昆仑万维天工项目组推出多模态模型Skywork UniPic:能够统一处理图像理解、文本到图像生成和图像编辑等多种任务昆仑万维天工项目组推出多模态模型Skywork UniPic,它是一个参数量为15亿的自回归模型,能够统一处理图像理解、文本到图像生成和图像编辑等多种任务,而无需针对每个任务单独适配或连接模块。 Gi...多模态模型# Skywork UniPic# 多模态模型6个月前02850
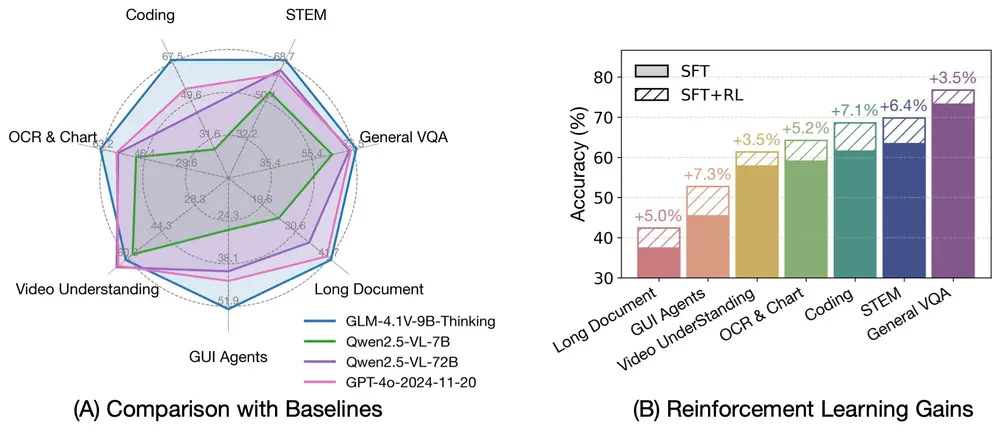
智谱AI联合清华推出新一代视觉语言推理模型开源 GLM-4.1V-9B-Thinking随着智能任务日益复杂,视觉语言大模型(VLM)正从基础的多模态感知迈向更高层次的推理能力提升。为了应对这一趋势,智谱AI 与清华大学联合推出了新一代 VLM 开源模型 —— GLM-4.1V-9B-T...多模态模型# GLM-4.1V-9B-Thinking# 智谱AI7个月前02850
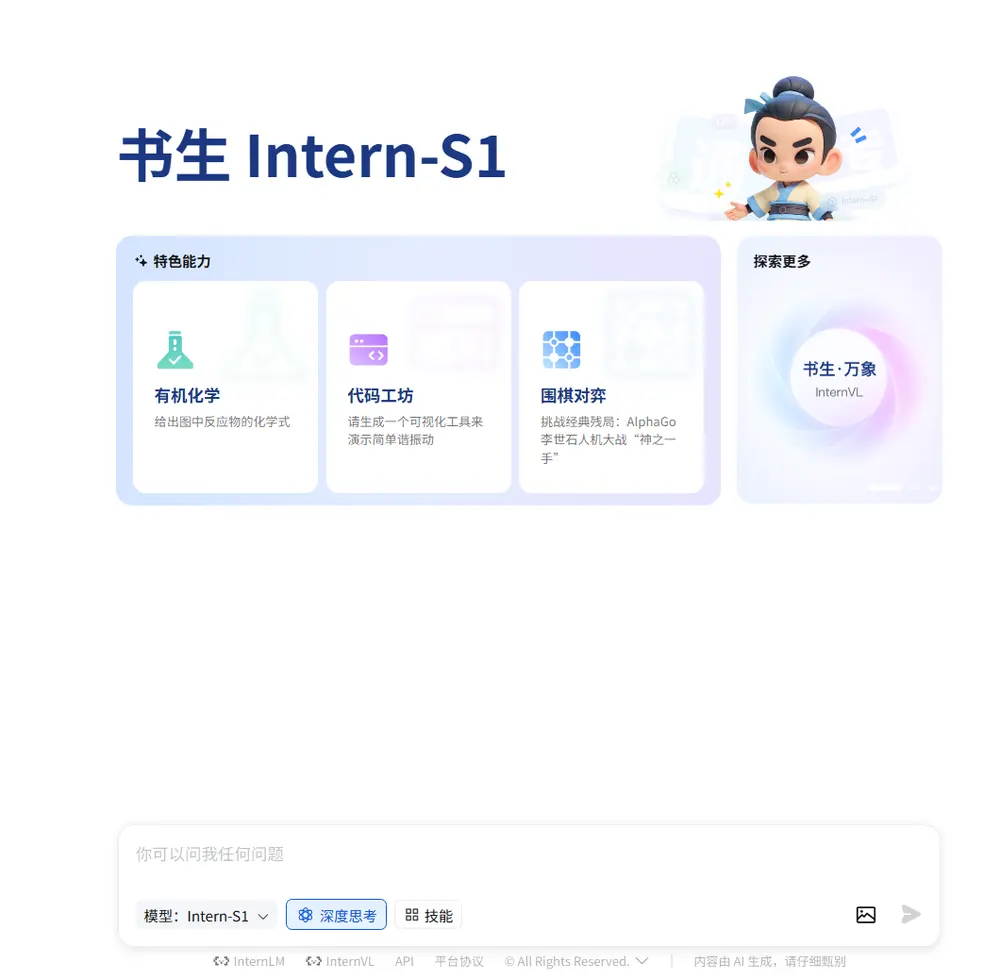
上海AI实验室发布书生 Intern-S1:专为科研打造的多模态AI助手上海AI实验室正式推出 Intern-S1 —— 一款具备强大科学理解能力的开源多模态推理模型。它不仅在通用任务上表现卓越,更在化学、生物、数学、物理等多个科学领域达到最先进的性能水平,部分指标甚至超...多模态模型# Intern-S1# 上海AI实验室# 书生5个月前02840
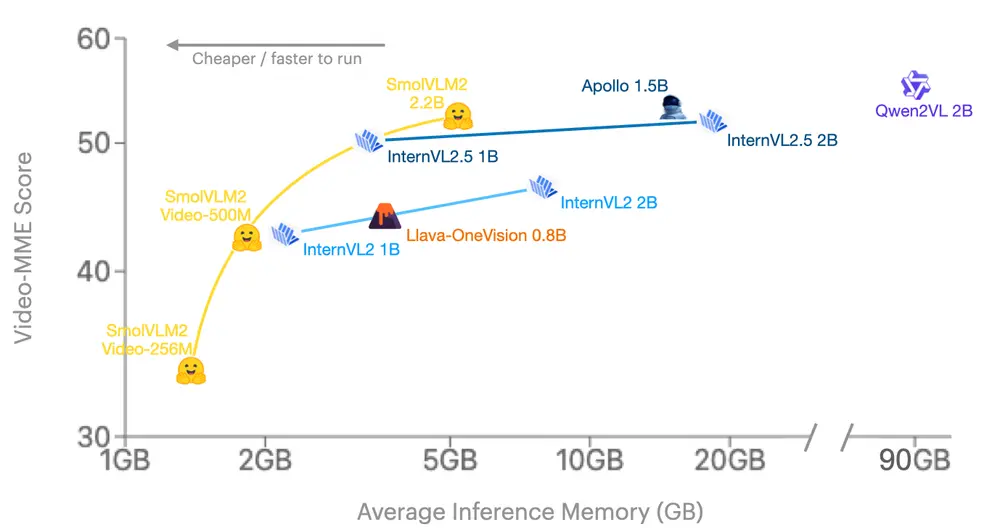
Hugging Face 发布轻量级多模态模型SmolVLM2:专为视频内容分析而设计Hugging Face 最新发布了一款轻量级多模态模型SmolVLM2,专为视频内容分析而设计。该模型以高效性和适应性为核心目标,旨在将视频理解能力扩展到从手机到服务器的各种设备上。SmolVLM2...多模态模型# Hugging Face# SmolVLM2# 多模态模型11个月前02840
英伟达开源了世界上第一个人形机器人基础模型 GR00T N1,加速通用人形机器人开发人形机器人旨在适应人类工作空间,处理重复性或高要求任务。然而,为现实世界的任务和不可预测环境开发通用人形机器人具有挑战性。每项任务通常需要专用的AI模型。从头开始为每个新任务和环境训练这些模型是一个繁...多模态模型# GR00T N1# 人形机器人基础模型# 英伟达11个月前02830
EmoNet:迈向真正“有情感”的AI,LAION开源新一代情感智能模型人工智能的发展正进入一个全新的阶段:从理解语言到理解情绪。尽管AI在语言处理、推理能力等方面取得了显著进展,但在情感智能(Affective Intelligence)这一维度上,仍然存在巨大空白。 ...多模态模型# EmoNet# LAION AI# 情感智能模型7个月前02820
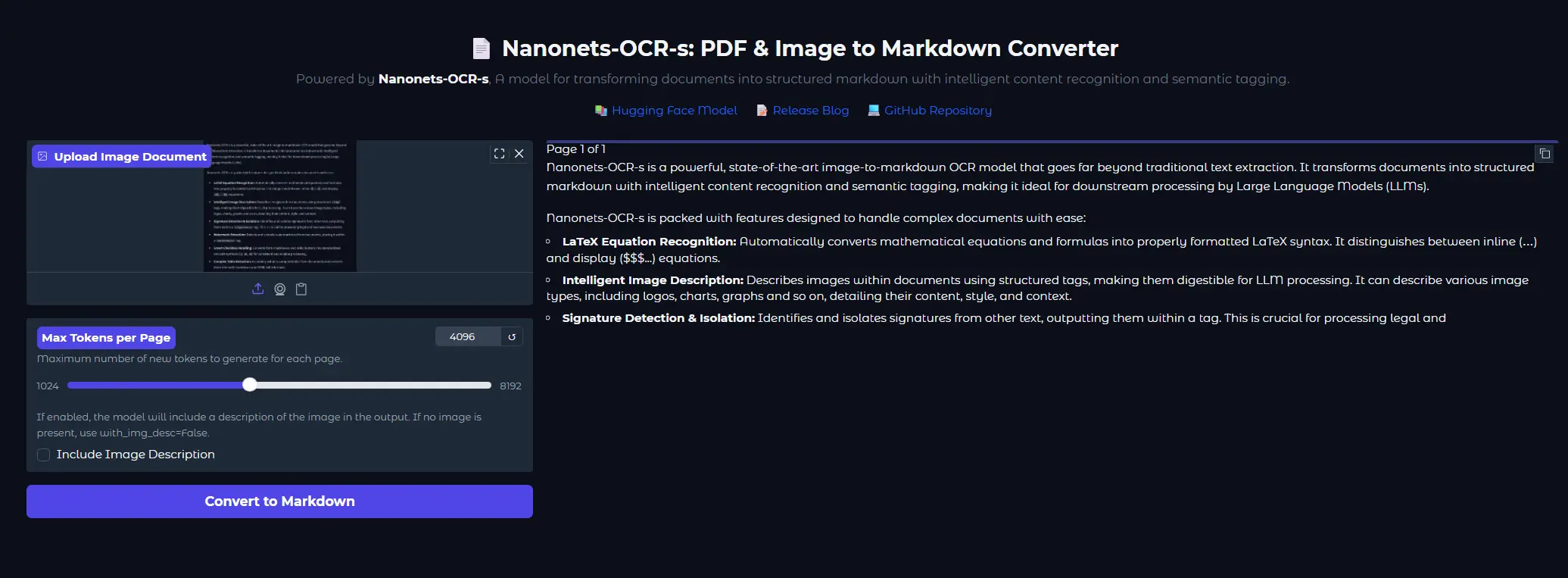
Nanonets 推出 Nanonets-OCR-s:首个面向 LLM 的结构化 OCR 模型近日,Nanonets 宣布推出一款全新的 OCR 模型 Nanonets-OCR-s ——这是一款专为大语言模型(LLMs)设计的图像转 Markdown 工具,具备强大的文档理解与结构化输出能力...多模态模型# Nanonets-OCR-s# OCR 模型8个月前02790
阿里巴巴发布 QVQ-Max:能看、能理解、能思考的视觉推理模型阿里巴巴推出一款名为 QVQ-Max 的全新视觉推理模型,这是其 Qwen模型系列中的最新成员。QVQ-Max 的独特之处在于它能够理解照片和视频的内容,并对这些信息进行分析和推理,从而提供解决方案...多模态模型# QVQ-Max# 视觉推理模型# 阿里巴巴10个月前02780
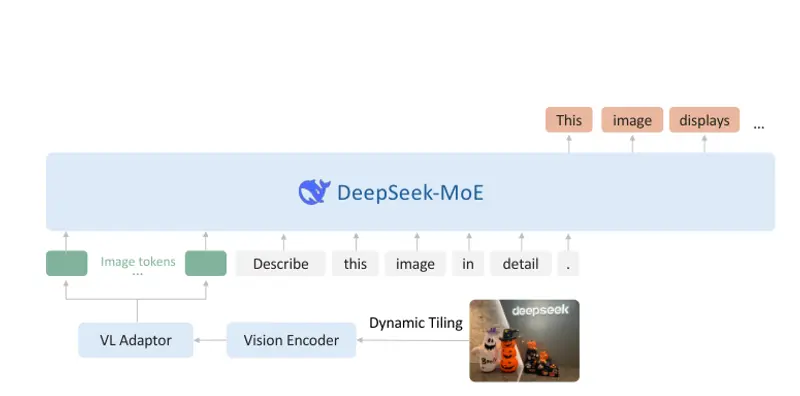
深度求索推出开源视觉模型DeepSeek-VL2 :支持动态分辨率、处理科研图表、解析各种梗图等DeepSeek-VL2 是由深度求索(DeepSeek-AI)推出的一系列先进混合专家(MoE, Mixture of Experts)视觉语言模型,旨在显著提升其前代产品 DeepSeek-VL ...多模态模型# DeepSeek-VL 2# 深度求索12个月前02780
百度发布 PP-OCRv5:0.07亿参数模型,挑战百亿级大模型的OCR精度在通用视觉语言模型(VLM)主导多模态任务的当下,百度飞桨团队反其道而行之,推出新一代轻量级文字识别模型 PP-OCRv5 ——一个仅含 70万参数(0.07B)的超小模型,在多项 OCR 任务中表现...多模态模型# PP-OCRv5# 百度4个月前02770
谷歌Gemini 2.0 Flash重磅升级:原生多模态生成,图像编辑进入对话时代谷歌在昨天除了发布了开源模型Gemma 3,还正式开放了Gemini 2.0 Flash的原生图像生成编辑功能,这款实验性模型凭借单模型多模态生成能力,正在重塑AI创作逻辑。相比传统需要「语言模型+扩...多模态模型# Gemini 2.0 Flash# gemini-2.0-flash-exp# Gemma 311个月前02770
英伟达推出面向文档理解的小而强视觉-语言模型 Llama Nemotron Nano VL英伟达正式发布了 Llama Nemotron Nano VL —— 一款专为高效处理复杂文档设计的轻量级视觉-语言模型(VLM)。该模型基于 Llama 3.1 架构构建,在保持高性能的同时兼顾推理...多模态模型# Llama Nemotron Nano VL# 英伟达8个月前02760