阿里通义团队为大家送上圣诞节大礼,开源全球首个视觉推理模型 QVQ-72B-Preview阿里通义团队为大家送上圣诞节大礼,开源了第一个视觉推理模型QVQ,其中V代表视觉。它只需读取一张图像和一个指令,开始思考,适时反思,持续推理,最终自信地生成预测!然而,它仍处于实验阶段,这个预览版本仍...多模态模型# QVQ-72B-Preview# 视觉推理模型# 阿里通义12个月前03210
基于 Qwen2-VL-7B 开发的实时视频理解大模型LiveCC:快速分析视频内容,并同步生成自然流畅的语音或文字解说新加坡国立大学和字节跳动的研究人员推出基于 Qwen2-VL-7B 开发的实时视频理解大模型LiveCC,能够像专业解说员一样快速分析视频内容,并同步生成自然流畅的语音或文字解说。特别适合需要即时反馈...多模态模型# LiveCC# Qwen2-VL-7B# 视频理解大模型9个月前03200
小红书 hi lab 开源首个视觉-语言模型:dots.vlm1小红书 hi lab 团队正式发布 dots.vlm1 ——这是“dots”模型家族中的首款视觉-语言模型(VLM),标志着其在多模态理解方向上的重要突破。 GitHub:https://github...多模态模型# dots.vlm1# 小红书6个月前03110
微软推出全新多模态大语言模型家族Florence-VL马里兰大学和微软研究院的研究团队共同提出了Florence-VL,这是一个全新的多模态大语言模型(MLLMs)家族。Florence-VL的视觉表示由生成式视觉基础模型Florence-2生成,与传统...多模态模型# Florence-VL# 多模态大语言模型# 微软12个月前03110
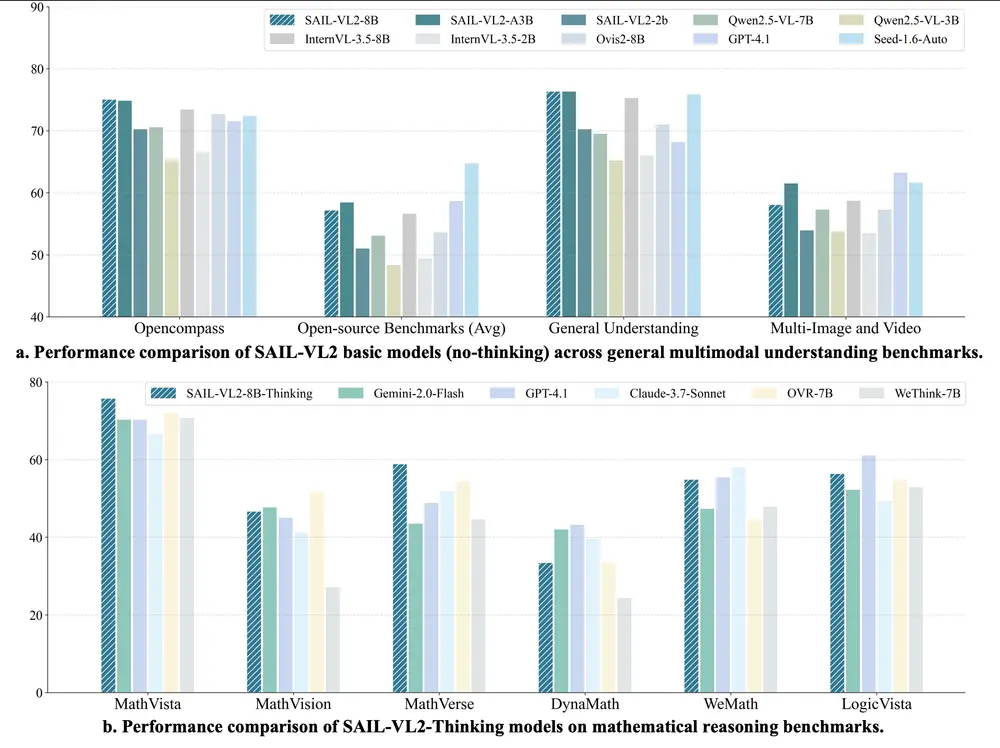
抖音推出SAIL-VL2:面向细粒度感知与复杂推理的新一代开源视觉语言模型由抖音 SAIL 团队与新加坡国立大学 LV-NUS 实验室联合研发,SAIL-VL2 是一款全新的开源视觉语言基础模型(Vision-Language Model, LVM),在 2B 和 8B 参...多模态模型# SAIL-VL2# 抖音# 视觉语言模型4个月前03100
蚂蚁集团发布Ming-lite-omni v1.5:全模态能力的全面升级由 蚂蚁集团旗下的 百灵大模型(Ling)团队研发的全模态大模型 Ming-lite-omni v1.5 正式发布。作为对初代模型的全面升级,v1.5 版本在图像、文本、视频、语音等多种模态的理解与生...多模态模型# Ming-lite-omni v1.5# 蚂蚁集团6个月前03060
谷歌推出开源视觉语言模型PaliGemma2:增加了强大的视觉能力,更容易微调今年5月,谷歌推出了 PaliGemma,这是 Gemma 家族中的第一个视觉语言模型,旨在使一流的视觉AI更加普及。现在,谷歌自豪地推出 PaliGemma 2,这是一个可调视觉语言模型的最新进化版...多模态模型# PaliGemma2# 视觉语言模型# 谷歌12个月前03060
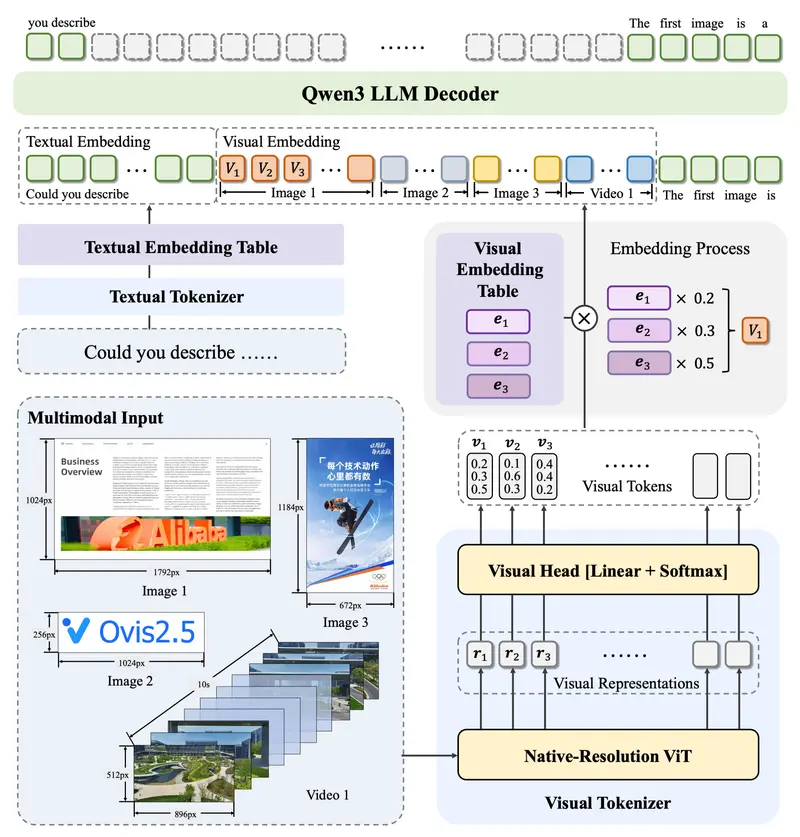
阿里国际发布多模态大语言模型Ovis2.5:原生分辨率视觉感知与深度推理的双重突破阿里国际正式推出 Ovis2.5 —— Ovis2 的继任者,一款在原生分辨率视觉理解和多模态推理能力上实现显著跃升的开源多模态大语言模型(MLLM)。 GitHub:https://github.c...多模态模型# Ovis2.5# 多模态大语言模型# 阿里国际6个月前03050
蚂蚁集团开源全新统一多模态大模型 Ming-Lite-Omni:支持图像、文本、音频、视频近日,蚂蚁集团旗下的 百灵大模型(Ling)团队 正式宣布开源其最新推出的统一多模态大模型 —— Ming-Lite-Omni。这是一款基于 Ling 系列轻量模型构建的 MoE 架构全模态 AI 模...多模态模型# Ming-Lite-Omni# 多模态大模型# 蚂蚁集团8个月前03040
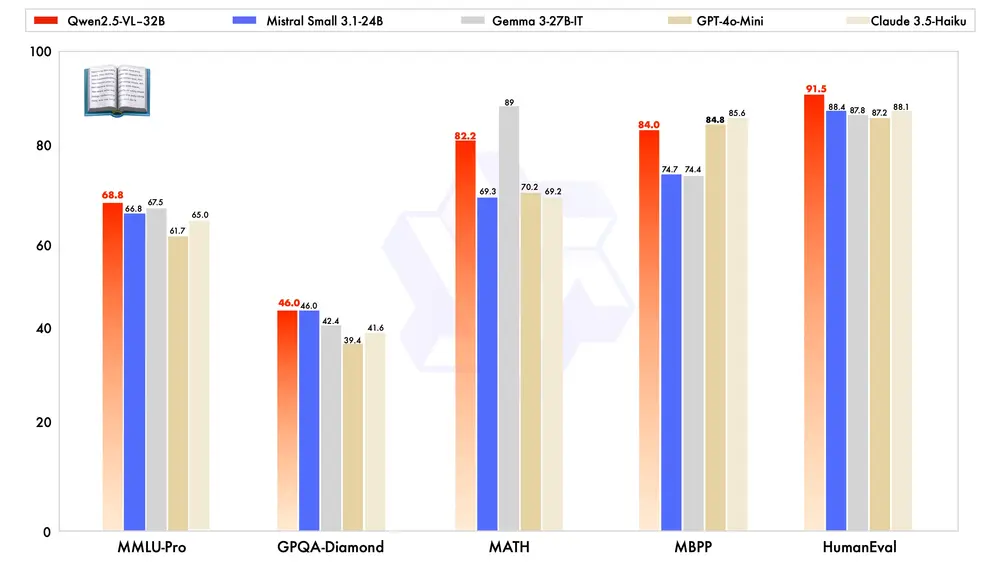
阿里通义实验室开源32B参数的多模态模型 Qwen2.5-VL-32B-Instruct今年一月底,阿里通义实验室推出了 Qwen2.5-VL 系列模型,凭借其卓越的性能和广泛的应用潜力,迅速获得了社区的广泛关注和积极反馈。在此基础上,团队通过强化学习持续优化模型,并于近期开源了备受期待...多模态模型# Qwen2.5-VL-32B-Instruct# 多模态模型# 阿里通义实验室10个月前03040
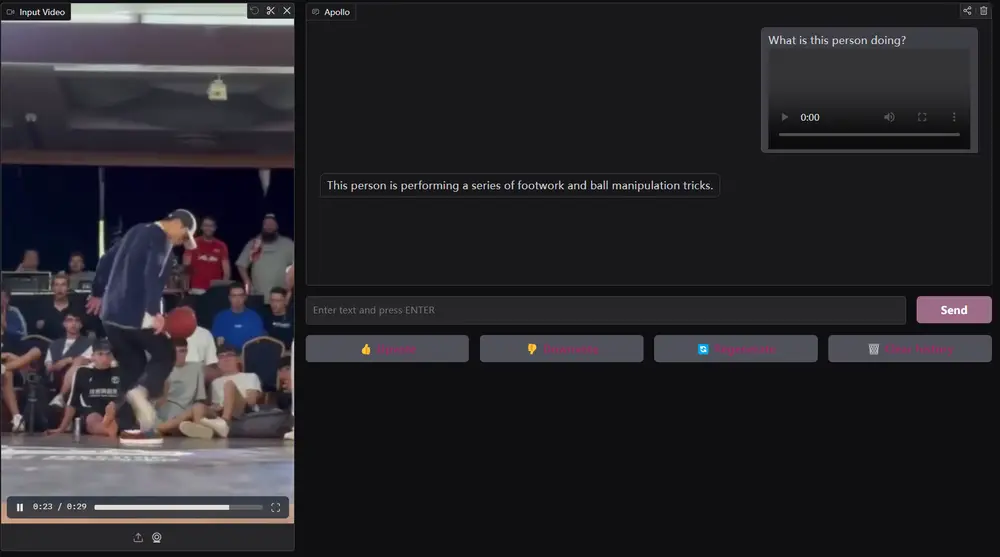
Meta推出多模态模型Apollo:擅长处理长视频,能够在长达一小时的视频中保持高效的理解能力尽管视频感知能力已经迅速集成到大型多模态模型(LMMs)中,但其驱动视频理解的基本机制仍未被充分理解。这导致了许多设计决策缺乏适当的理由或分析,尤其是在训练和评估这些模型时,高昂的计算成本和有限的开放...多模态模型# Apollo# Meta# 多模态模型12个月前03040
拟人化实时交互系统SpeechGPT 2.0-preview:支持多种音色,200毫秒延迟复旦大学自然语言处理实验室近期推出了SpeechGPT 2.0-preview,这是他们为实现情景智能而开发的第一个拟人化实时交互系统。基于百万小时级别的语音数据训练而成,这款端到端的语音大模型不仅能...多模态模型# SpeechGPT 2.0-preview# 语音模型12个月前03010