腾讯推出AnimeGamer:通过多模态大语言模型实现无限动漫生活模拟近年来,图像和视频合成技术的发展为生成游戏带来了新的可能性。特别是将动漫电影中的角色转化为可互动、可玩的实体,让玩家能够以自己喜爱的角色身份沉浸在动态的动漫世界中,通过语言指令进行生活模拟。这种游戏被...多模态模型# AnimeGamer# 多模态大语言模型# 无限动漫生活模拟10个月前04020
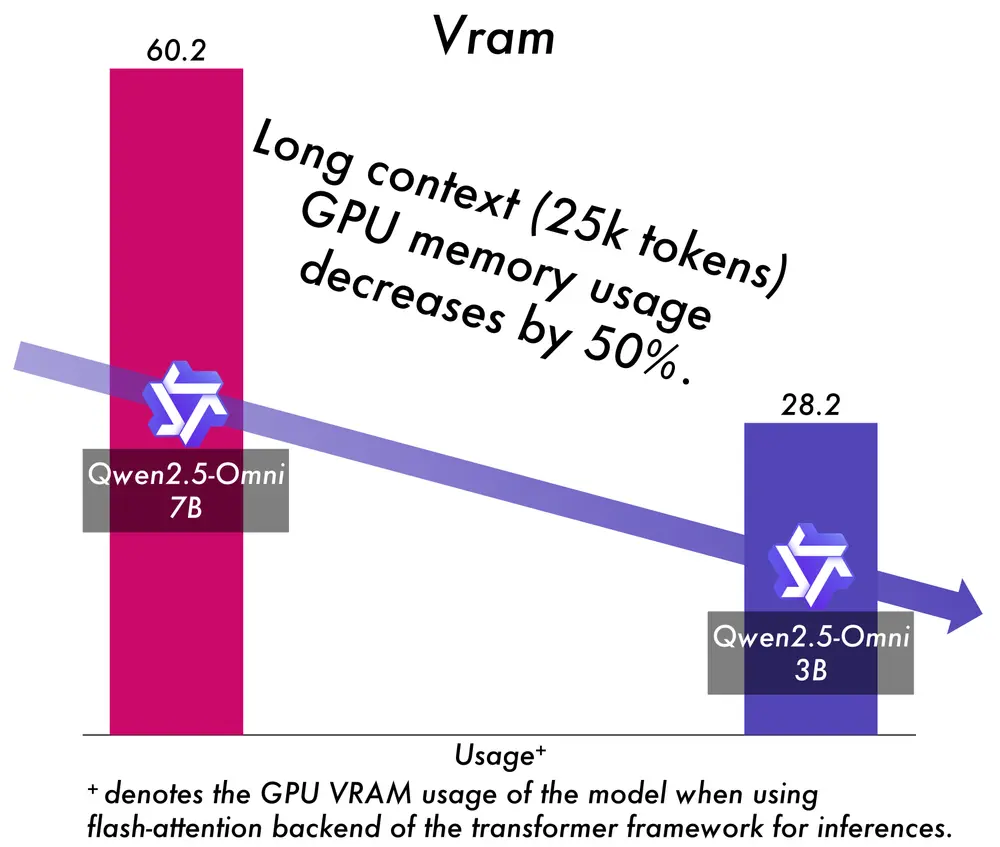
阿里Qwen团队发布端到端多模态模型Qwen2.5-Omni-3B阿里Qwen团队在发布Qwen3系列模型后,又推出Qwen2.5-Omni系列的一个新模型Qwen2.5-Omni-3B,这是一个端到端多模态模型,能够无缝处理文本、图像、音频和视频等多种输入形式,并...多模态模型# Qwen# Qwen2.5-Omni-3B# 阿里巴巴9个月前03990
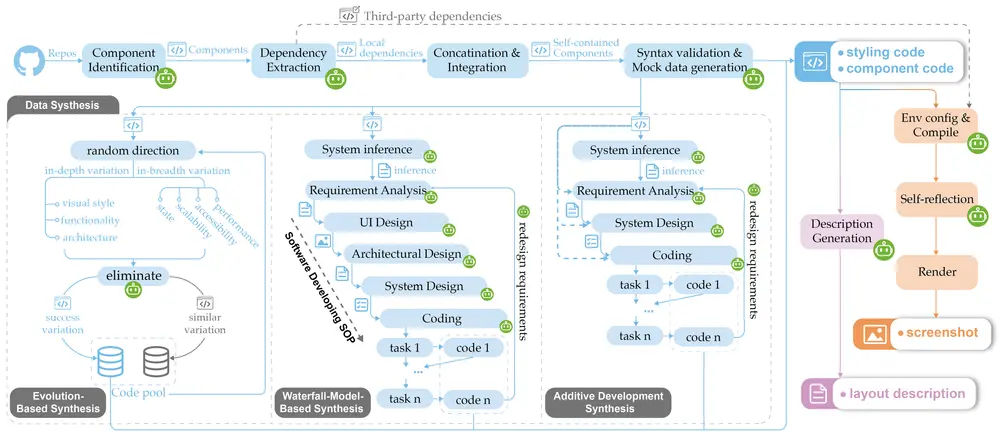
首个截图就能生成现代前端代码的多模态模型Flame尽管前沿的多模态模型(如 GPT-4O)在代码生成上展现了强大的能力,但它们在真实的前端开发场景中仍无法满足现代前端工作流程的动态需求。这些模型虽然能够生成代码,但输出的前端代码通常是静态的,缺乏模块...多模态模型# Flame# 前端代码# 多模态模型11个月前03950
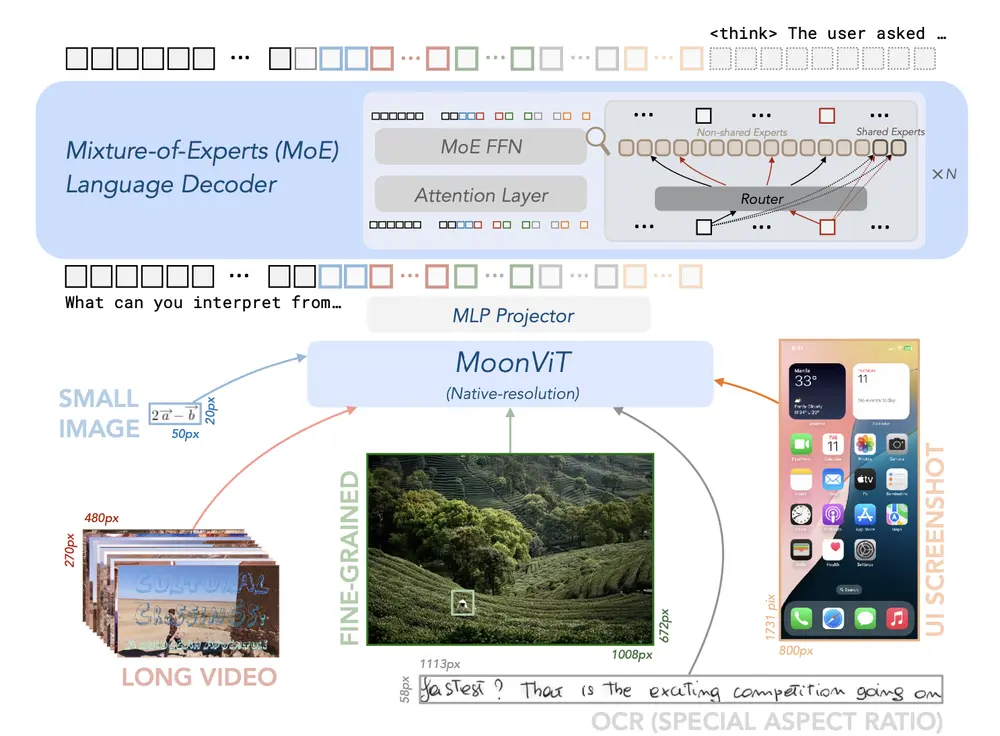
月之暗面推出高效开源视觉-语言模型Kimi-VL随着AI技术的快速发展,视觉-语言模型(VLM)在多模态任务中的应用越来越广泛。然而,如何在保持高性能的同时降低计算成本,一直是研究者面临的挑战。近日,国内知名AI公司“月之暗面”推出了 一款高效的开...多模态模型# Kimi-VL# 月之暗面10个月前03830
字节跳动推出多模态文档图像解析模型Dolphin在复杂文档图像理解和结构化提取任务中,如何准确识别并组织交织的文本段落、公式、表格和图像,一直是业界的技术难点。 GitHub:https://github.com/bytedance/Dolphin...多模态模型# Dolphin# 多模态模型# 字节跳动7个月前03770
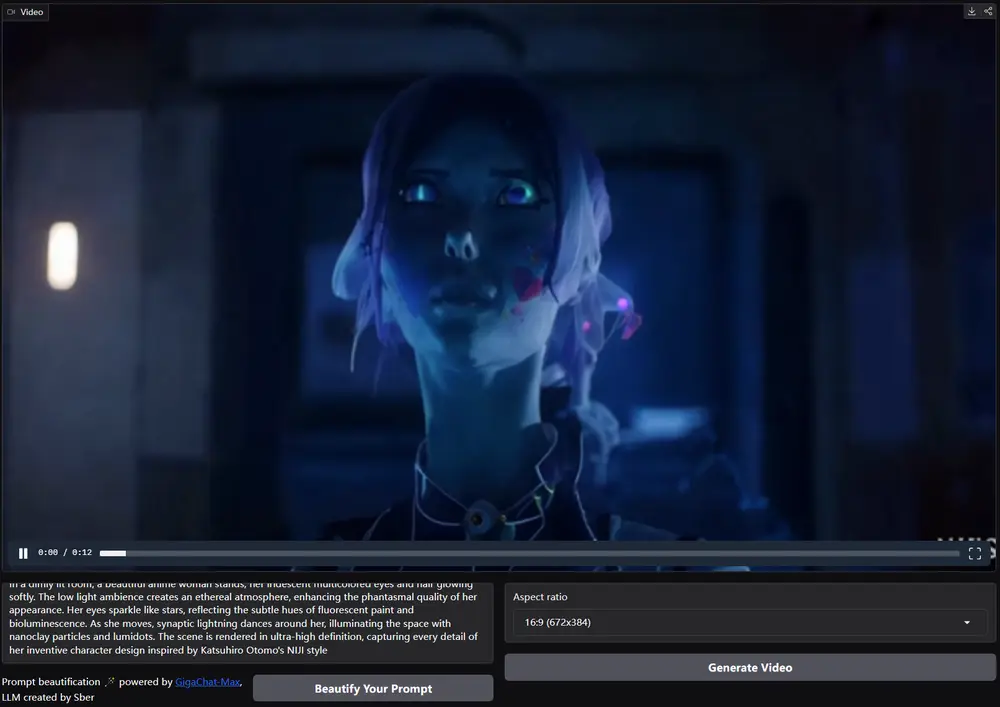
Sber AI 推出新一代多模态生成模型Kandinsky 4.0:包含3个视频生成模型(T2V、T2V Flash、I2V)和一个视频生成音频模型(V2A)去年,在 AI Journey 2023 大会上,Sber AI 推出了两款引人注目的模型:用于图像生成的 Kandinsky 3.0 和俄罗斯首个文本到视频生成模型 Kandinsky Video...多模态模型# Kandinsky 4.012个月前03650
统一视觉自回归模型 VARGPT-v1.1:统一视觉理解和图像生成任务北京大学和香港中文大学的研究人员推出先进统一视觉自回归模型 VARGPT-v1.1 ,该模型在多模态理解和文本到图像生成任务中表现出色。它通过迭代指令微调和强化学习等创新训练策略,显著提升了模型的性能...多模态模型# VARGPT-v1.1# 统一视觉自回归模型10个月前03590
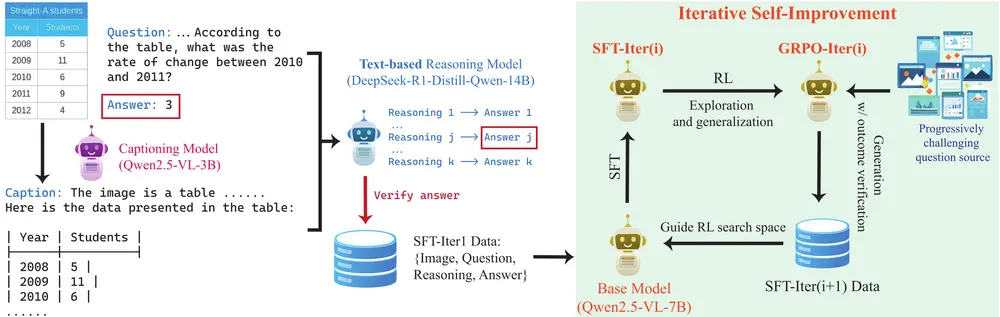
OpenVLThinker:通过迭代自我改进的方法,将复杂的推理能力(如自我验证和自我修正)整合到大型视觉语言模型中加州大学洛杉矶分校的研究人员推出OpenVLThinker,通过迭代自我改进的方法,将复杂的推理能力(如自我验证和自我修正)整合到大型视觉语言模型(LVLMs)中,并评估其在多模态推理任务中的表现。 ...多模态模型# OpenVLThinker# 多模态推理模型10个月前03590
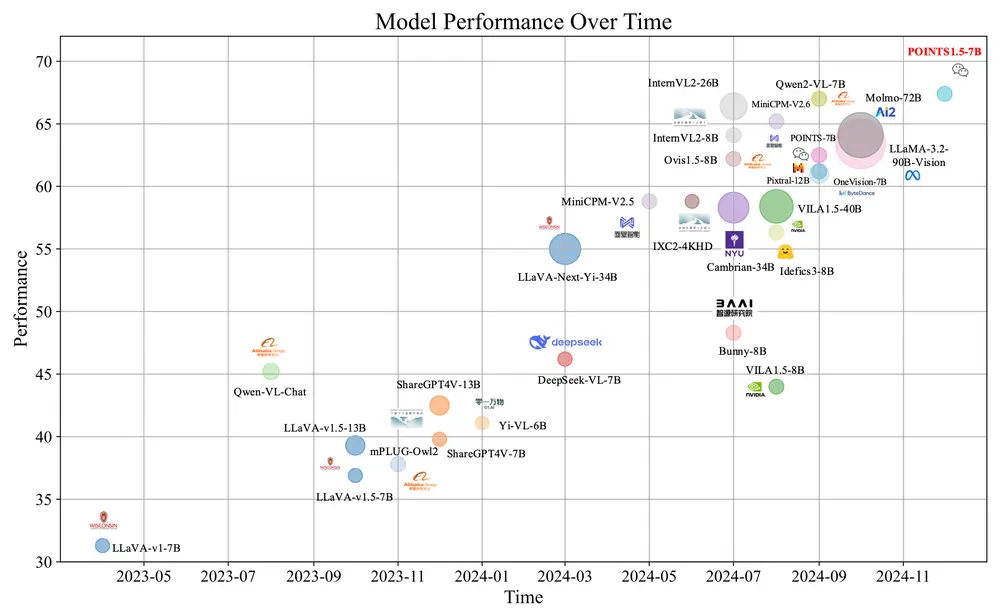
微信 AI 模式识别中心推出视觉语言模型POINTS1.5系列:提升对真实世界应用的处理能力微信 AI 模式识别中心推出视觉语言模型POINTS1.5系列,旨在提升对真实世界应用的处理能力。POINTS1.5是POINTS1.0的增强版本,它通过引入几项关键创新,改进了模型在处理高分辨率图像...多模态模型# POINTS1.5# 视觉语言模型12个月前03570
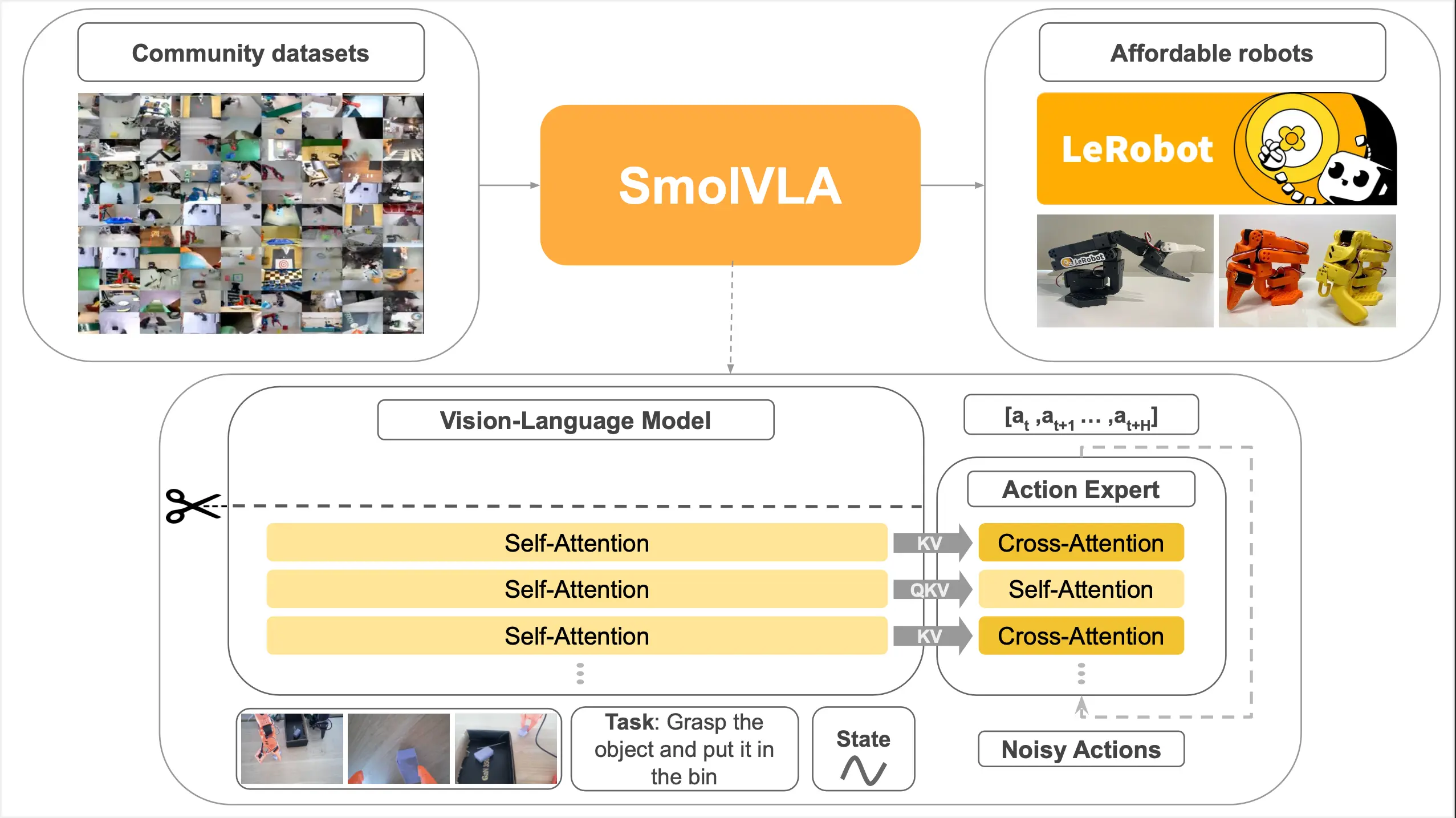
Hugging Face 推出轻量级机器人AI模型SmolVLA:可在MacBook运行随着AI与机器人技术的融合不断深入,构建个人机器人项目正变得前所未有的容易。近日,知名AI平台 Hugging Face 正式发布了其最新研发的机器人AI模型——SmolVLA,这一模型不仅小巧高效...多模态模型# Hugging Face# SmolVLA8个月前03550
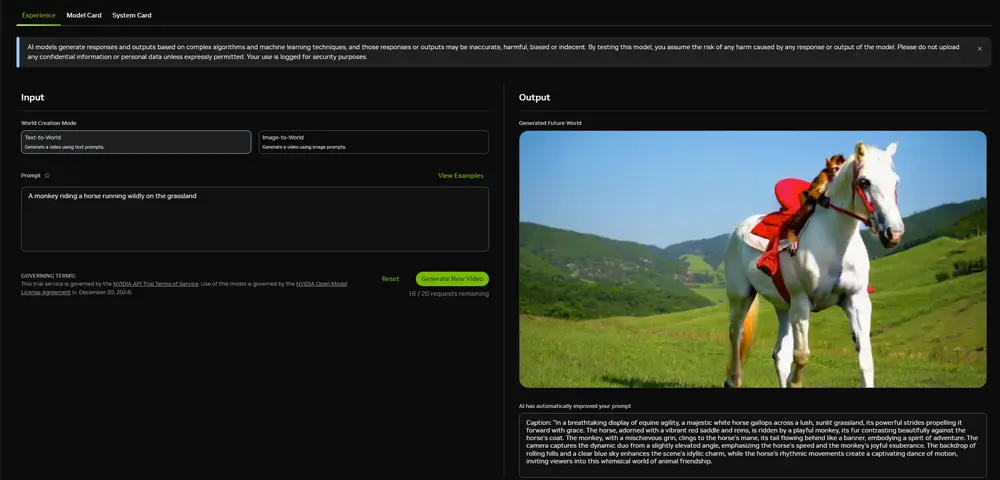
英伟达推出世界基础模型平台NVIDIA Cosmos :帮助物理 AI 开发人员更好、更快地构建物理 AI 系统英伟达在CES2025上宣布推出 NVIDIA Cosmos 平台,该平台包含先进的世界基础生成模型、高级分词器、防护栏和加速视频处理管道,旨在推动自动驾驶汽车(AV)和机器人等物理 AI 系统的发展...多模态模型# NVIDIA Cosmos# 世界模型# 英伟达12个月前03550
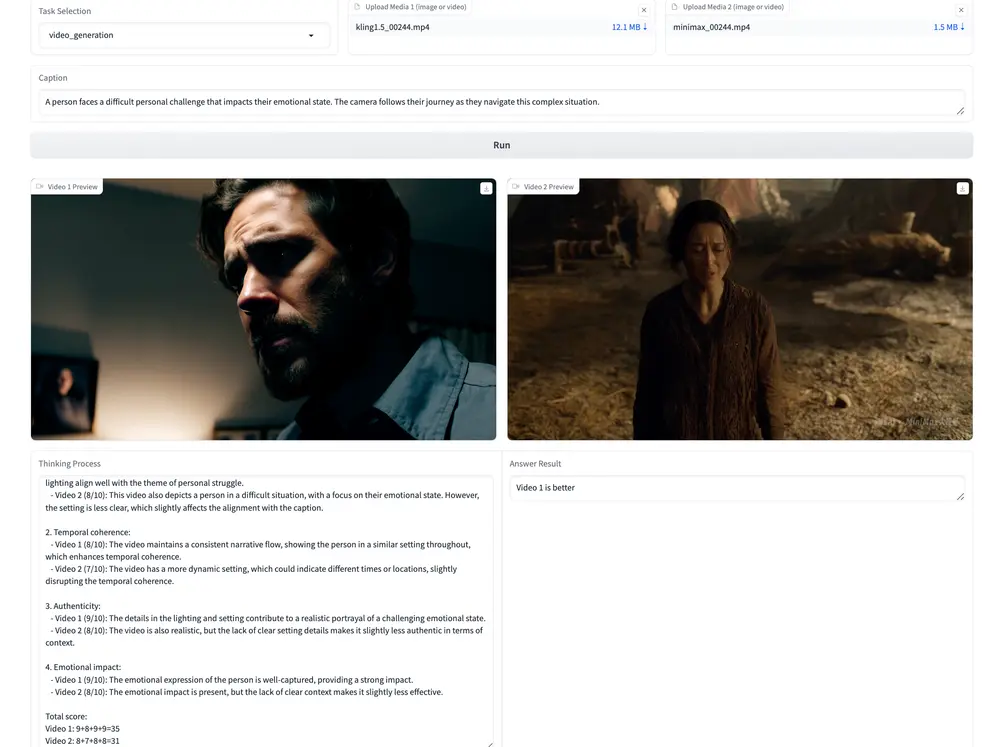
复旦联合团队发布首个统一多模态奖励模型UNIFIEDREWARD:图像视频都能评,还能优化视觉生成近日,由复旦大学、上海创新创意设计研究院、上海人工智能实验室和上海人工智能科学院组成的研究团队,正式发布了全球首个支持图像与视频理解与生成任务评估的统一奖励模型 —— UNIFIEDREWARD。 项...多模态模型# UNIFIEDREWARD# 统一多模态奖励模型7个月前03540