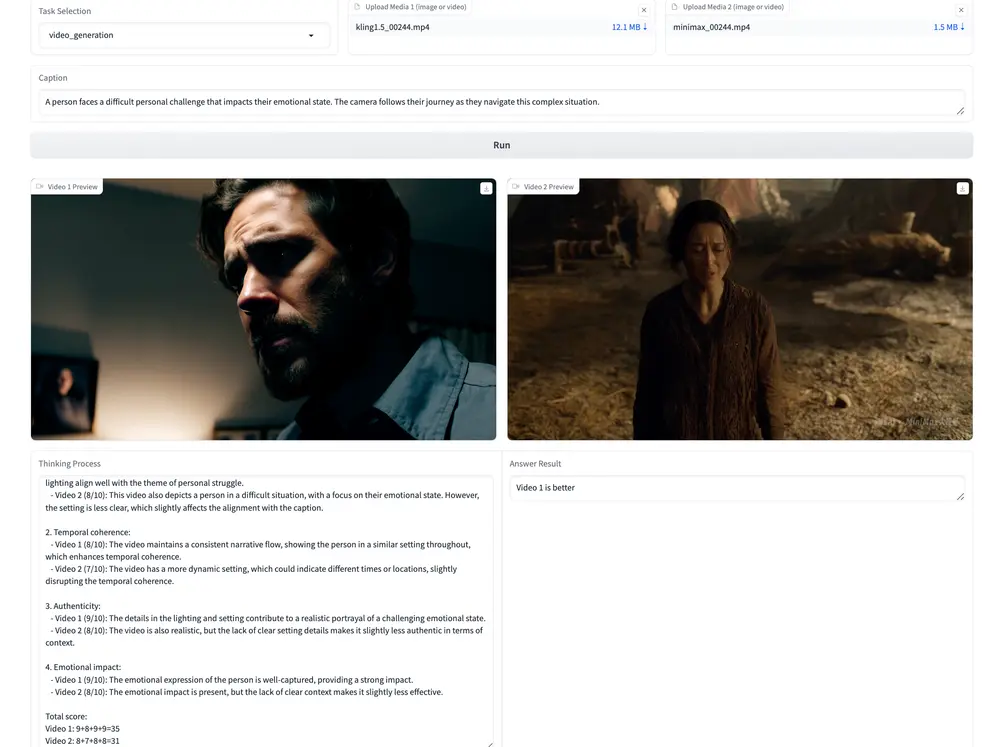
复旦联合团队发布首个统一多模态奖励模型UNIFIEDREWARD:图像视频都能评,还能优化视觉生成近日,由复旦大学、上海创新创意设计研究院、上海人工智能实验室和上海人工智能科学院组成的研究团队,正式发布了全球首个支持图像与视频理解与生成任务评估的统一奖励模型 —— UNIFIEDREWARD。 项...多模态模型# UNIFIEDREWARD# 统一多模态奖励模型7个月前03540
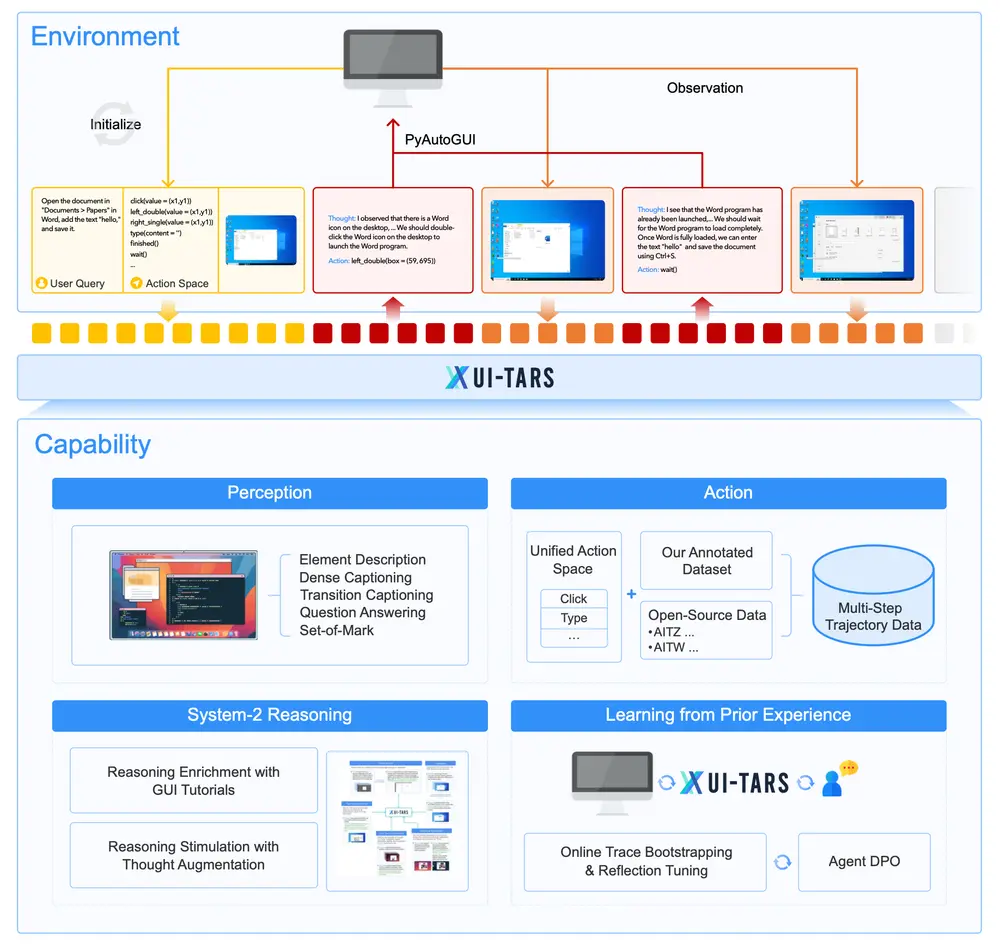
新型自动化 GUI交互模型 UI-TARS:能够通过感知屏幕截图作为输入,并执行类似人类操作的交互任务(如键盘输入和鼠标操作)字节跳动与清华大学的研究人员推出新型自动化 GUI(图形用户界面)交互模型 UI-TARS,它是一种原生的 GUI 代理模型,能够通过感知屏幕截图作为输入,并执行类似人类操作的交互任务(如键盘输入和鼠...多模态模型# UI-TARS# 字节跳动10个月前03510
阿里通义实验室发布 Qwen3-VL:迄今最强视觉语言模型,全面开源阿里通义实验室 Qwen 项目组正式推出全新升级的 Qwen3-VL 系列——这是截至目前 Qwen 多模态体系中能力最全面、性能最先进的视觉语言模型(Vision-Language Model, V...多模态模型# Qwen3-VL# 视觉语言模型4个月前03480
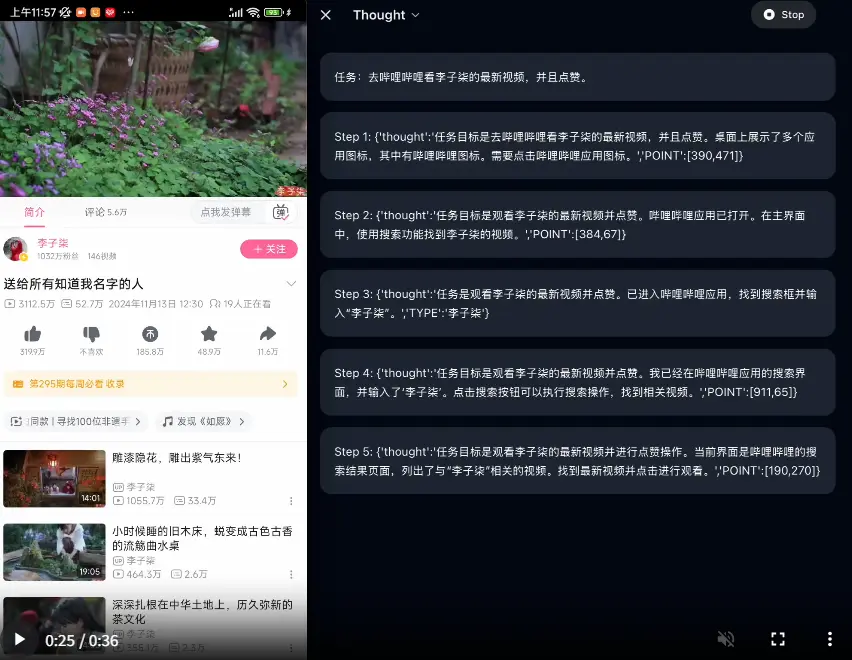
基于MiniCPM-V构建的开源端侧智能体大模型AgentCPM-GUI:,接受手机屏幕图像作为输入,自动执行用户提出的任务AgentCPM-GUI是由清华大学THUNLP实验室与面壁智能团队联合开发的开源端侧智能体大模型,基于MiniCPM-V构建,总参数量8B,接受手机屏幕图像作为输入,自动执行用户提出的任务。 Git...多模态模型# AgentCPM-GUI# MiniCPM-V# 智能体大模型9个月前03440
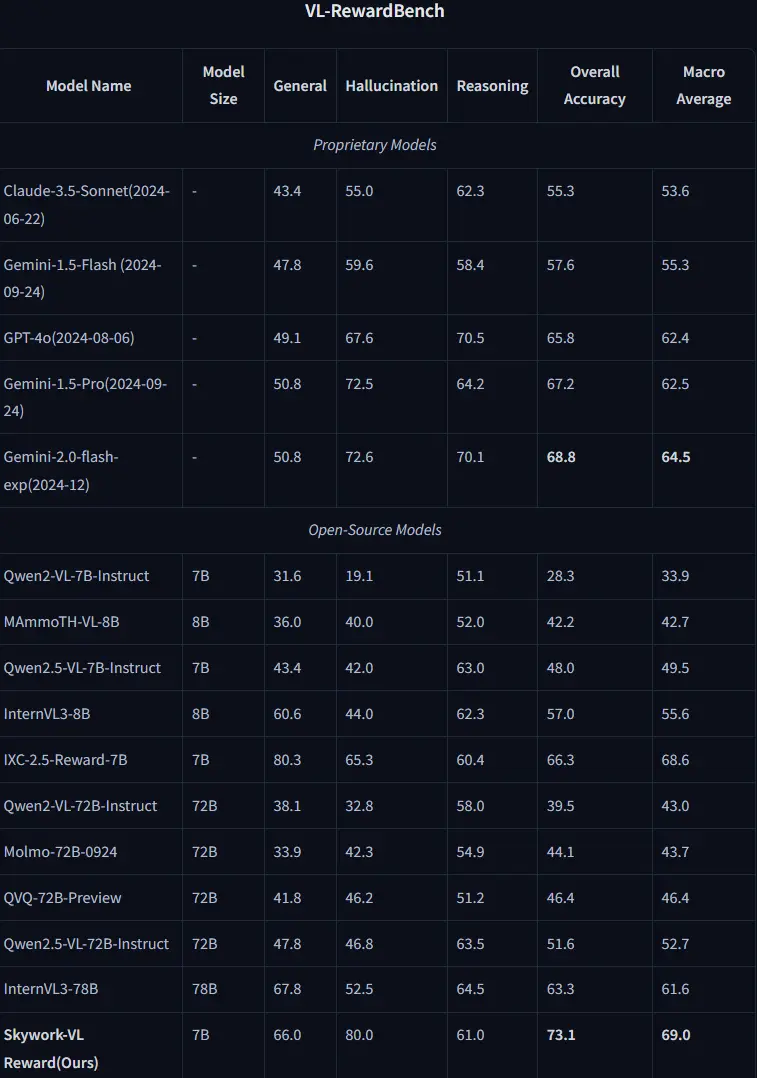
天工AI推出用于多模态理解和推理任务的多模态奖励模型Skywork-VL Reward天工AI(Skywork AI)推出一个用于多模态理解和推理任务的多模态奖励模型Skywork-VL Reward,此模型是基于Qwen2.5-VL-7B-Instruct训练,Skywork-VL ...多模态模型# Skywork-VL Reward# 多模态奖励模型# 天工AI9个月前03390
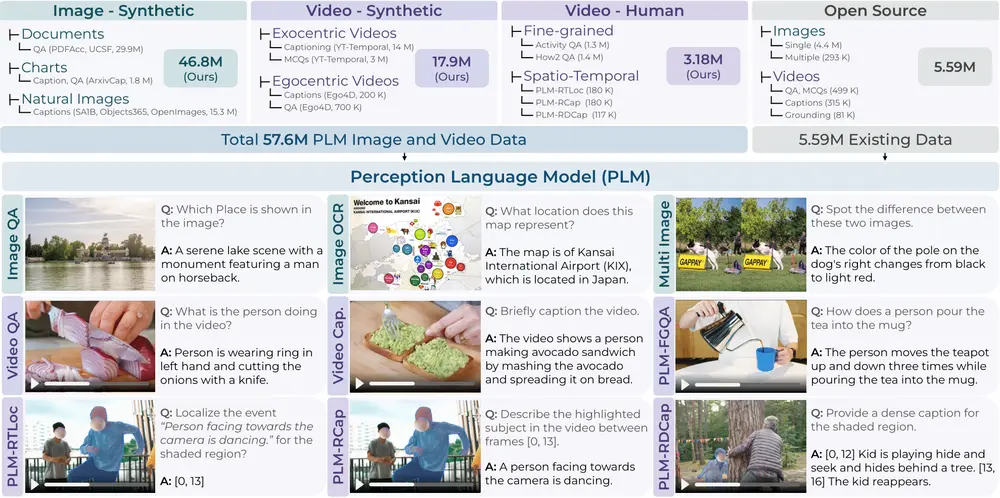
Meta AI推出一款通过单一对比学习目标训练的通用视觉编码器Perception Encoder随着AI系统逐渐向多模态方向发展,视觉感知模型的角色也变得更加复杂。传统的视觉编码器通常针对特定任务进行优化,例如图像分类、目标检测或语言生成,但这种碎片化的方法不仅增加了模型的复杂性,还限制了其在开...多模态模型# Meta AI# Perception Encoder# 感知编码器9个月前03350
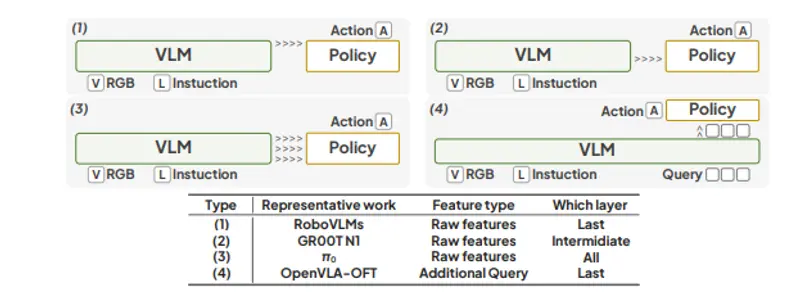
北邮、浙大等团队联合提出视觉-语言-动作模型 VLA-Adapter:用轻量桥接实现高效机器人控制在当前机器人智能领域,视觉-语言-动作(Vision-Language-Action, VLA)模型正成为连接感知与行为的核心技术。这类模型能让机器人“听懂指令”、“看懂场景”,并自主执行任务,例如...多模态模型# VLA-Adapter# 视觉-语言-动作模型5个月前03340
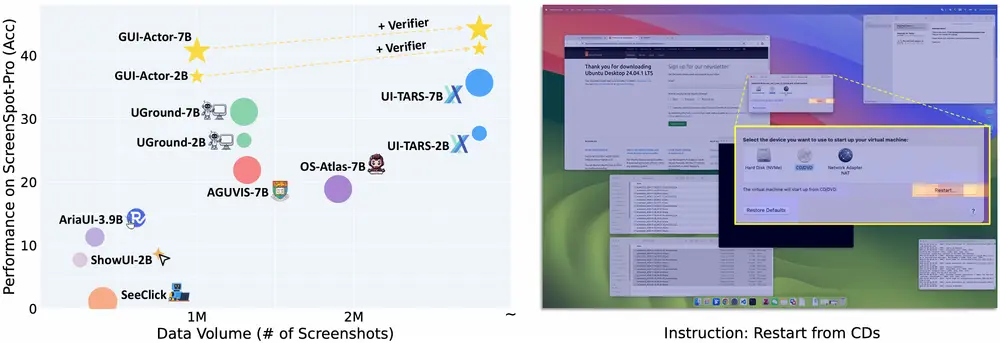
微软提出 GUI-Actor:基于视觉语言模型的无坐标 GUI 定位新范式在构建基于视觉语言模型(VLM)的 GUI 代理系统中,一个关键挑战是如何准确理解屏幕上的视觉内容并定位应执行操作的区域。传统方法通常将此问题建模为“文本到坐标的生成”任务,即通过语言描述预测具体像素...多模态模型# GUI-Actor# 微软8个月前03330
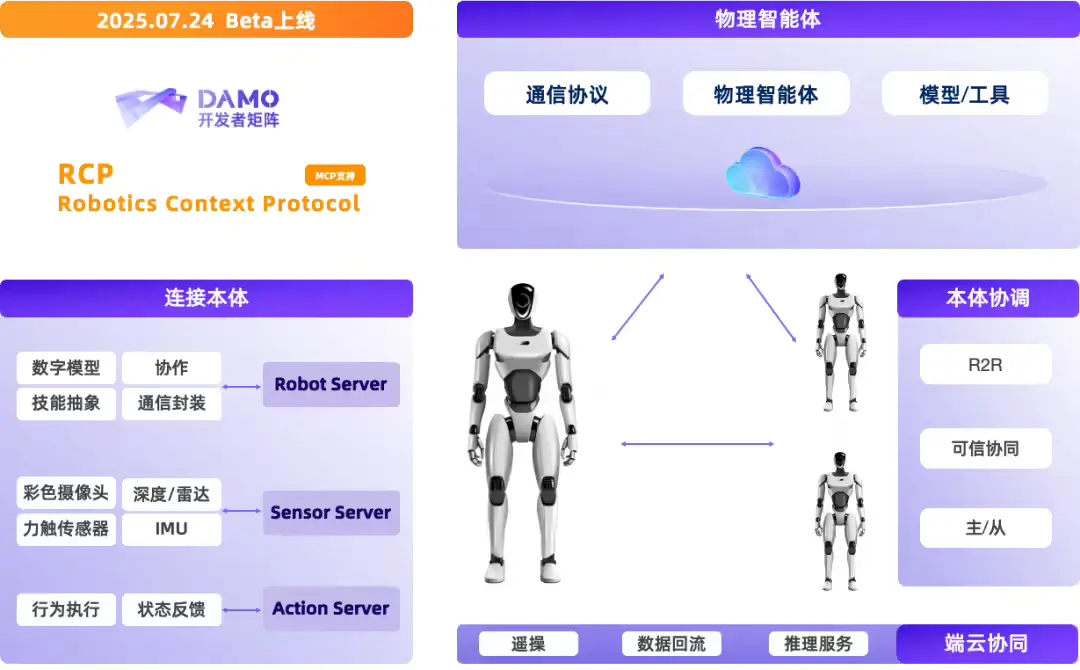
阿里达摩院开源 Rynn 系列:从协议到模型,打通具身智能“最后一公里”在上周开幕的 2025 世界机器人大会上,阿里达摩院宣布开源一套完整的具身智能技术体系,包括: 视觉-语言-动作模型 RynnVLA-001-7B 世界理解模型 RynnEC 机器人上下文协议 Ryn...多模态模型# RynnEC# RynnRCP# RynnVLA-001-7B6个月前03320
开源视觉语言模型Moondream:将强大的图像理解能力与极小的资源占用完美结合Moondream 是一款高效的开源视觉语言模型(VLM),它将强大的图像理解能力与极小的资源占用完美结合。这款模型设计初衷是为各种设备和平台提供多功能且易于访问的人工智能解决方案。 官网:https...多模态模型# Moondream# 视觉语言模型12个月前03310
LFM2-VL:轻量高效、面向设备端的视觉-语言模型在多模态大模型不断追求更高参数量和更强性能的当下,效率与部署可行性正成为实际应用的关键瓶颈。许多视觉-语言模型(VLM)虽在基准测试中表现优异,但其高计算成本和长推理延迟,使其难以在手机、可穿戴设备或...多模态模型# LFM2-VL# 视觉-语言模型6个月前03230
壁智能推出MiniCPM-o 2.6:手机上的 GPT-4o 级多模态大模型,可实时语音通话和视频通话MiniCPM-o 2.6 是面壁智能推出的 MiniCPM-o 系列中最新且功能最强大的模型。该模型基于 SigLip-400M、Whisper-medium-300M、ChatTTS-200M 和...多模态模型# MiniCPM-o 2.6# 壁智能# 视频通话12个月前03210