拟人化实时交互系统SpeechGPT 2.0-preview:支持多种音色,200毫秒延迟复旦大学自然语言处理实验室近期推出了SpeechGPT 2.0-preview,这是他们为实现情景智能而开发的第一个拟人化实时交互系统。基于百万小时级别的语音数据训练而成,这款端到端的语音大模型不仅能...多模态模型# SpeechGPT 2.0-preview# 语音模型12个月前03010
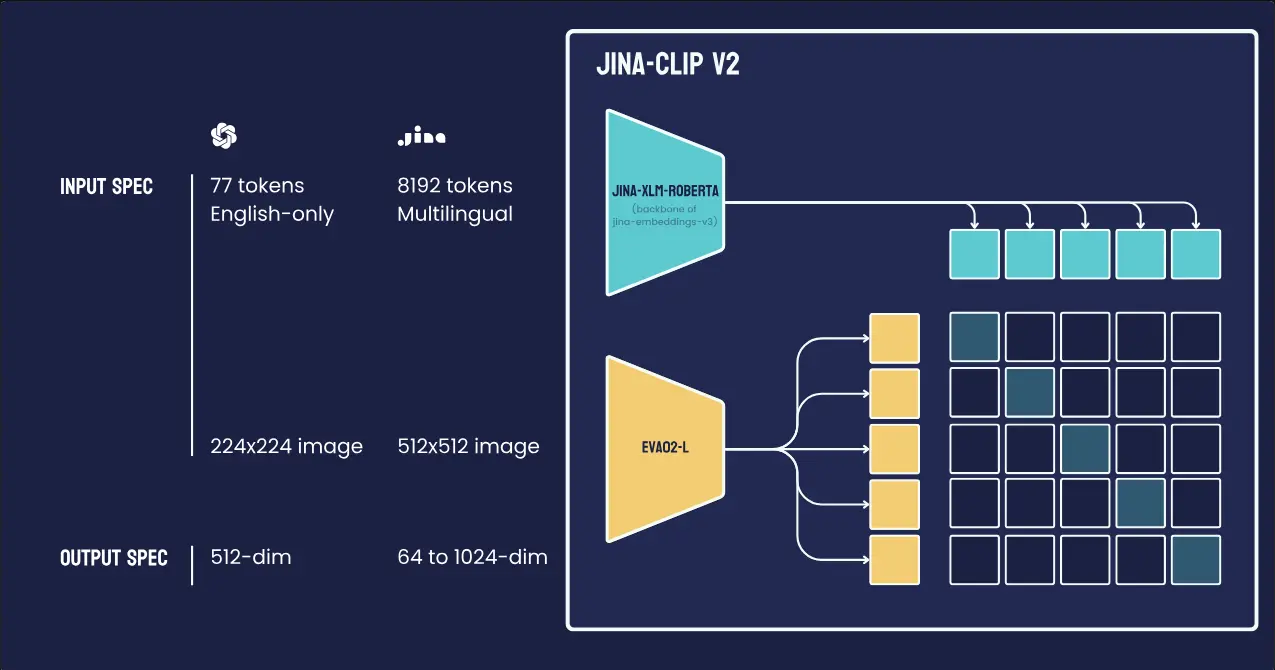
Jina CLIP v2:用于文本和图像的多语言多模态嵌入在互联互通的世界中,跨多种语言和媒介的有效沟通变得越来越重要。多模态AI在结合图像和文本以实现不同语言的无缝检索和理解方面面临着诸多挑战。现有的模型在英语中表现良好,但在其他语言中则表现不佳。此外,同...多模态模型# Jina CLIP v2# 多语言多模态嵌入12个月前03010
Jina AI推出文本嵌入模型Jina Embeddings v4:多模态多语言检索的通用嵌入模型Jina AI正式发布 jina-embeddings-v4 —— 一款全新的38亿参数通用嵌入模型,支持文本与图像输入,适用于多种检索任务。该模型在多个基准测试中表现优异,特别是在处理表格、图表等视...多模态模型# Jina AI# Jina Embeddings v4# 文本嵌入模型7个月前03000
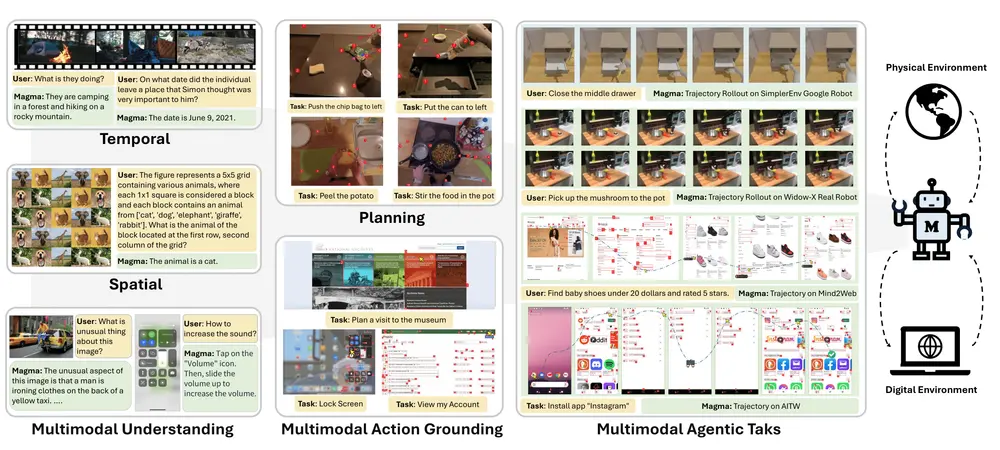
微软研究院推出的多模态 AI 代理基础模型MagmaMagma 是由微软研究院推出的一款面向多模态AI代理的基础模型,为一系列智能任务提供强大的支持。它不仅具备视觉-语言(VL)模型的理解能力(即语言智能),还拥有在视觉空间世界中规划和执行动作的能力...多模态模型# Magma# 多模态# 微软研究院11个月前03000
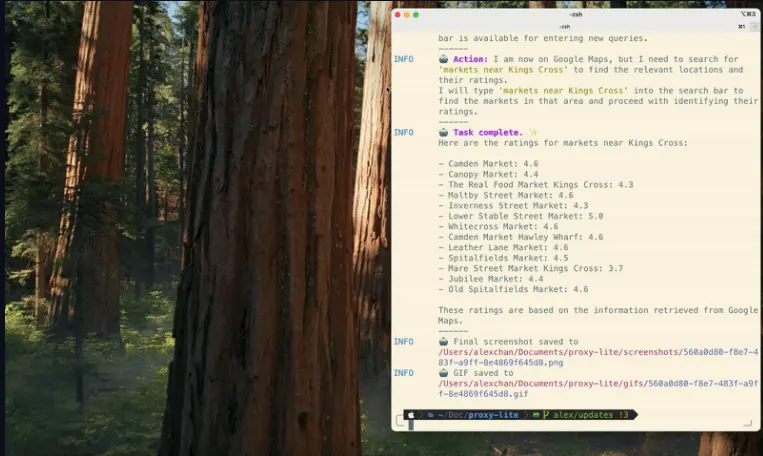
Convergence 发布基于视觉语言模型(VLM)的迷你开源模型 Proxy Lite在数字化时代,自动化与 Web 内容交互的需求日益增长。然而,现有的解决方案往往面临资源密集型、任务特定化以及缺乏透明性等问题。这些问题限制了它们的广泛适用性和社区参与度。 GitHub:https...多模态模型# Convergence# Proxy Lite# 视觉语言模型11个月前02970
多模态大语言模型Lyra:专注于增强多模态能力,特别是高级长语音理解、声音理解、跨模态效率和无缝语音交互随着多模态大语言模型(MLLMs)的发展,扩展到单一领域之外的能力对于满足更通用和高效AI的需求至关重要。然而,之前的全模态模型在语音处理方面存在不足,忽视了其与视觉、文本等其他模态的深度整合。为了解...多模态模型# Lyra# 多模态大语言模型12个月前02970
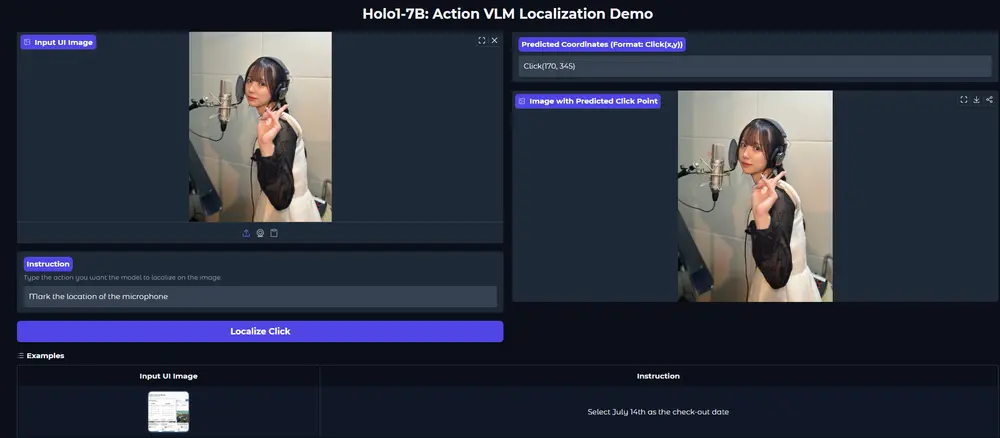
Holo1:HCompany开源高性能视觉-语言模型,赋能Surfer-H代理实现精准网页交互Holo1 是由 HCompany 开发的一款专为网络代理系统设计的 动作视觉-语言模型(VLM),作为 Surfer-H 网络代理的核心组件之一,它具备像人类用户一样与网页界面交互的能力。 模型:h...多模态模型# Holo1# 视觉-语言模型8个月前02960
多模态大语言模型InternVL 2.5:处理和理解来自多种模态(如文本、图像和视频)的信息InternVL 2.5 是由上海人工智能实验室、商汤科技研究院、清华大学、南京大学、复旦大学、香港中文大学和上海交通大学等多家机构联合推出的一款先进的多模态大语言模型(MLLM)。该模型基于此前发布...多模态模型# InternVL 2.5# 多模态大语言模型12个月前02930
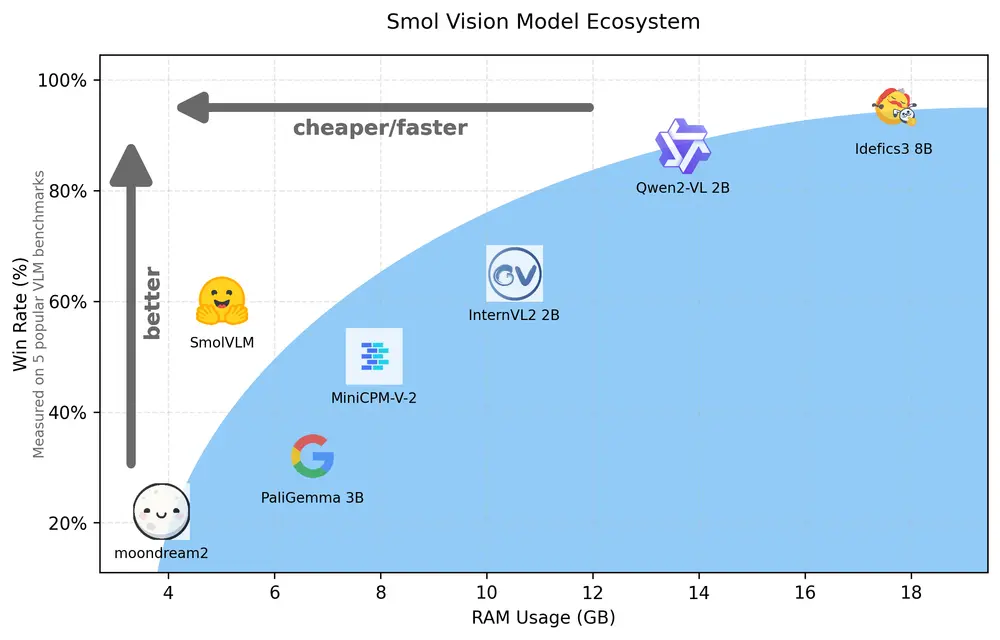
Hugging Face发布一个用于设备上推理的2B参数小型多模态模型SmolVLM近年来,随着机器学习技术的飞速发展,视觉-语言模型(VLM)的需求不断增加。这些模型能够处理图像和文本的组合任务,如图像描述、问答和故事生成等。然而,大多数现有的VLM需要大量的计算资源和内存,这限制...多模态模型# Hugging Face# SmolVLM# 多模态模型12个月前02910
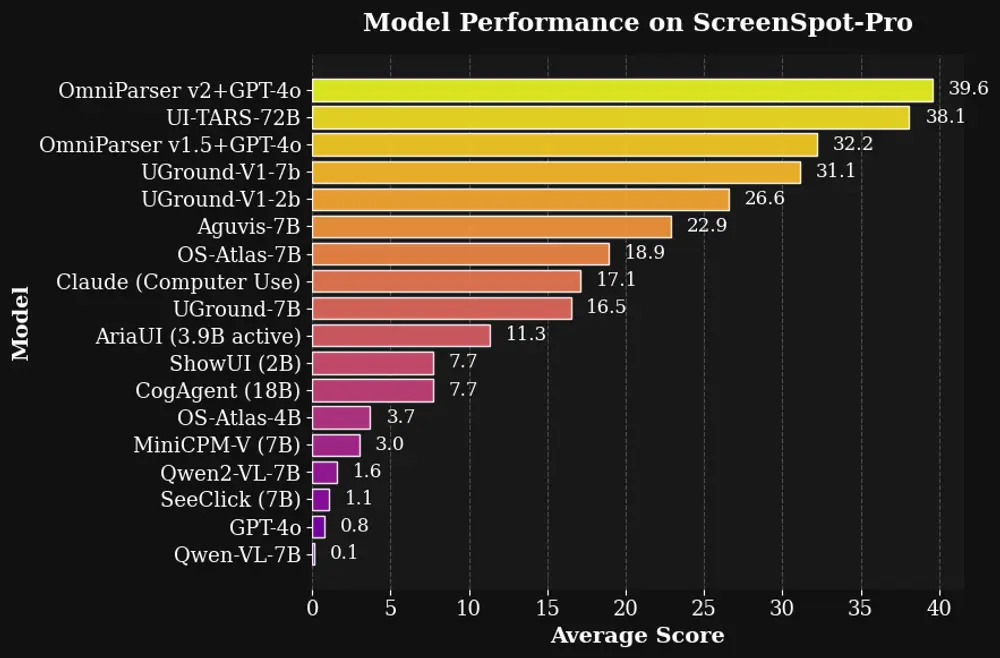
让大语言模型“看懂”图形界面!微软推出 OmniParser V2.0:将大语言模型转化为 GUI 交互智能体微软的 OmniParser 发布了 V2 更新,这一版本的核心目标是将任何大语言模型(LLM)转化为能够理解和交互图形用户界面(GUI)的智能体。相比前一代,OmniParser V2 在检测更小可...多模态模型# OmniParser V2.0# 微软# 智能体12个月前02880
深度求索开源多模态理解与生成模型 Janus-Pro,已释出两个版本Janus-Pro-7B和Janus-Pro-1B深度求索(DeepSeek-AI)在DeepSeek-R1爆火后,又在今天释出了多模态理解与生成模型 Janus-Pro,它是之前工作 Janus 的升级版本,目前释出了两个版本Janus-Pro-7...多模态模型# Janus-Pro# Janus-Pro-1B# Janus-Pro-7B12个月前02880
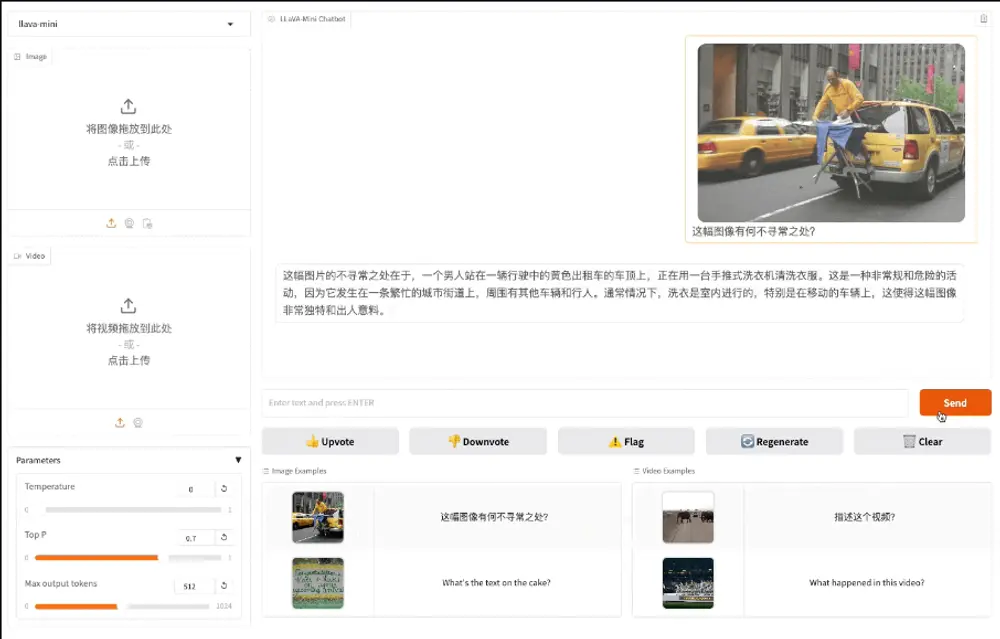
高效大型多模态模型LLaVA-Mini:通过最小化视觉令牌(vision tokens)的数量来提高模型的计算效率和响应速度中国科学院计算技术研究所智能信息处理重点实验室(ICT/CAS)、中国科学院人工智能安全重点实验室和中国科学院大学的研究人员推出高效大型多模态模型LLaVA-Mini,旨在通过最小化视觉令牌(visi...多模态模型# LLaVA-Mini# 多模态模型12个月前02870