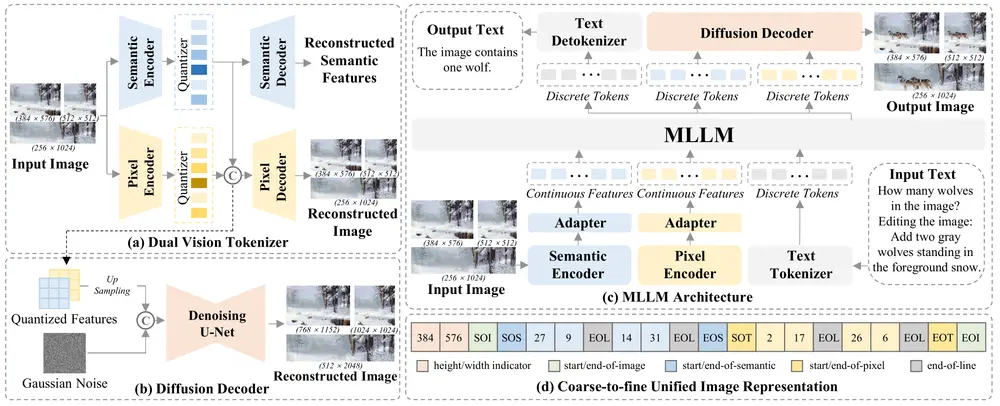
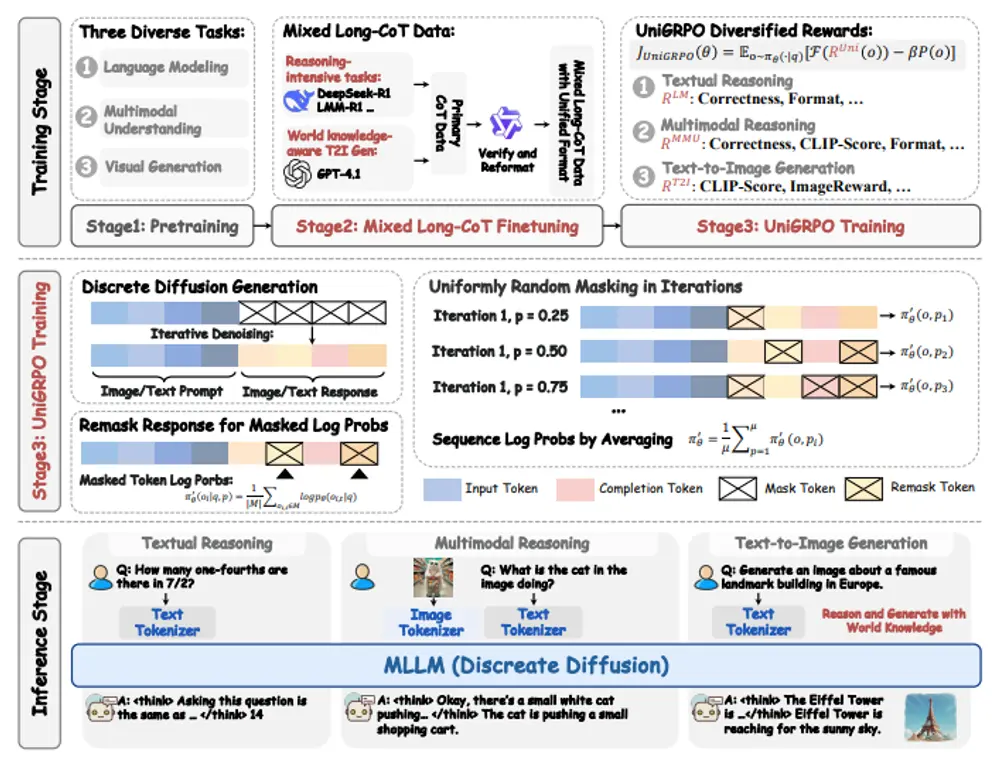
增强版多模态大语言模型ILLUME+ :通过双视觉标记化和扩散解码器来提升深度语义理解和高保真图像生成的能力近年来,多模态大语言模型(MLLMs)在图像理解、生成和编辑任务中取得了显著进展。然而,现有的统一模型在同时处理这三种任务时面临挑战。例如,早期的模型(如 Chameleon 和 EMU3)使用 VQ...多模态模型# ILLUME# 图像生成# 多模态大语言模型10个月前04740
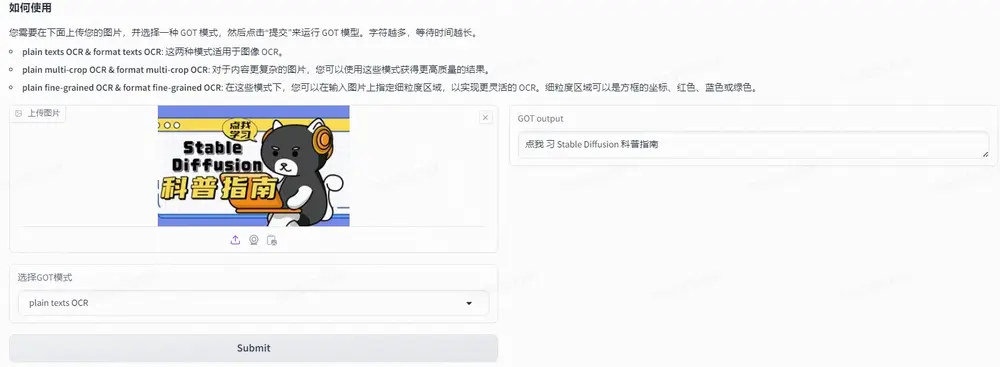
GOT-OCR-2.0模型:专为识别和处理各种字符而设计的OCR模型GOT-OCR 模型是一个参数量达 580M 的OCR系统,专为识别和处理各种字符而设计。该模型配备了高压缩编码器和长上下文解码器,能够精准处理各种场景和文档风格的图像。它支持多页和动态分辨率的 OC...多模态模型# GOT-OCR-2.0# OCR模型12个月前04590
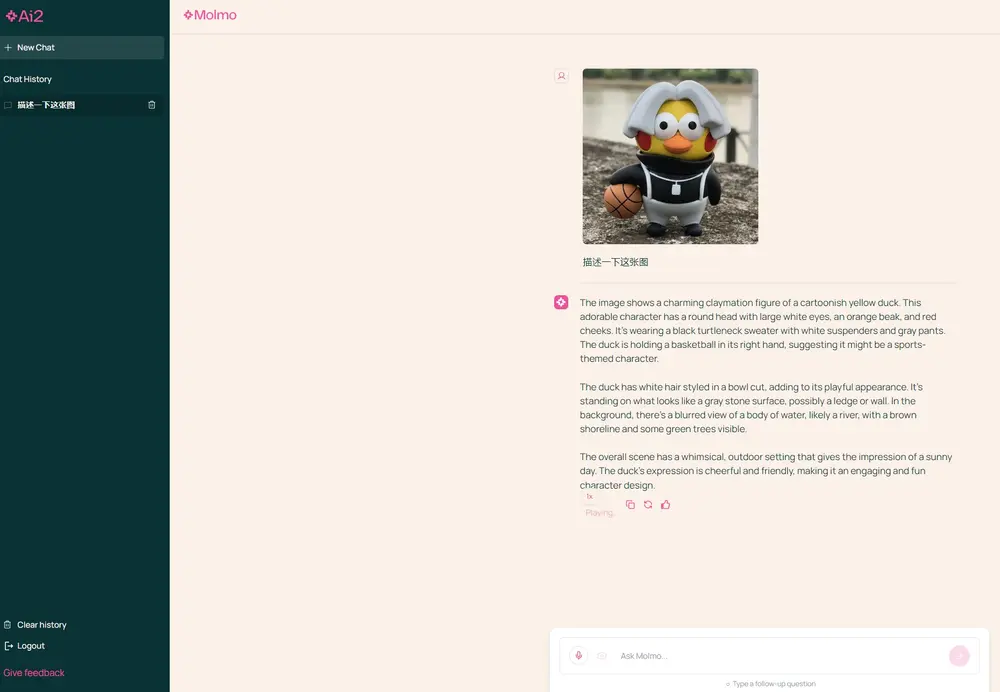
新型多模态模型家族Molmo:专门设计用于理解和处理图像和文本数据华盛顿大学和艾伦人工智能研究所的研究人员推出新型多模态模型家族Molmo,这些模型专门设计用于理解和处理图像和文本数据。Molmo的目标是提供一个最先进的、开放的多模态模型,Molmo的关键创新是一个...多模态模型# Molmo# 多模态模型12个月前04500
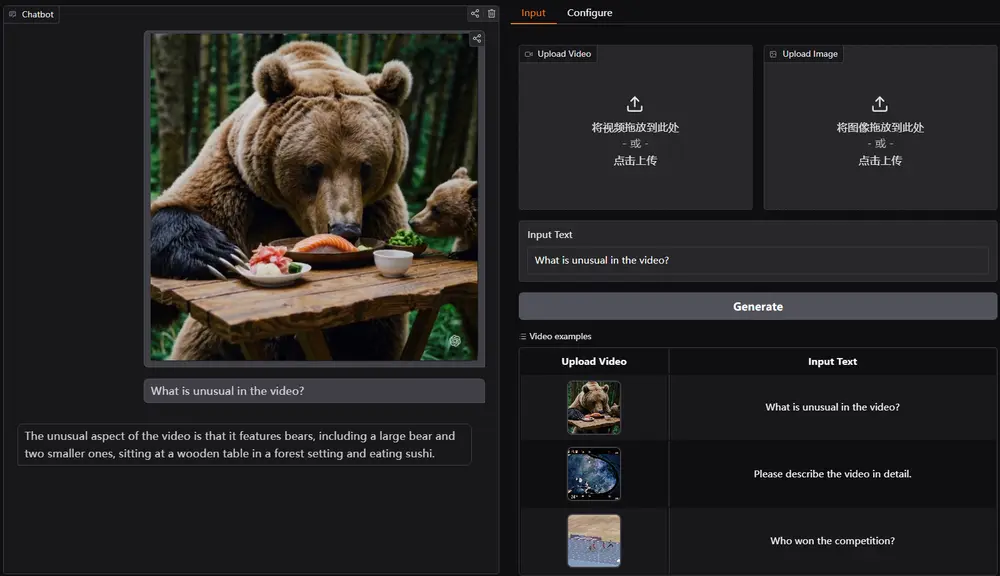
新型多模态基础模型VideoLLaMA 3:提升图像和视频理解的性能阿里巴巴达摩院的研究人员推出新型多模态基础模型VideoLLaMA 3,旨在提升图像和视频理解的性能。该模型的核心设计理念是“以视觉为中心”(vision-centric),通过高质量的图像-文本数据...多模态模型# VideoLLaMA 312个月前04450
图像编辑通用模型OMNI-EDIT:通过专家监督来构建,能够执行多种图像编辑任务指令引导的图像编辑方法通过在自动合成或手动标注的图像编辑对上训练扩散模型,展示了显著的潜力。然而,这些方法在实际应用中仍然存在明显的不足。滑铁卢大学和威斯康星大学麦迪逊分校的研究人员识别了导致这一差距...多模态模型# OMNI-EDIT# 图像编辑12个月前04430
新型开源大型多模态模型LLaVA-Critic:用于评估各种多模态任务的性能字节跳动和马里兰大学帕克分校的研究人员推出新型开源大型多模态模型LLaVA-Critic,它被设计成一个全能的评估者,用于评估各种多模态任务的性能。多模态任务通常涉及理解和生成与图像、视频和文本相关的...多模态模型# LLaVA-Critic# 多模态模型12个月前04420
天工AI推出多模态推理模型 Skywork R1V2:引入混合强化学习框架,提升模型在复杂推理和通用视觉理解任务中的表现多模态模型的快速发展为通用人工智能(AGI)的实现铺平了道路,但如何在保持跨任务泛化能力的同时提升专业推理能力,仍然是一个关键挑战。近期,天工AI(Skywork AI)推出了下一代多模态推理模型 S...多模态模型# Skywork R1V2# 多模态推理模型# 天工AI9个月前04410
视觉语言模型ClipTagger-12B:开源视频理解新标杆,性能对标 GPT-4.1,成本低至 1/15程序化视频理解正在成为构建智能视觉系统的基础设施。从内容审核到自动化标注,从辅助功能到视频搜索引擎,开发者需要一种高效、可靠的方式,将原始视频帧转化为结构化、可搜索、可操作的数据。 为此,Infere...多模态模型# ClipTagger-12B# 视觉语言模型6个月前04370
新型多模态扩散基础模型MMaDA:通过统一的扩散架构和训练策略,在多种领域(如文本推理、多模态理解和文本到图像生成)中实现卓越性能普林斯顿大学、北京大学、清华大学和字节跳动的研究人员推出新型多模态扩散基础模型MMaDA系列,该模型通过统一的扩散架构和训练策略,在多种领域(如文本推理、多模态理解和文本到图像生成)中实现卓越性能。 ...多模态模型# MMaDA# 多模态扩散基础模型8个月前04250
智源研究院推出全新多模态系列模型Emu3智源研究院推出Emu3,这是一个全新的多模态系列模型,它仅使用下一个词元(Token)预测这一建模范式进行训练,达到了最先进的水平。Emu3 通过一个 Transformer 模型在视频、图像和文本令...多模态模型# Emu3# 多模态模型# 智源研究院12个月前04210
字节跳动推出专注于提升多模态理解与推理能力的视觉-语言基础模型Seed1.5-VL字节跳动正式推出 Seed1.5-VL,这是一款专注于提升多模态理解与推理能力的视觉-语言基础模型。Seed1.5-VL 不仅在视觉和视频理解任务中表现出色,还在智能体相关任务及复杂推理挑战中展现了卓...多模态模型# Seed1.5-VL# 字节跳动# 视觉-语言基础模型9个月前04160
Meta发布 Llama 3.2 模型:从 轻量级纯文本模型(1B 和 3B)到 中小型多模态模型(11B 和 90B)Meta于9月25日正式推出了Llama 3.2模型,这款新模型以其开放性和可定制性为特点,旨在满足开发者在边缘人工智能和视觉处理领域的多样化需求。Llama 3.2 结合了多模态视觉能力和轻量化设计...多模态模型# Llama 3.2# Meta12个月前04160