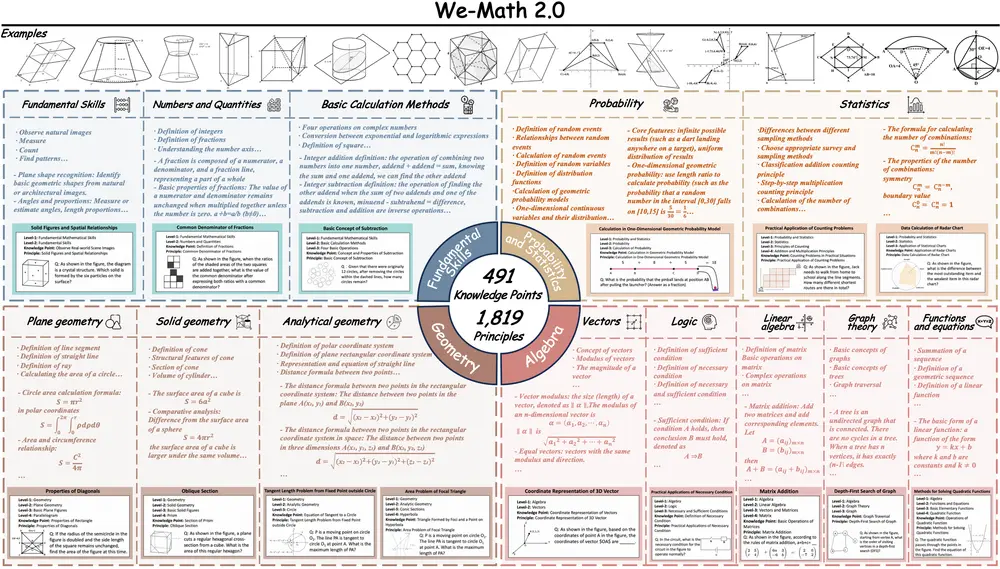
北邮、清华、腾讯联合推出 We-Math 2.0:构建有“知识体系”的数学推理智能体在当前多模态大模型(MLLM)普遍依赖数据驱动“试错式”解题的背景下,北京邮电大学、清华大学与腾讯的研究团队提出了一条不同的技术路径:让模型真正理解数学。 他们联合发布了 We-Math 2.0 ...多模态模型# We-Math 2.0# 数学推理智能体6个月前05180
深度求索推出统一图像理解和生成的创新框架JanusFlow:将图像理解和生成统一在一个模型中来自深度求索(DeepSeek-AI)、香港大学、清华大学和北京大学的研究人员提出了一种名为JanusFlow的创新框架,该框架将图像理解和生成统一在一个模型中。JanusFlow引入了一个极简的架构...多模态模型# JanusFlow# 深度求索12个月前05180
Watermark-Detection-SigLIP2:高效检测图像水印的视觉语言模型在数字内容管理中,水印检测是一项关键任务。无论是内容审核、数据集清理,还是版权保护,快速准确地识别图像中的水印都能显著提升工作效率。Watermark-Detection-SigLIP2 是一款基于谷...多模态模型# Watermark-Detection-SigLIP2# 水印检测9个月前05100
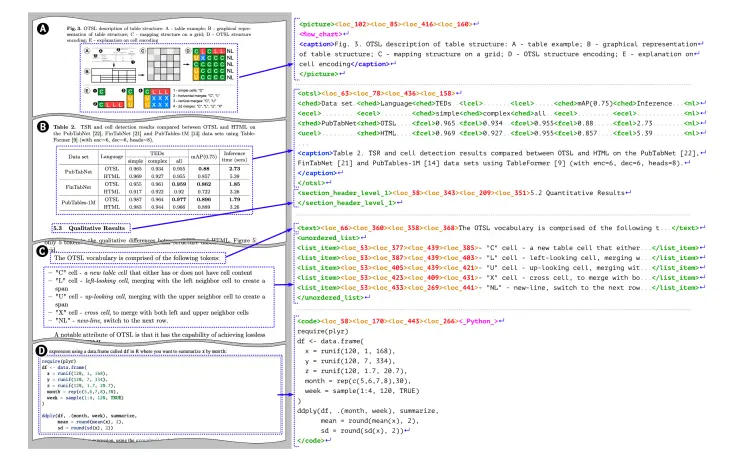
腾讯发布混元Large-Vision:支持原生分辨率输入的旗舰级多模态理解模型腾讯正式推出 混元Large-Vision —— 一款面向复杂任务的旗舰级多模态大模型。该模型在文档理解、数学推理、视频分析和三维空间感知等高难度场景中表现突出,同时具备卓越的多语言支持能力,在LMA...多模态模型# Hunyuan-Large-Vision# 混元Large-Vision# 腾讯6个月前05070
视觉语言模型SmolDocling:以高效的方式实现端到端的多模态文档转换在数字化时代,文档处理和理解是许多行业和研究领域的核心需求。从学术论文到商业报告,从技术手册到专利文件,文档的高效转换和理解对于信息提取、知识管理和自动化流程至关重要。然而,传统的文档处理方法往往依赖...多模态模型# SmolDocling# 文档转换# 视觉语言模型11个月前05060
Moondream 团队推出 Moondream 3 预览版本:轻量架构下的高性能视觉推理模型Moondream 团队正式推出 Moondream 3 的预览版本——一款基于 9B 参数稀疏混合专家(MoE)架构的新模型,实际激活参数仅为 2B。它在保持极快推理速度和低运行成本的同时,实现了接...多模态模型# Moondream 3# 视觉推理模型4个月前05000
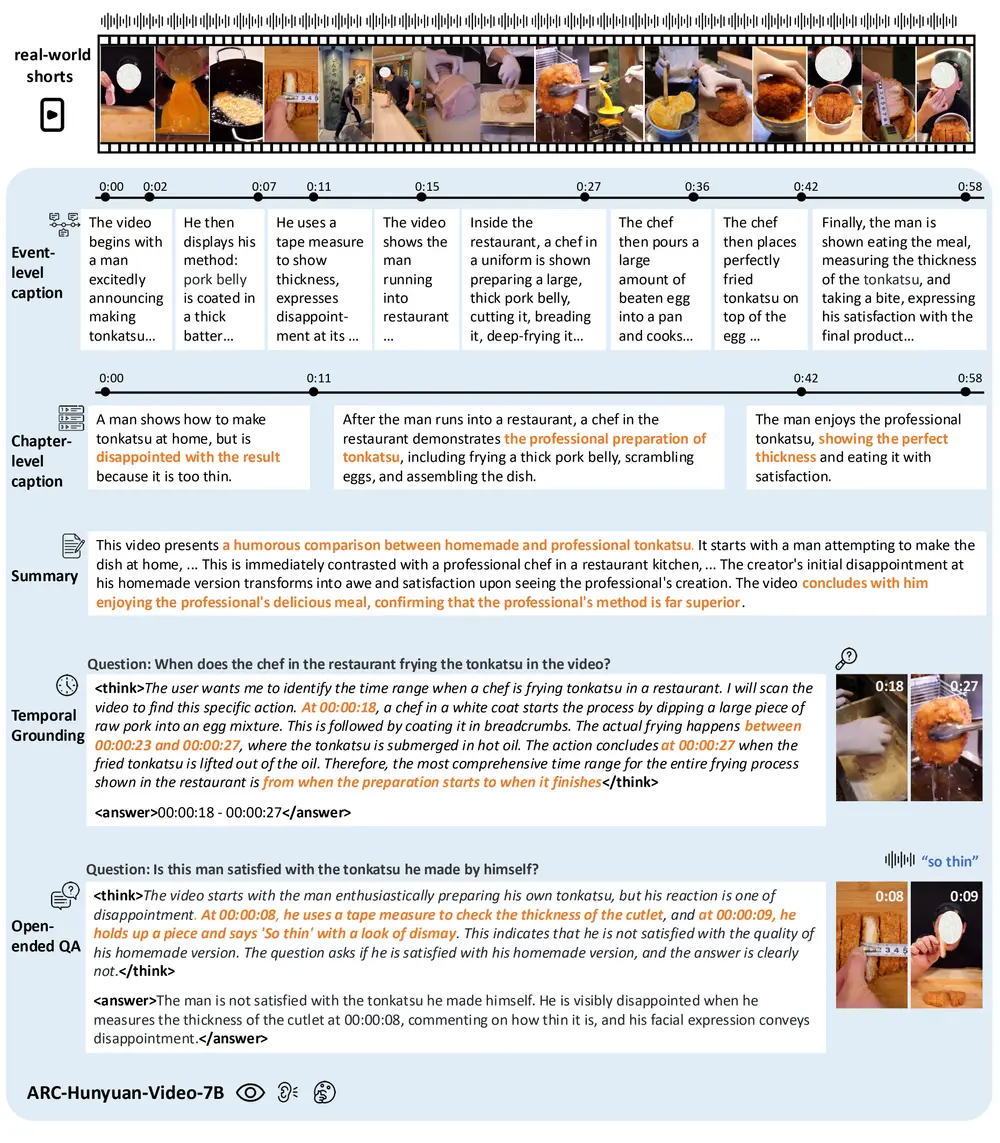
腾讯ARC实验室发布 ARC-Hunyuan-Video-7B:专为短视频理解而生的多模态模型在微信视频号、TikTok 等平台上,每天有数亿条用户生成的短视频被上传。这些视频内容多样、节奏快、信息密度高,往往融合了画面、语音、音效、文字甚至情绪表达。如何让AI真正“理解”这些视频,而不仅仅是...多模态模型# ARC-Hunyuan-Video-7B# 多模态模型# 腾讯ARC实验室6个月前04890
MiniMax推出视觉三重统一强化学习(RL)系统 V-Triune :使视觉语言模型能够在单一训练流程中联合学习视觉推理和感知任务MiniMax推出视觉三重统一强化学习(RL)系统 V-Triune ,使视觉语言模型能够在单一训练流程中联合学习视觉推理和感知任务。该系统通过整合三个互补组件——样本级数据格式化(Sample-Le...多模态模型# MiniMax# V-Triune# 视觉语言模型8个月前04790